Manjaro является самой популярной операционной системой GNU/Linux. Её особенность, по сравнению с другими дистрибутивами, в простоте. В этой статье рассмотрим настройку Manjaro после установки.
За пример взята сборка Manjaro со средой рабочего стола Xfce и английским языком интерфейса.
Настройка Manjaro после установки
Шаг 1. Установка русской локализации
При первом запуске Manjaro появляется приветственное окно.
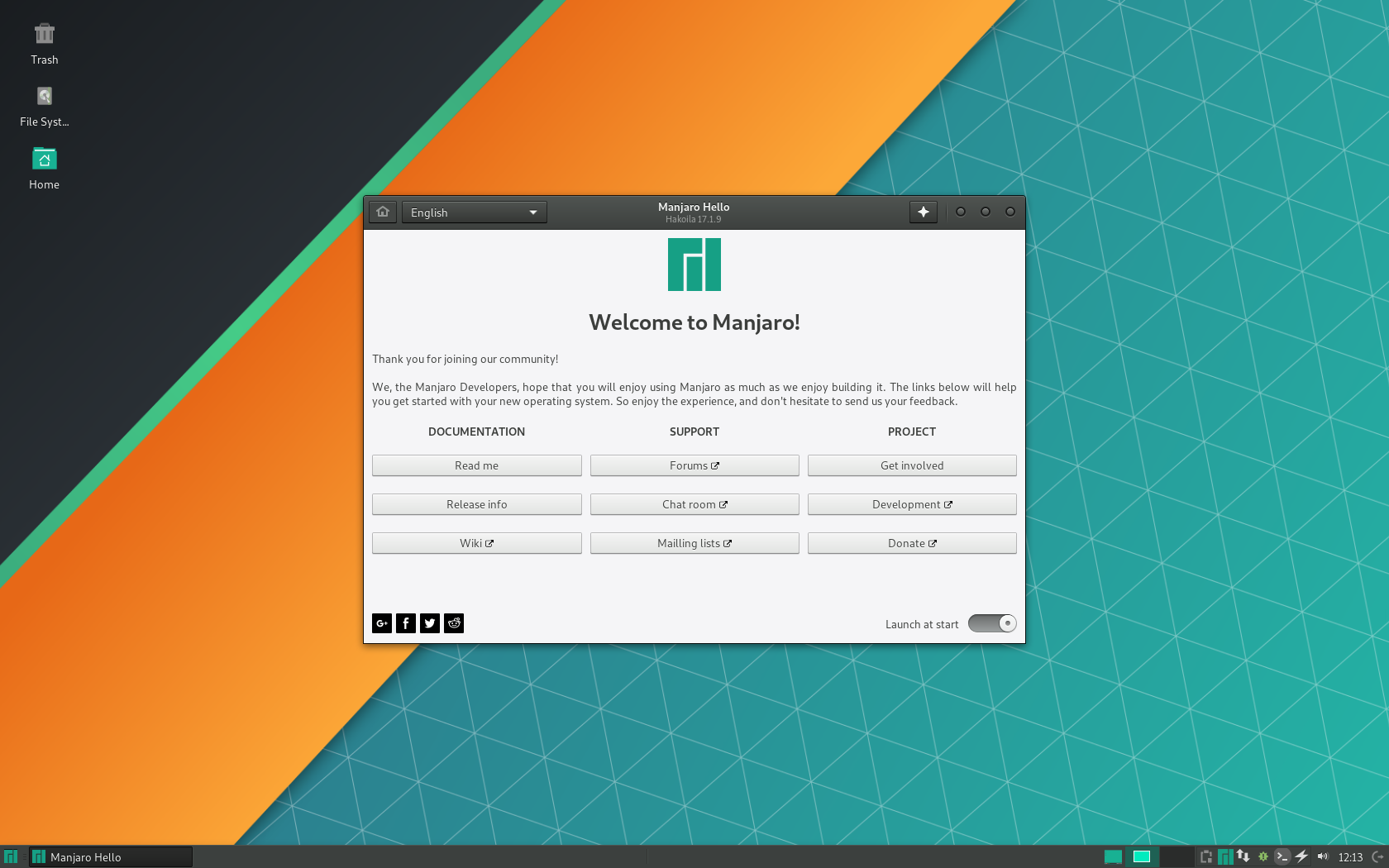
Здесь находятся несколько кнопок, связанных с документацией, поддержкой и проектом системы. Чтобы не отображать это окно при запуске в дальнейшем, переключите внизу тумблер Launch at start.
Чтобы локализировать систему на русский язык, откройте меню приложений Whisker (слева внизу) → Settings.
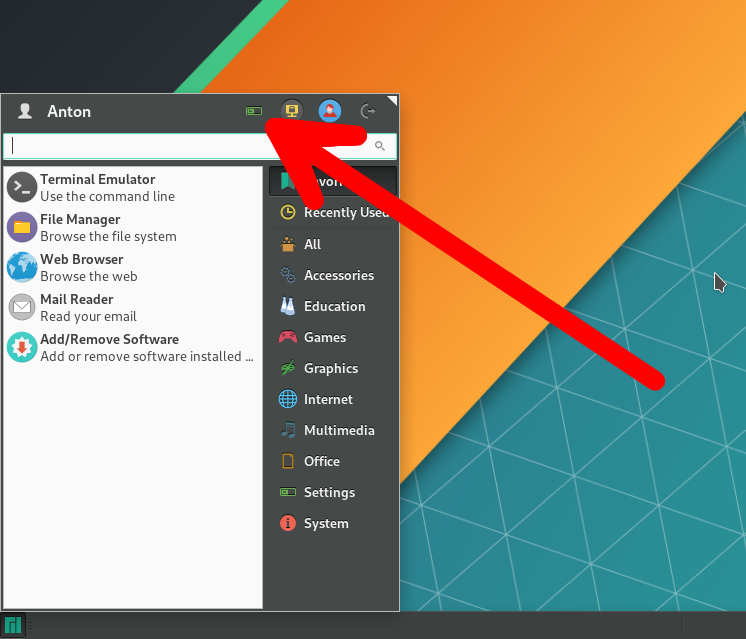
Перейдите в Manjaro Settings Manager →Locale Settings и нажмите Add, чтобы выбрать язык системы.
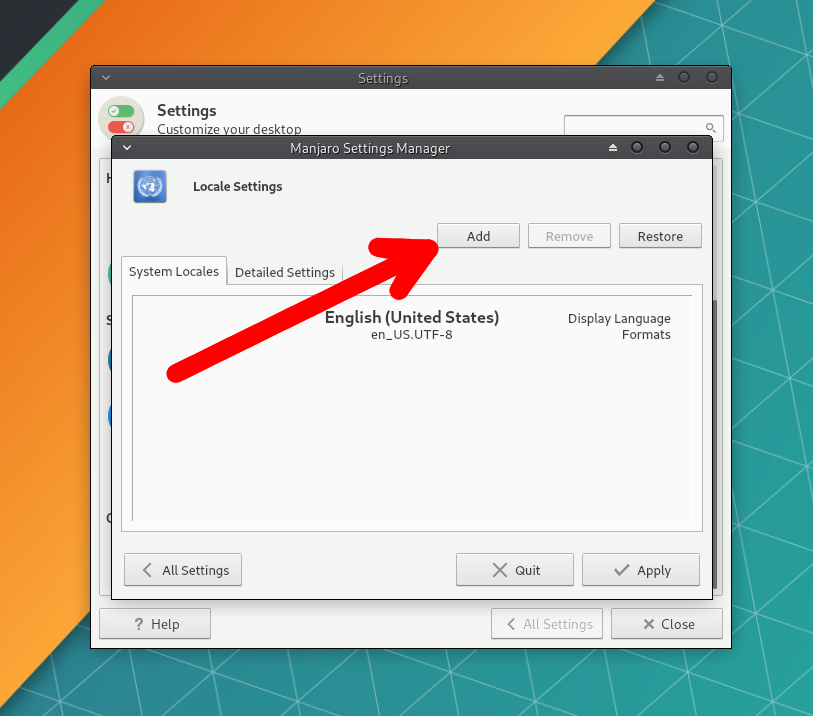
В списке выберите Русский. Справа укажите регион, для которого будет применён формат даты, времени и т.п.
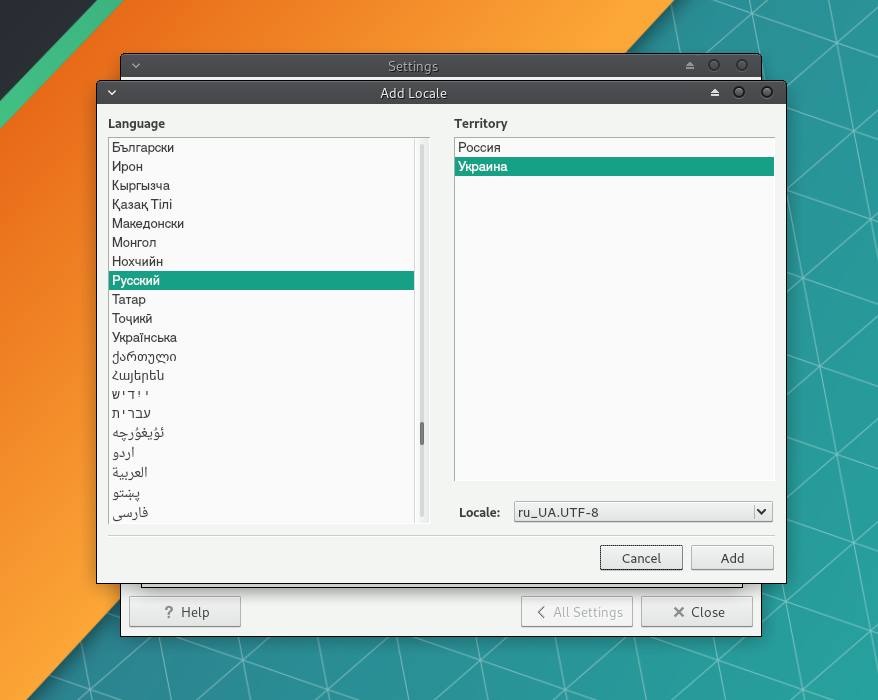
Затем нажмите правой кнопкой мыши на добавленный язык и выберите пункт Set at default display language and format.
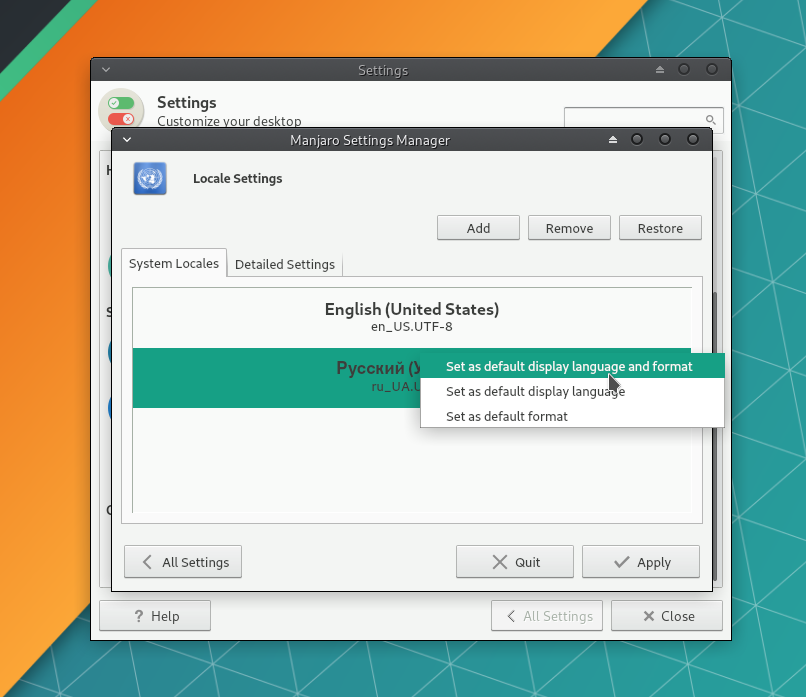
Нажмите Apply. Будет запрошен ввод пароля, который вы устанавливали для пользователя.
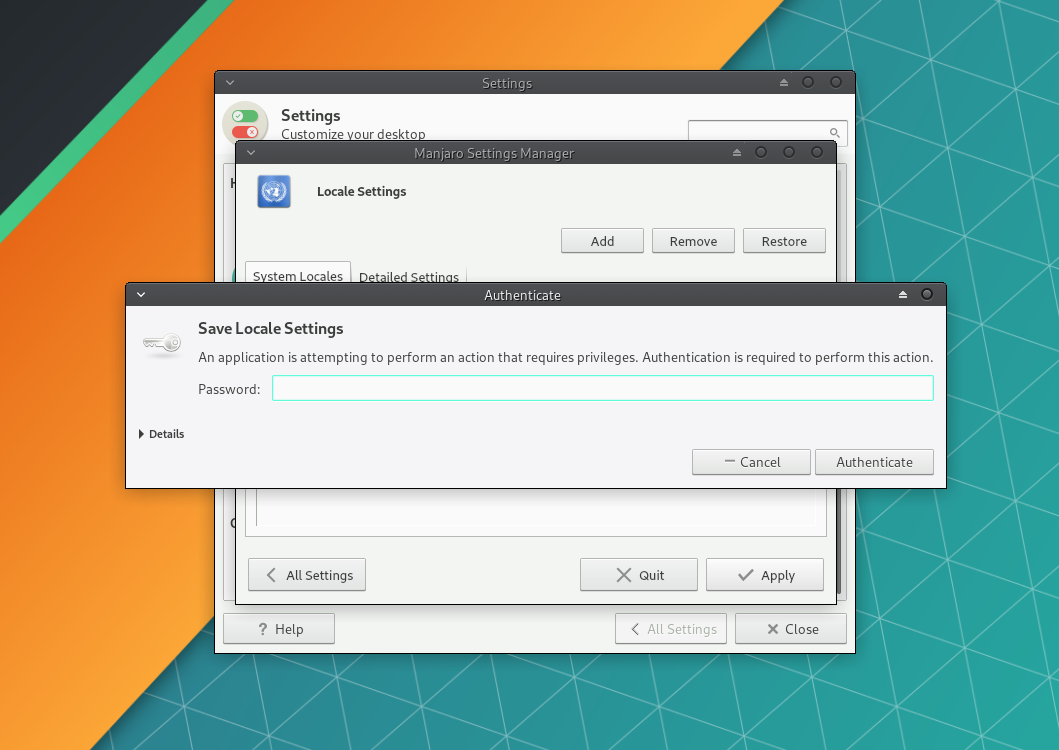
Перезагрузите компьютер. После этого система будет локализирована на русский язык.
Для того, чтобы локализировать установленные приложения, в Manjaro Settings Manager перейдите в Языковые пакеты.
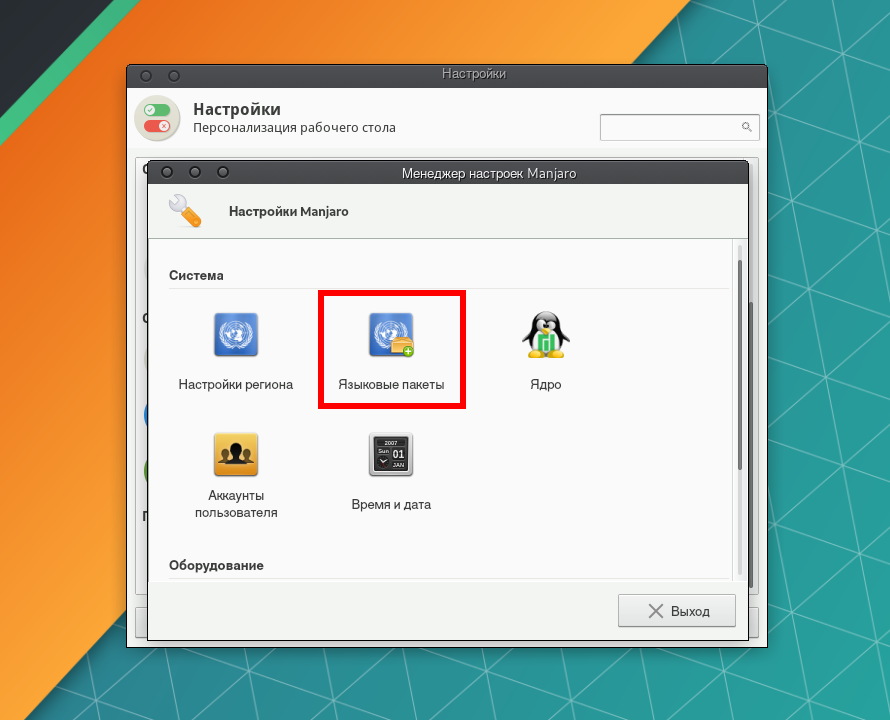
Чтобы установить все доступные языковые пакеты, нажмите кнопку Установка пакетов. При необходимости подтвердите решение вводом пароля.
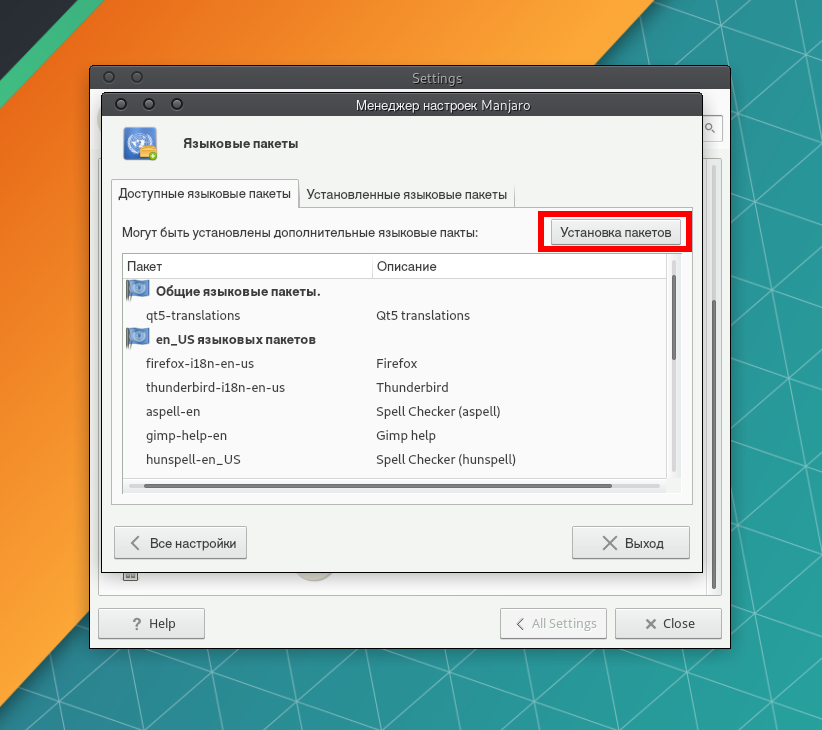
Теперь программы будут запускаться с русским языком интерфейса.
Шаг 2. Добавление русской раскладки
По умолчанию установлена только та языковая раскладка клавиатуры, которая использовалась при инсталляции системы. В нашем случае, это английская. Для добавления русской раскладки перейдите в Диспетчер настроек → Клавиатура.
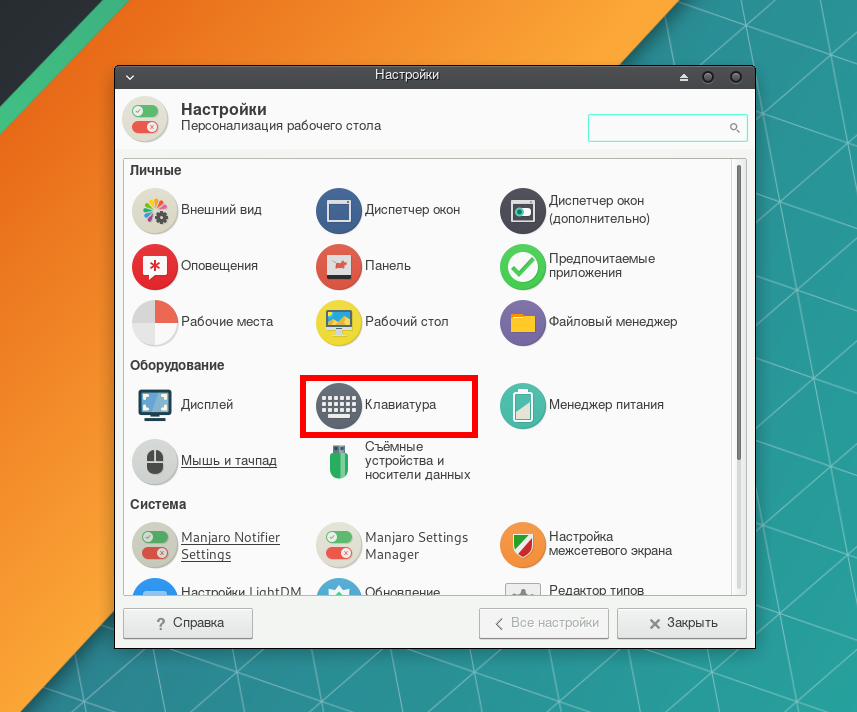
Выберите вкладку Раскладка и нажмите на кнопку Добавить.
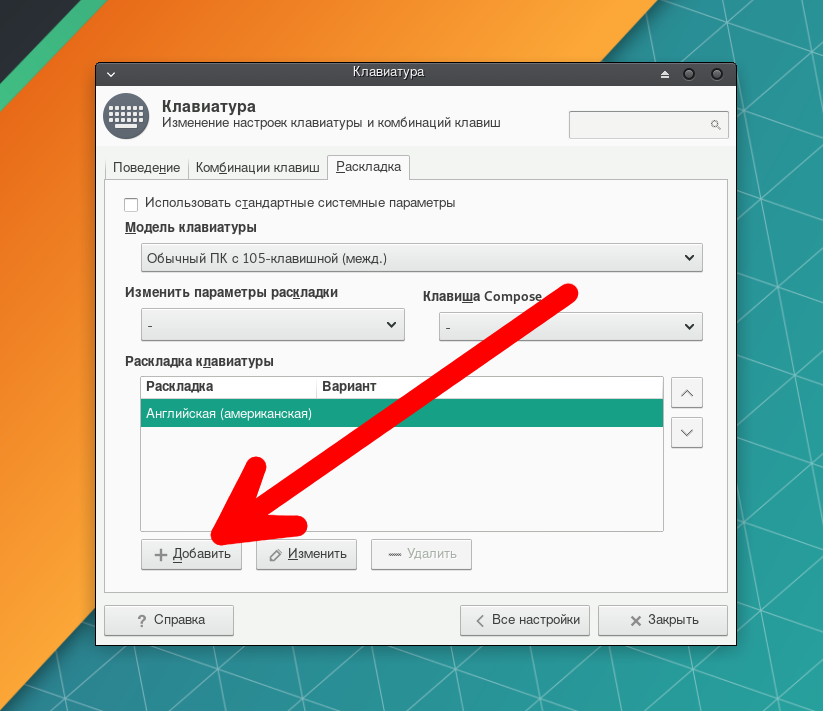
В списке раскладок укажите Русская и нажмите OK.
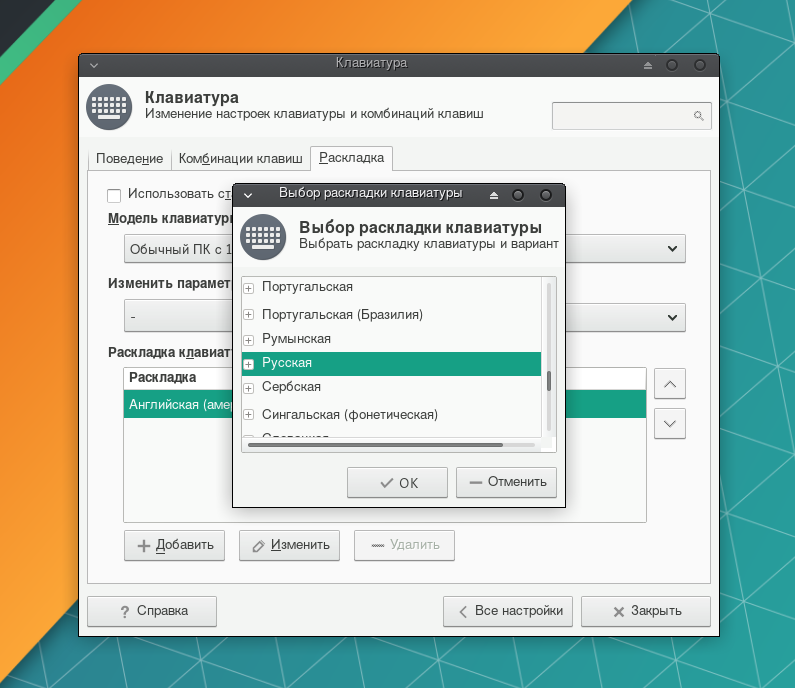
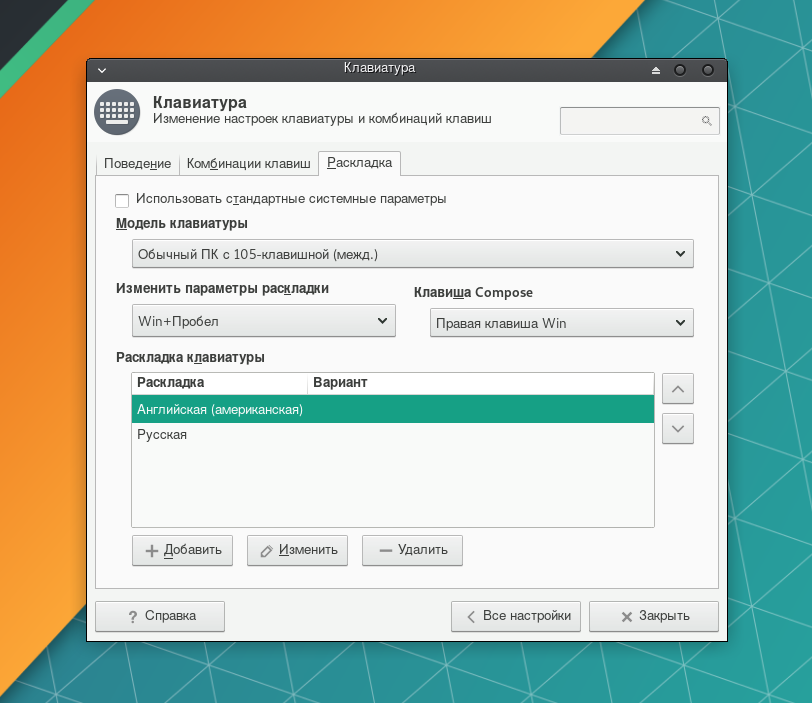
В выпадающем списке поля Изменить параметры раскладки укажите метод переключения между раскладками. При желании укажите клавишу для поля Compose, с помощью которой можно добавлять символы, отсутствующие на клавиатуре (аналог работы Alt + цифры в Windows).
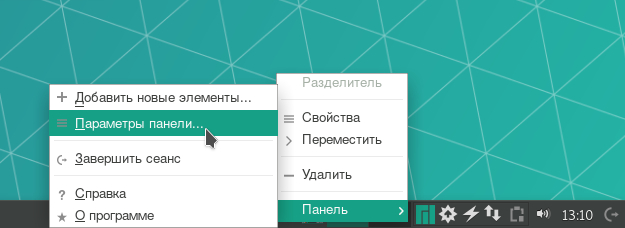
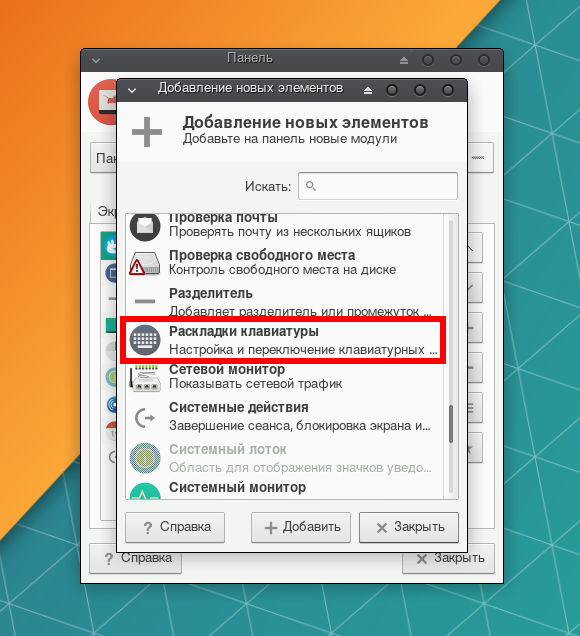
Чтобы добавить кнопку управления раскладкой на панель Xfce, щёлкните по ней правой кнопкой мыши и выберите Панель → Параметры панели....
На вкладке Элементы нажмите кнопку со значком +.
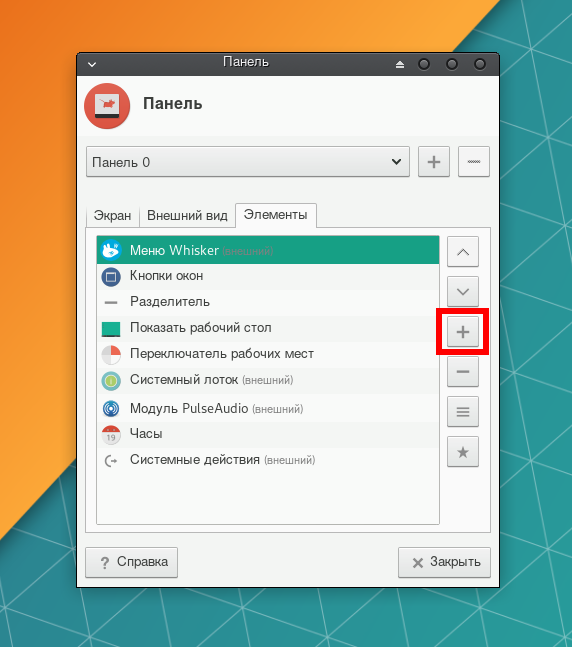
В списке элементов выберите Раскладки клавиатуры и нажмите Добавить.
После этого на панели появится значок с флагом, отображающим текущую раскладку.
Шаг 3. Выбор серверов для обновлений
В Manjaro можно выбрать зеркала обновлений, то есть страны, с серверов которых будут обновляться программы или вся система. Главным критерием при выборе зеркала является скорость задержки ответа от сервера, которая должна быть минимальной. Отобрать наиболее быстрые из них поможет утилита pacman-mirrors.
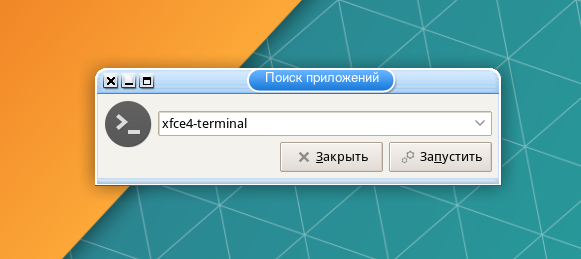
Откройте терминал: меню Whisker → Система → Терминал Xfce или нажмите Alt + F2 и введите xfce4-terminal → Запустить.
Войдите от имени суперпользователя и подтвердите действие паролем:
sudo su
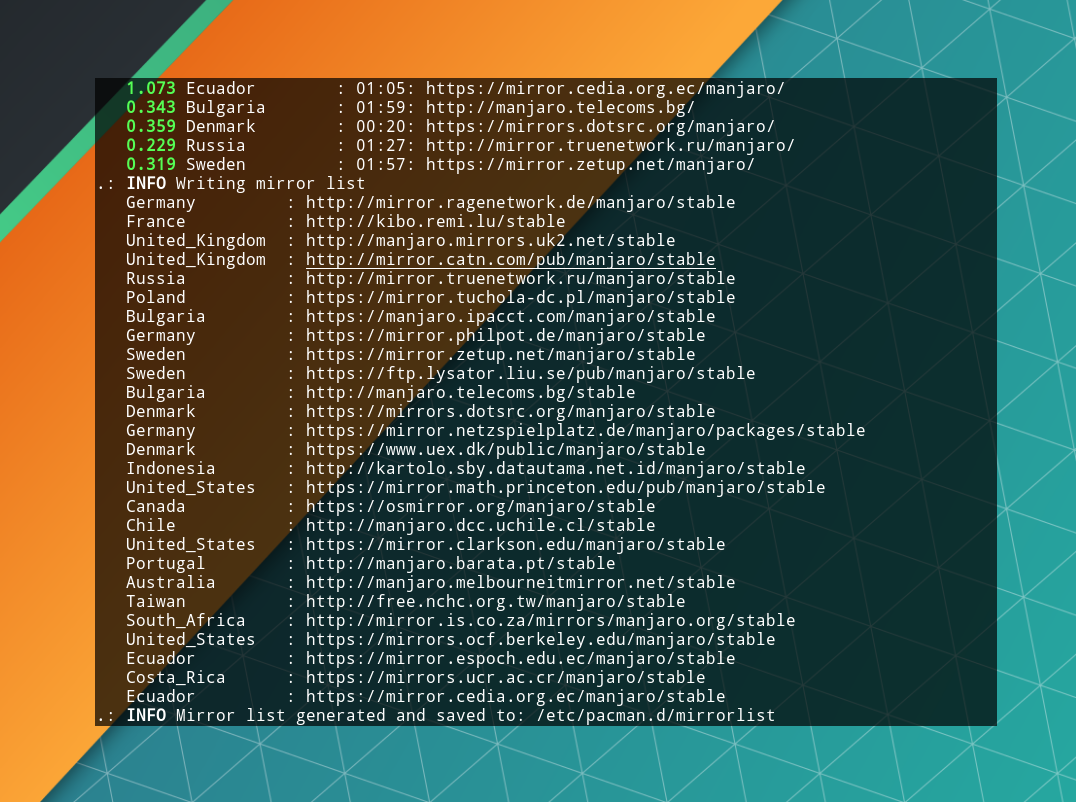
Для быстрого выбора зеркал и сортировки их по скорости от лучшей к худшей, используйте команду:
pacman-mirrors --fasttrack
После показа выбранных серверов утилита запишет их в файл /etc/pacman.d/mirrorlist, оповестив об этом в конце процедуры.
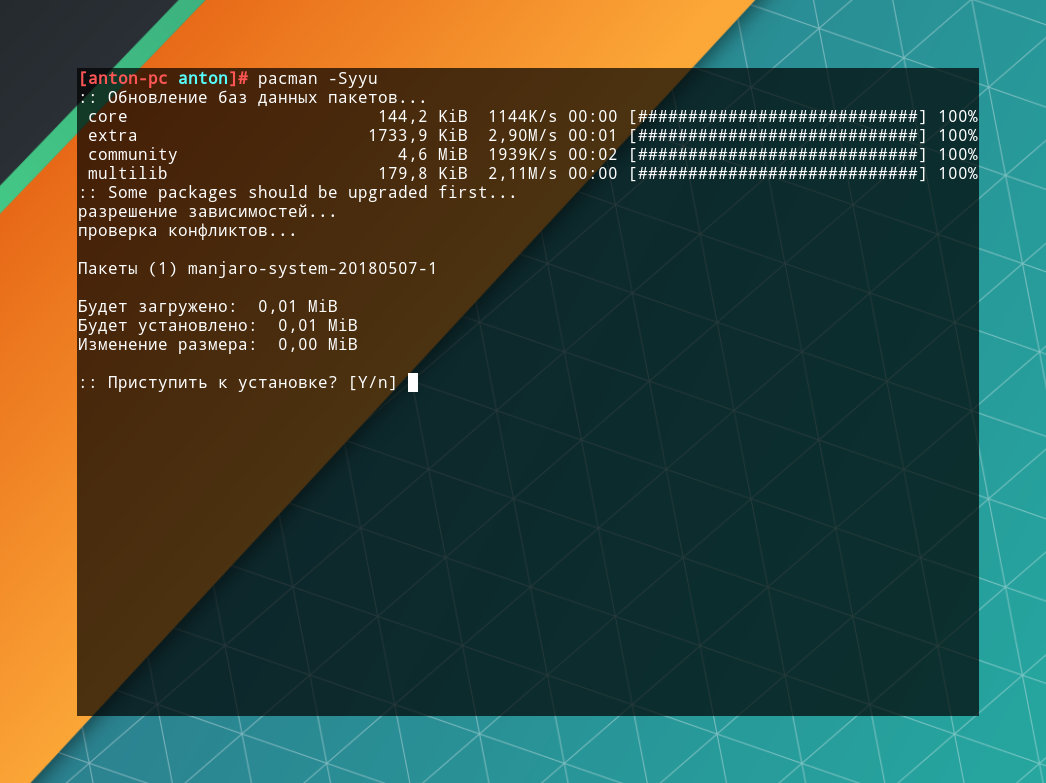
После этого обновите репозитории:
pacman -Syyu
Если будут доступны обновления ПО, подтвердите их нажатием Enter при соответствующем запросе.
Шаг 4. Подключение AUR
AUR - пользовательский репозиторий (хранилище ПО) ОС Arch, который доступен для всех Arch-подобных систем. В нём доступны различные программы, которых нет в официальных репозиториях (например Skype, Discord и другие).
Чтобы включить AUR, откройте Установка и удаление программ.
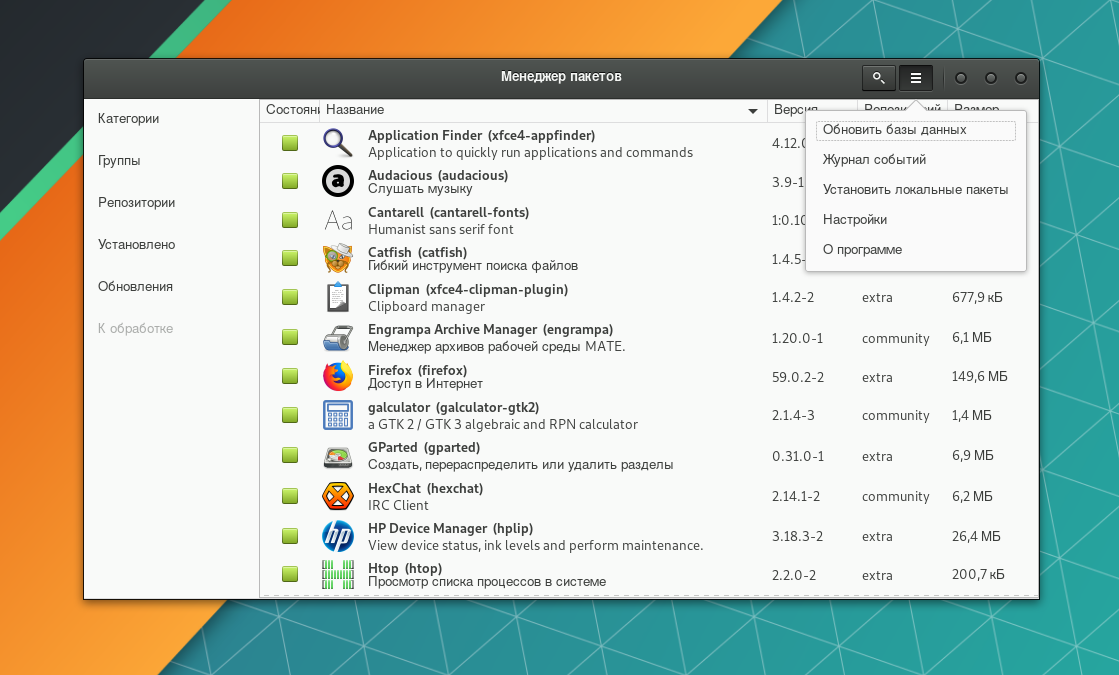
Нажмите на иконку "гамбургер" и войдите в Настройки.
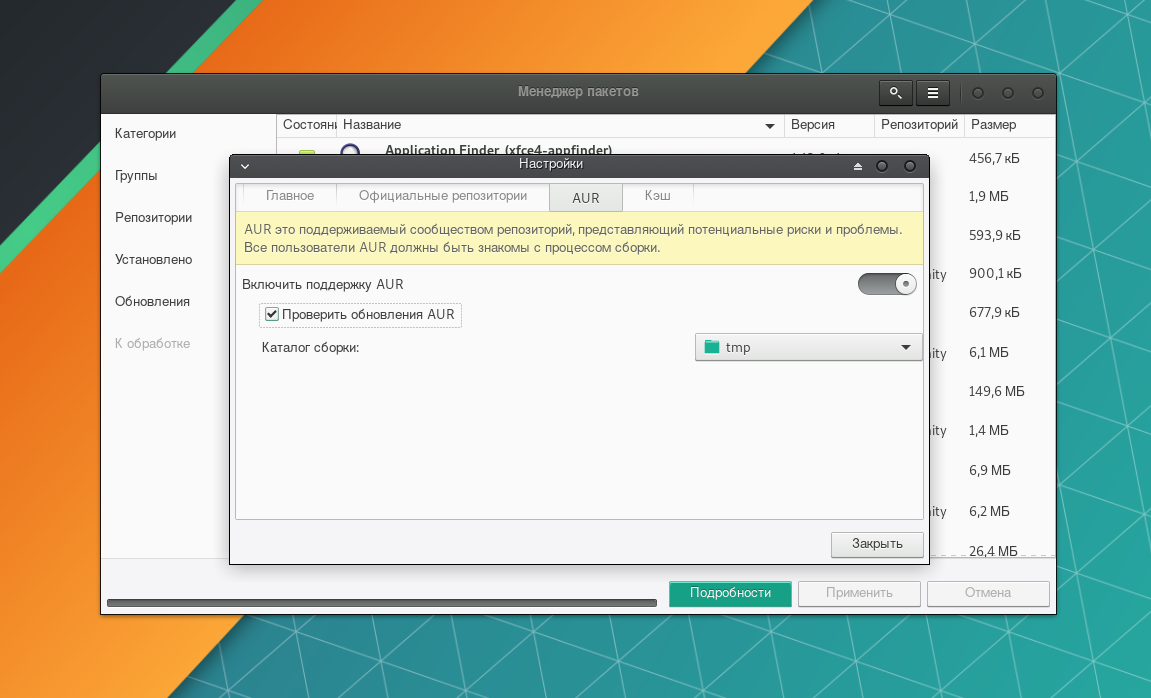
На вкладке AUR включите его поддержку соответствующим тумблером.
Подробнее об инсталляции ПО рассказано в статье «Установка программ в Manjaro».
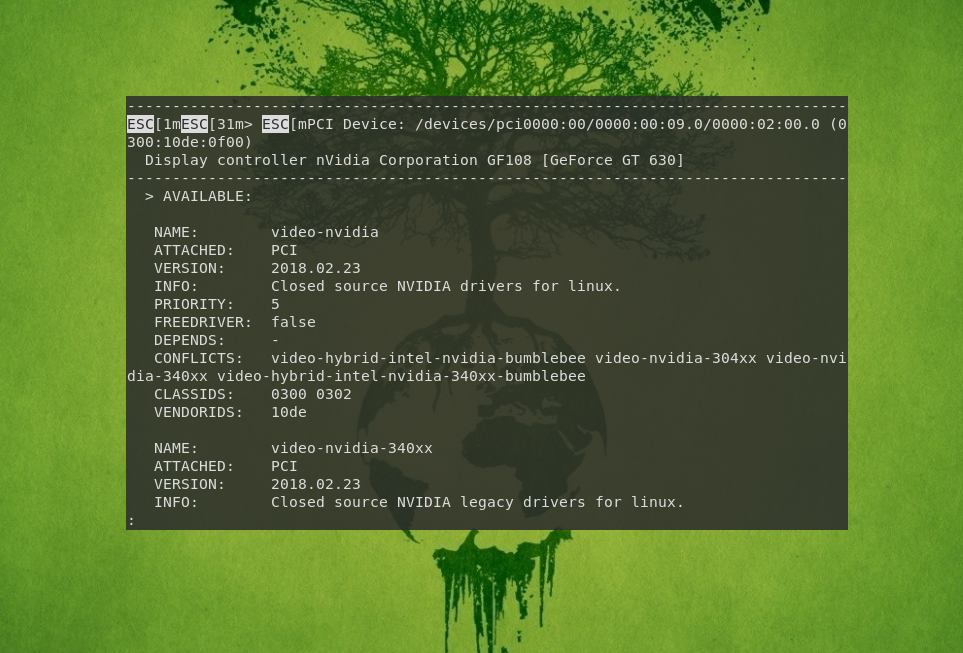
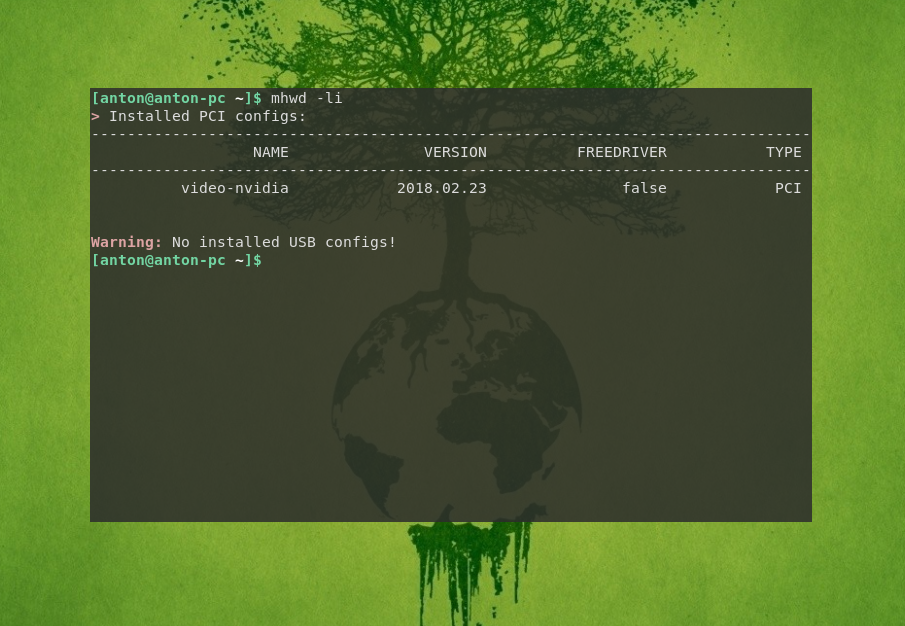
Шаг 5. Установка драйвера видеокарты
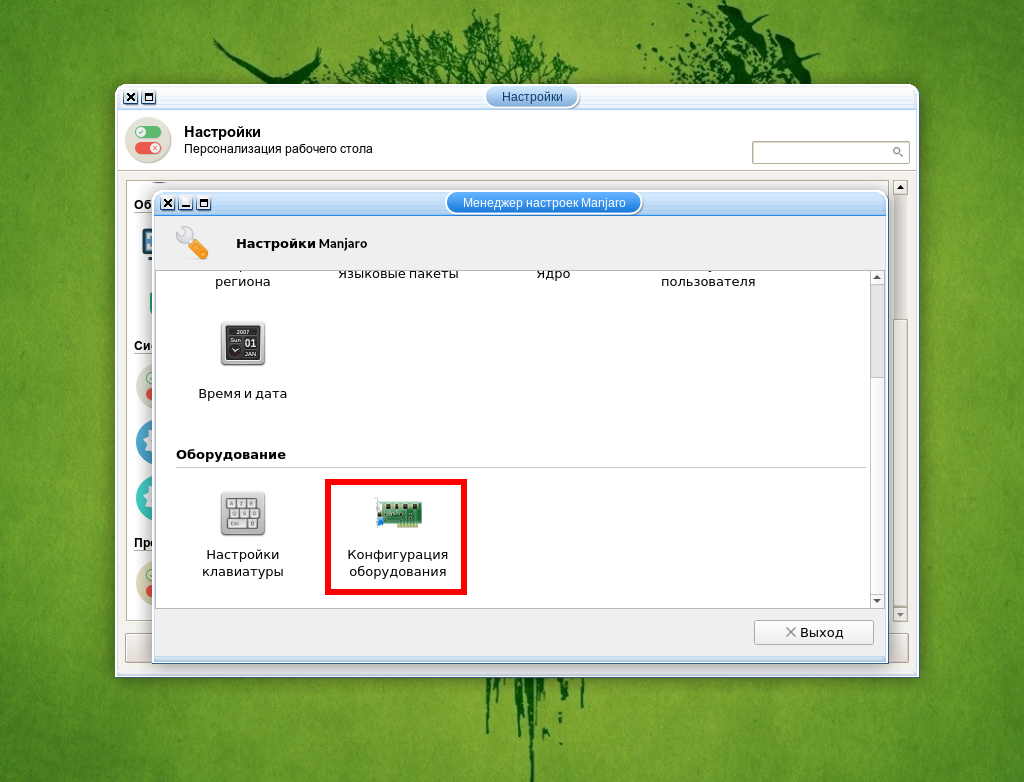
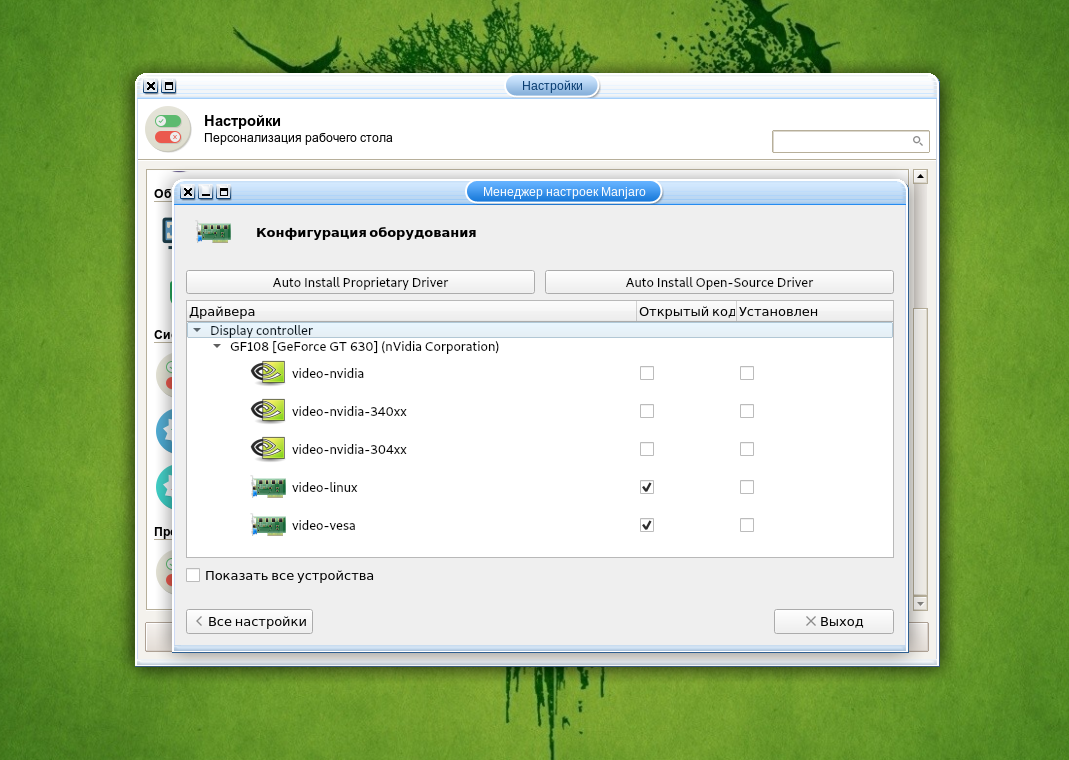
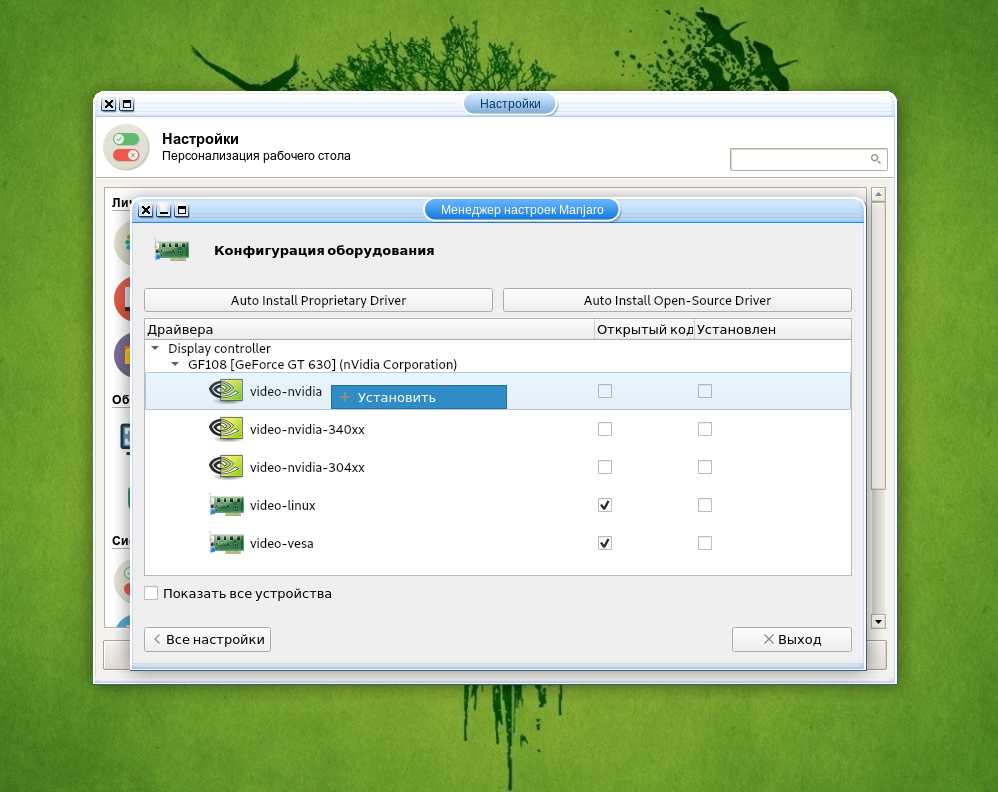
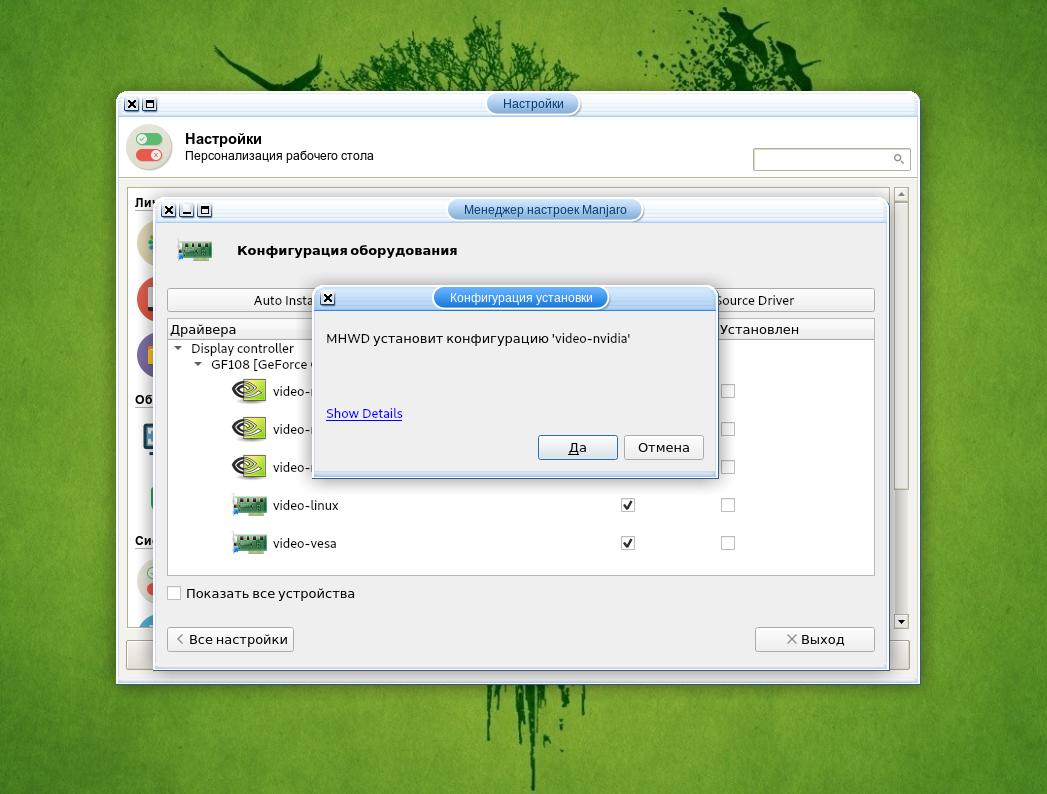
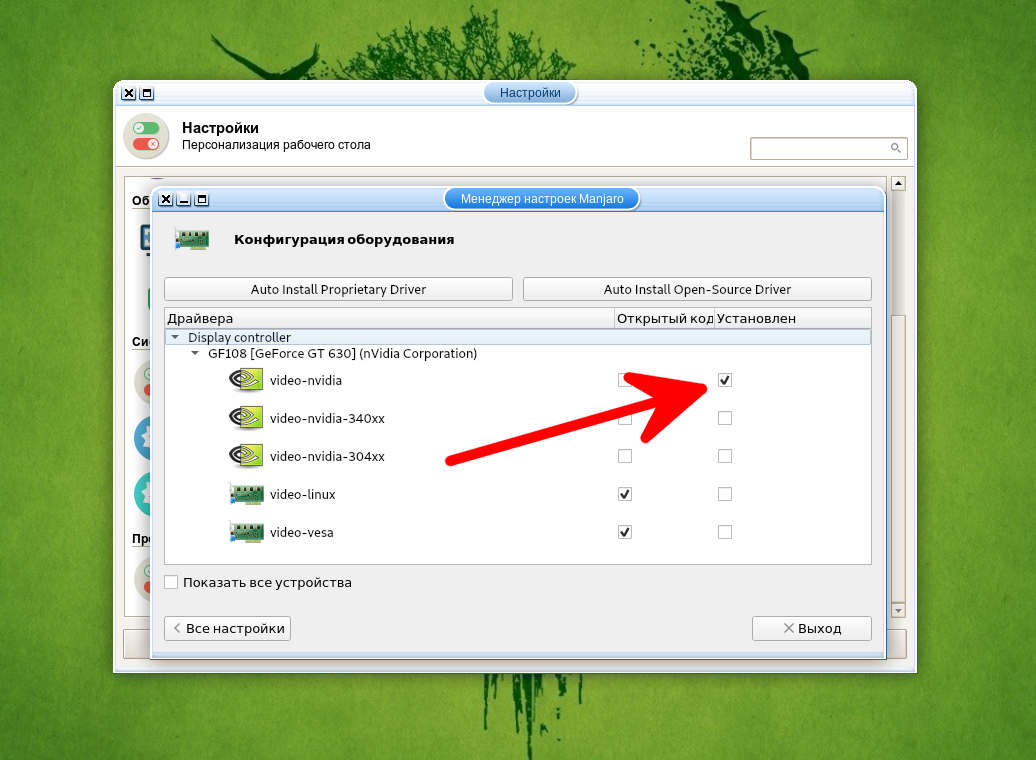
При наличии дискретной видеокарты необходимо установить её драйвер. Для этого войдите в Диспетчер настроек → Manjaro Settings Manager и выберите Конфигурация оборудования.
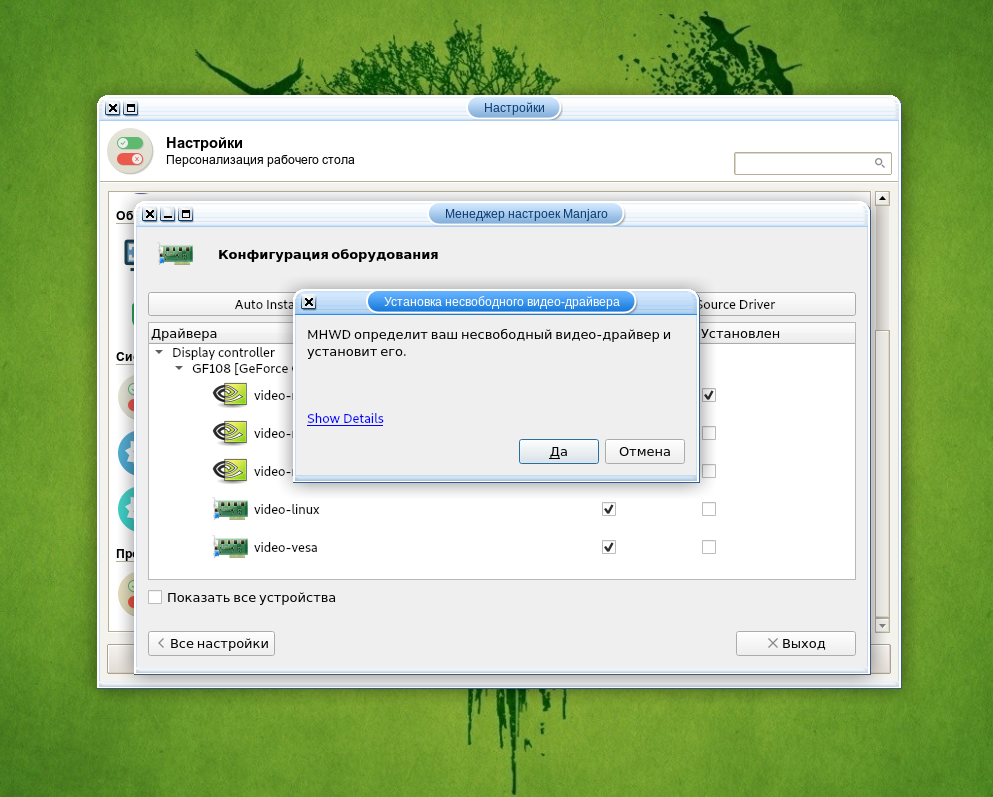
Для автоматической установки проприетарного драйвера, нажмите кнопку Auto Install Proprietary Driver.
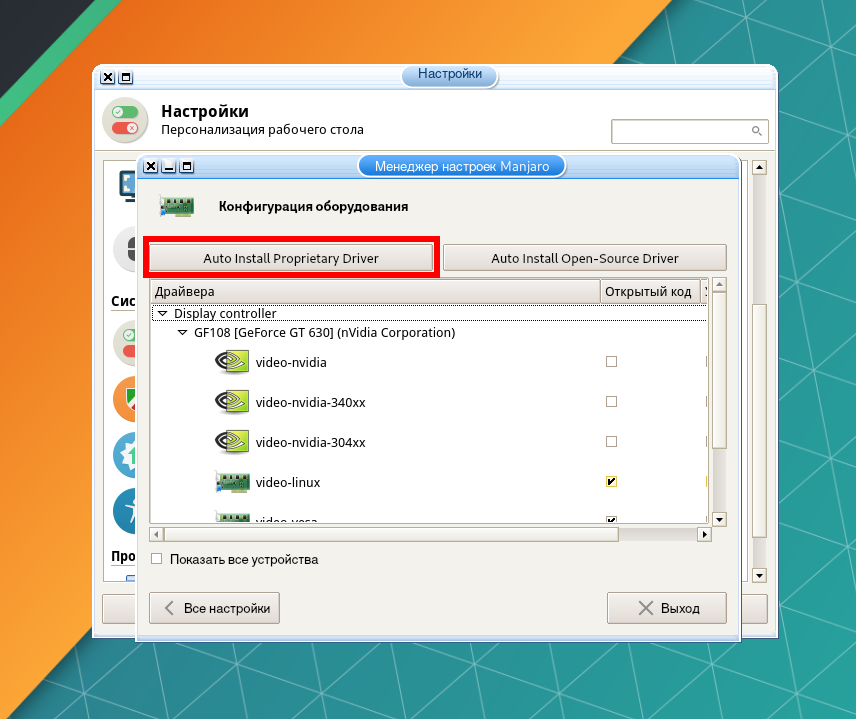
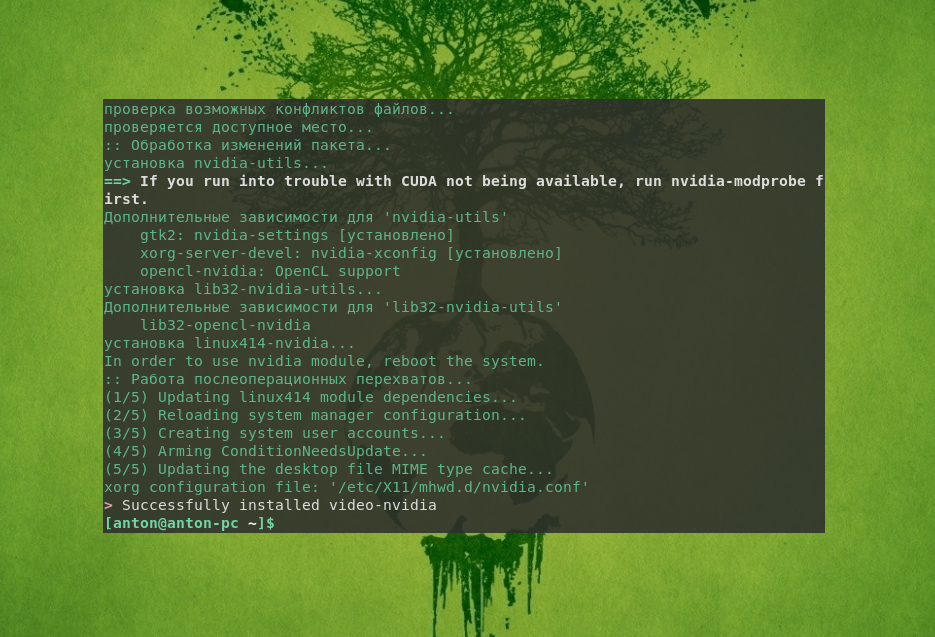
После этого перезагрузите компьютер. Подробно об инсталляции драйвера видеокарты рассказано в статье «Установка драйвера Nvidia в Manjaro».
Выводы
В этой статье мы рассмотрели, как выполняется настройка Manjaro после установки. Простота Manjaro проявляется во всех её аспектах, в том числе и в настройке после установки. Любым удобным способом (графически или через терминал) возможна тонкая настройка элементов системы, начиная от панели и заканчивая управлением драйверами.