Ваш путеводитель по одной из самых популярных и влиятельных операционных систем в мире. От базовых команд и установки дистрибутивов до глубокого изучения ядра и сетевых технологий — здесь вы найдете статьи и руководства на самые разные темы, связанные с Linux. Независимо от вашего уровня подготовки, здесь найдется что-то интересное и полезное.
В качестве инструмента для архивации данных в Linux используются разные программы. Например архиватор Zip Linux, приобретший большую популярность из-за совместимости с ОС Windows. Но это не стандартная для системы программа. Поэтому хотелось бы осветить команду tar Linux — встроенный архиватор.
Изначально tar использовалась для архивации данных на ленточных устройствах. Но также она позволяет записывать вывод в файл, и этот способ стал широко применяться в Linux по своему назначению. Здесь будут рассмотрены самые распространенные варианты работы с этой утилитой. Читать далее Команда tar в Linux→
Manjaro — самый популярный дистрибутив GNU/Linux, как минимум, в течение последних месяцев в рейтинге Distrowatch. Причин для этого более чем достаточно. В статье будет рассмотрен один из несомненных плюсов системы, который по удобству, качеству и простоте является одним из самых привлекательных для пользователей, — установка программ в Manjaro.
Стандартной средой рабочего стола в Manjaro является Xfce. Именно в ней мы опробуем два варианта установки ПО: графический и с помощью терминала.
Установка программ в Manjaro Linux
Manjaro имеет собственный список источников программного обеспечения, рядом с которым также работает репозиторий Arch (в том числе и пользовательский репозиторий AUR).
1. Установка пакетов Manjaro через графический интерфейс
По умолчанию система использует pamac в качестве менеджера управления программами, которая является графическим вариантом консольной утилиты pacman, о которой будет сказано позже. Он может работать одновременно со стандартным репозиторием и с AUR.
Чтобы запустить его, откройте меню Xfce → Настройки → Установка и удаление программ (или воспользуйтесь поиском).
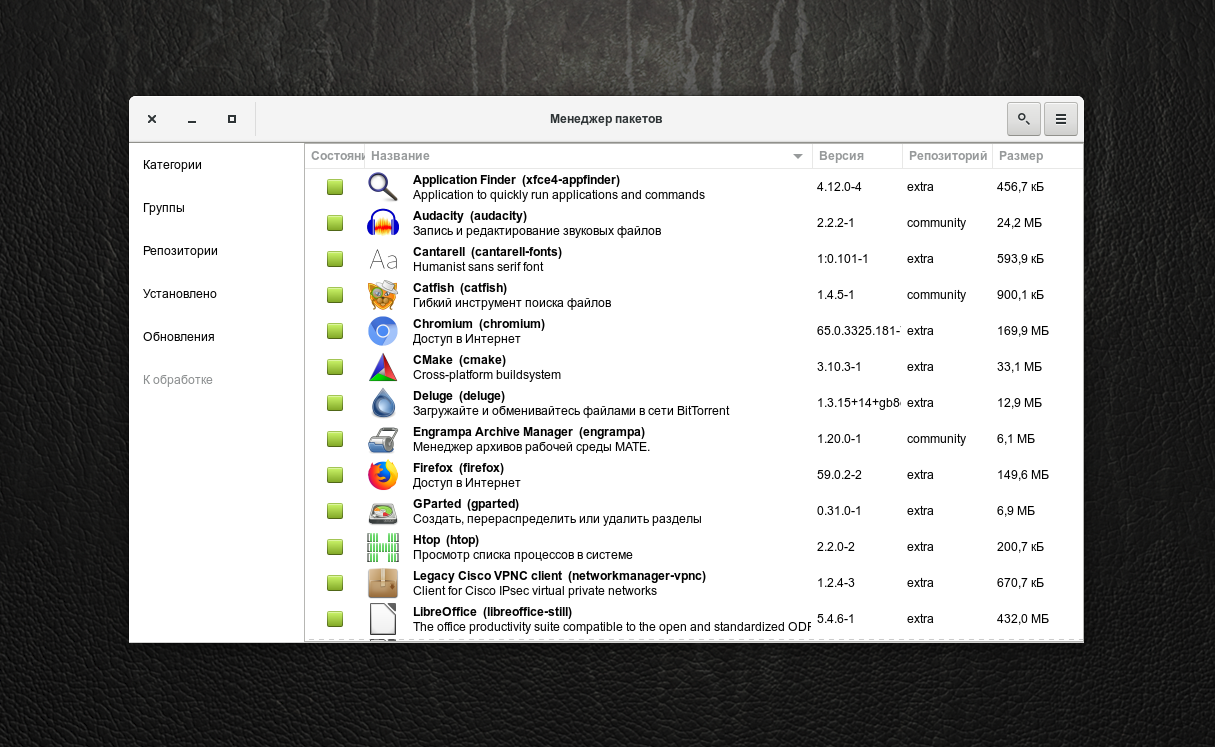
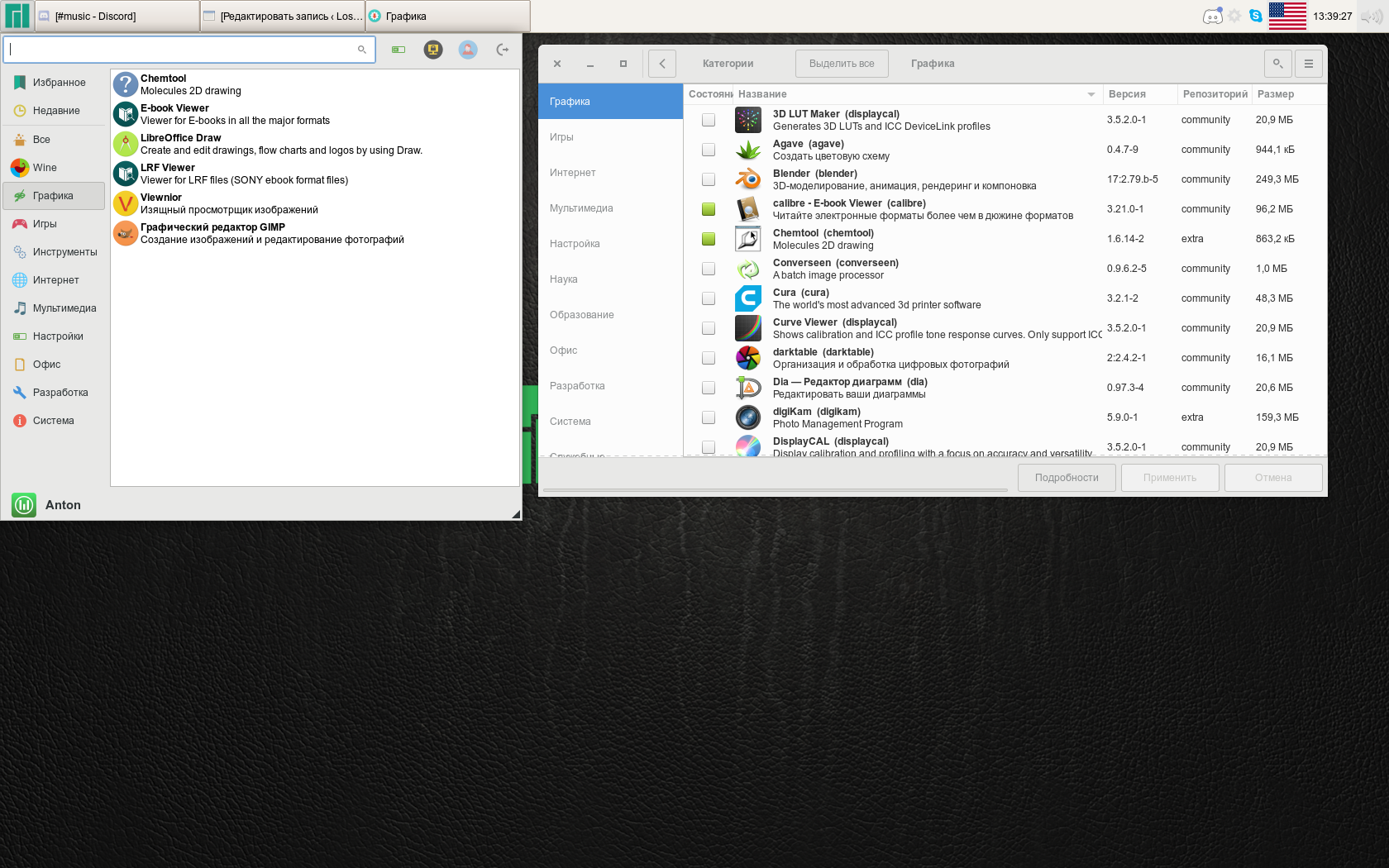
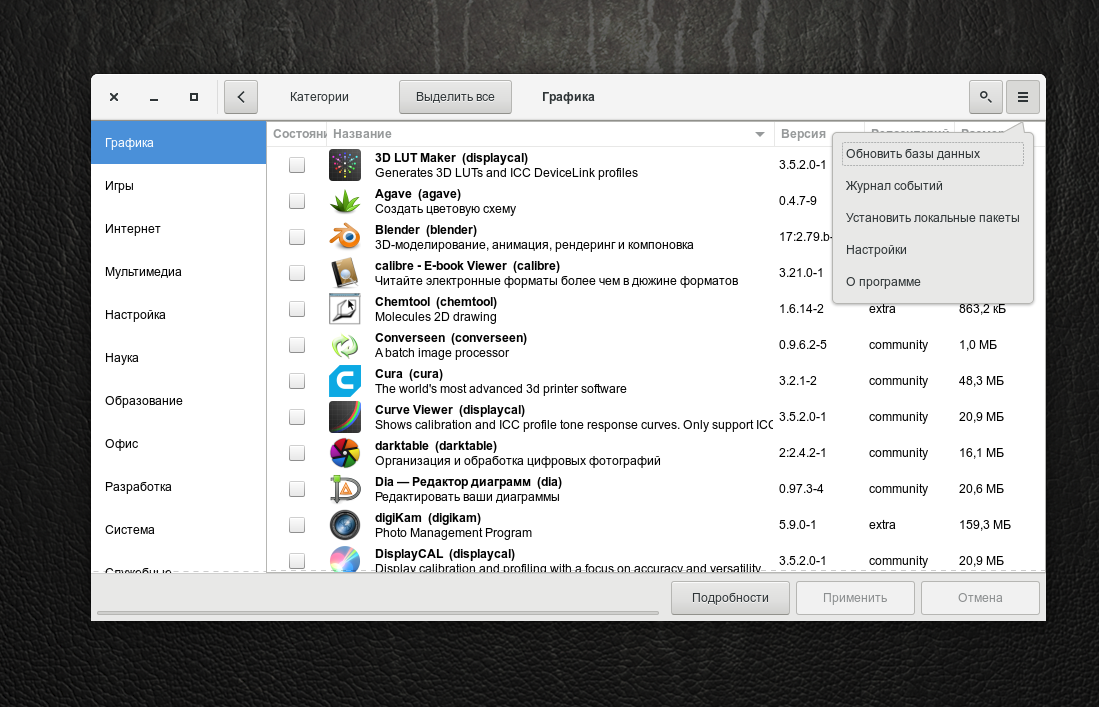
Pamac имеет схожий с подобными программами интерфейс, в котором есть возможность сортировать все программы по категориям, группам и т.д.
Установленные программы имеют окрашенное зеленым цветом поле Состояние. Чтобы установить программу Manjaro, выберите необходимый фильтр ПО (например Категории). Укажите один из предложенных разделов:
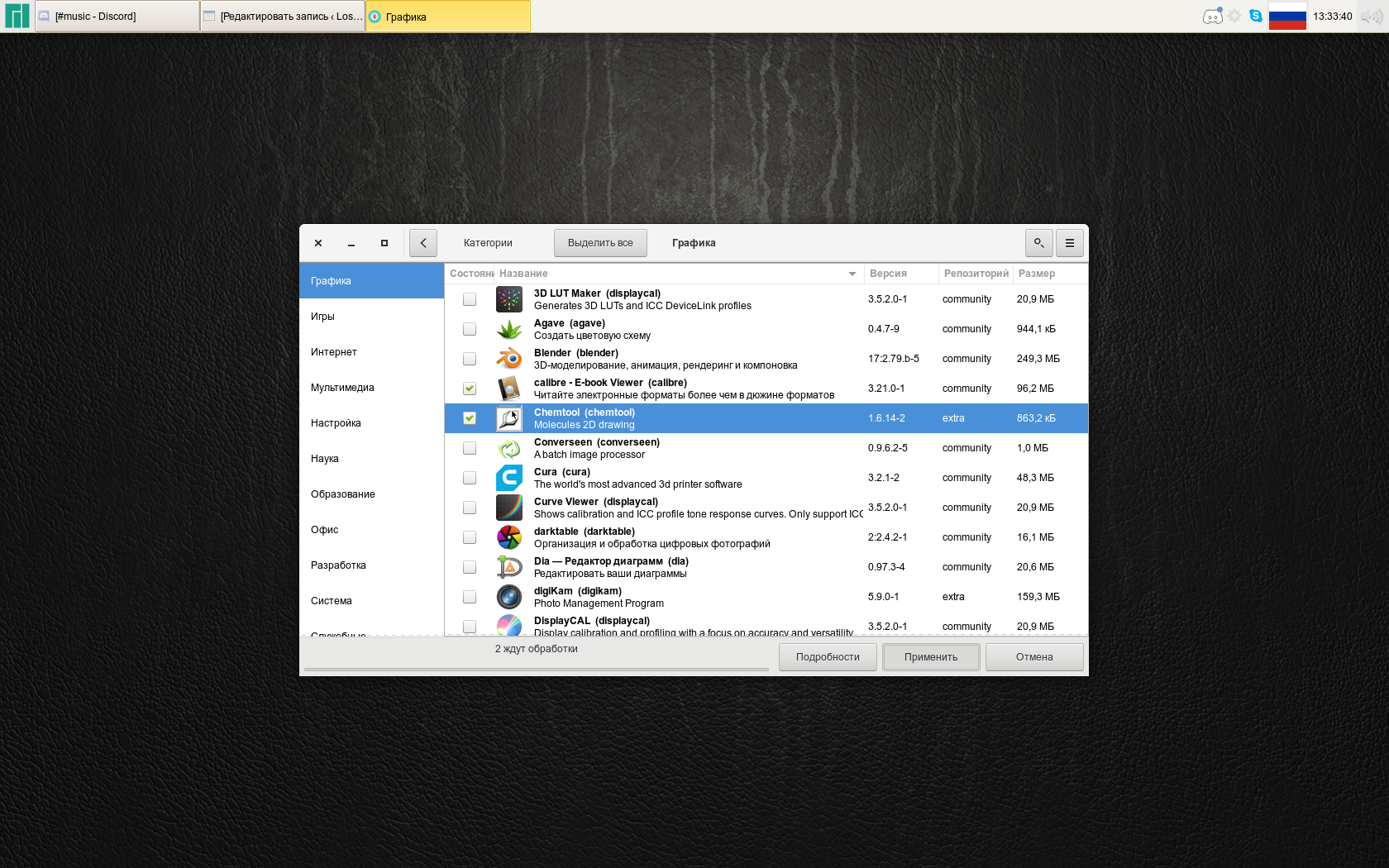
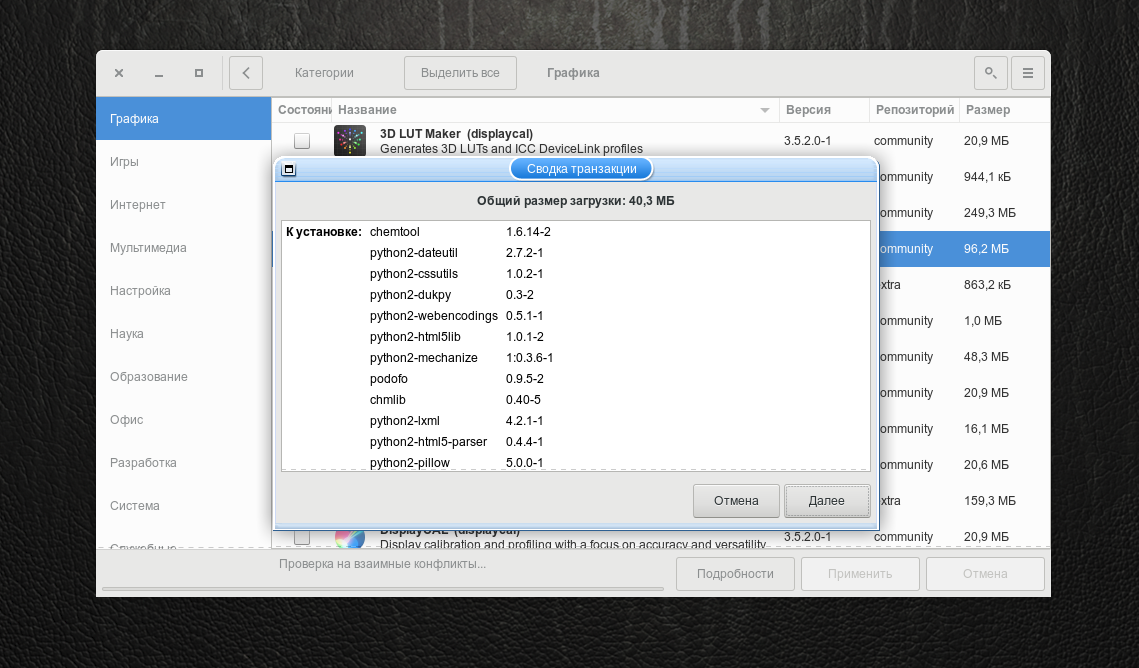
Укажите одну или несколько программ для установки, поставив галочку в поле Состояние → Применить.
При необходимости установить дополнительные зависимости ПО, pamac выдаст соответствующее окно с полным их перечнем → Далее.
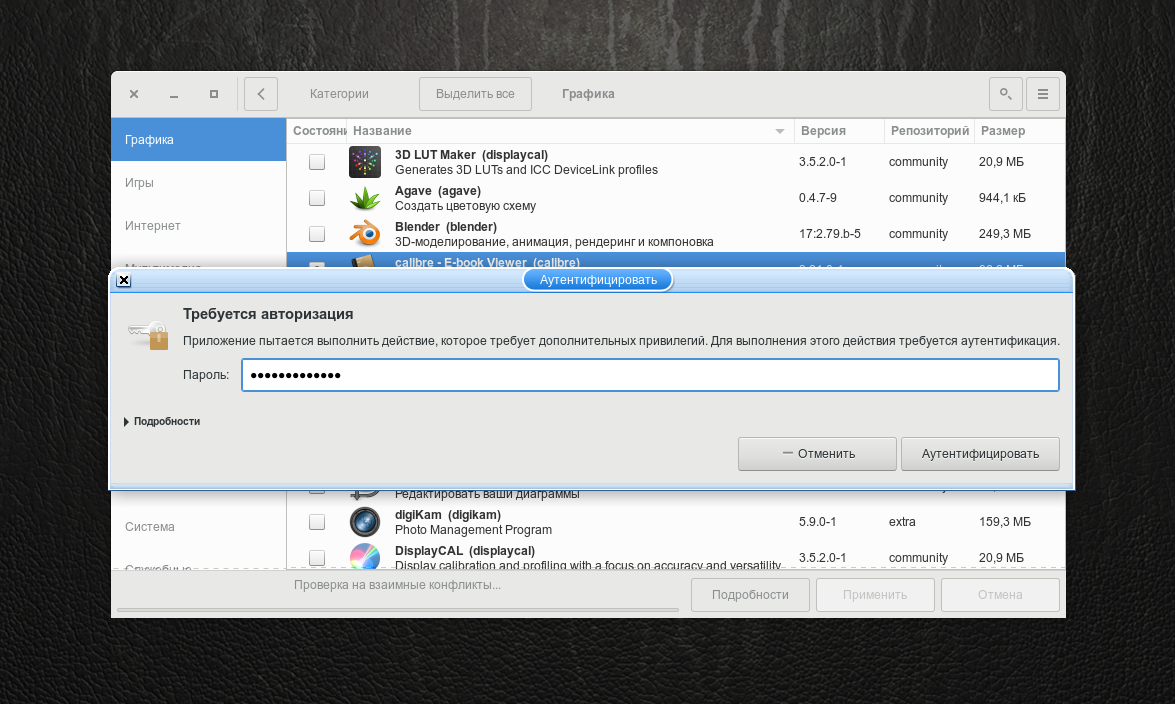
При первой попытке установки, за время работы pamac будет запрошен пароль пользователя. Введите его и нажмите Аутентифицировать.
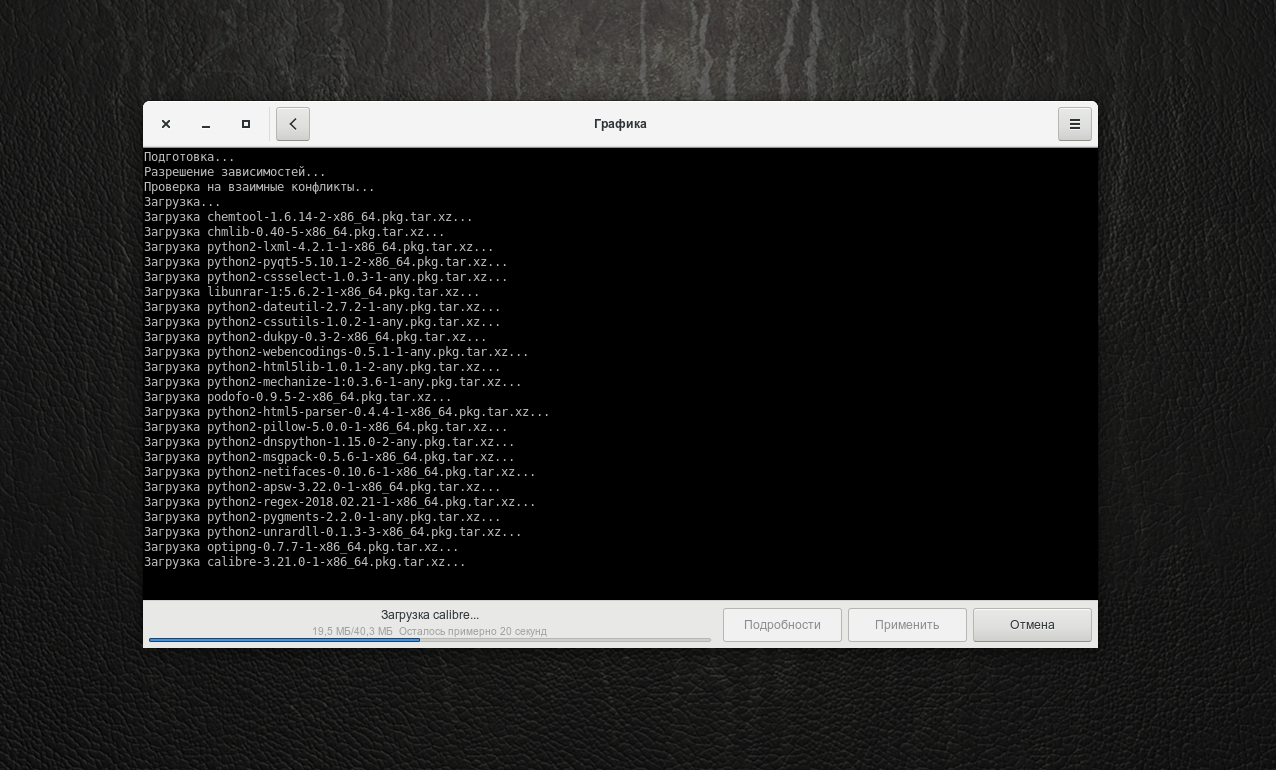
Начнётся инсталляция. Для просмотра подробностей установки нажмите кнопку Подробно.
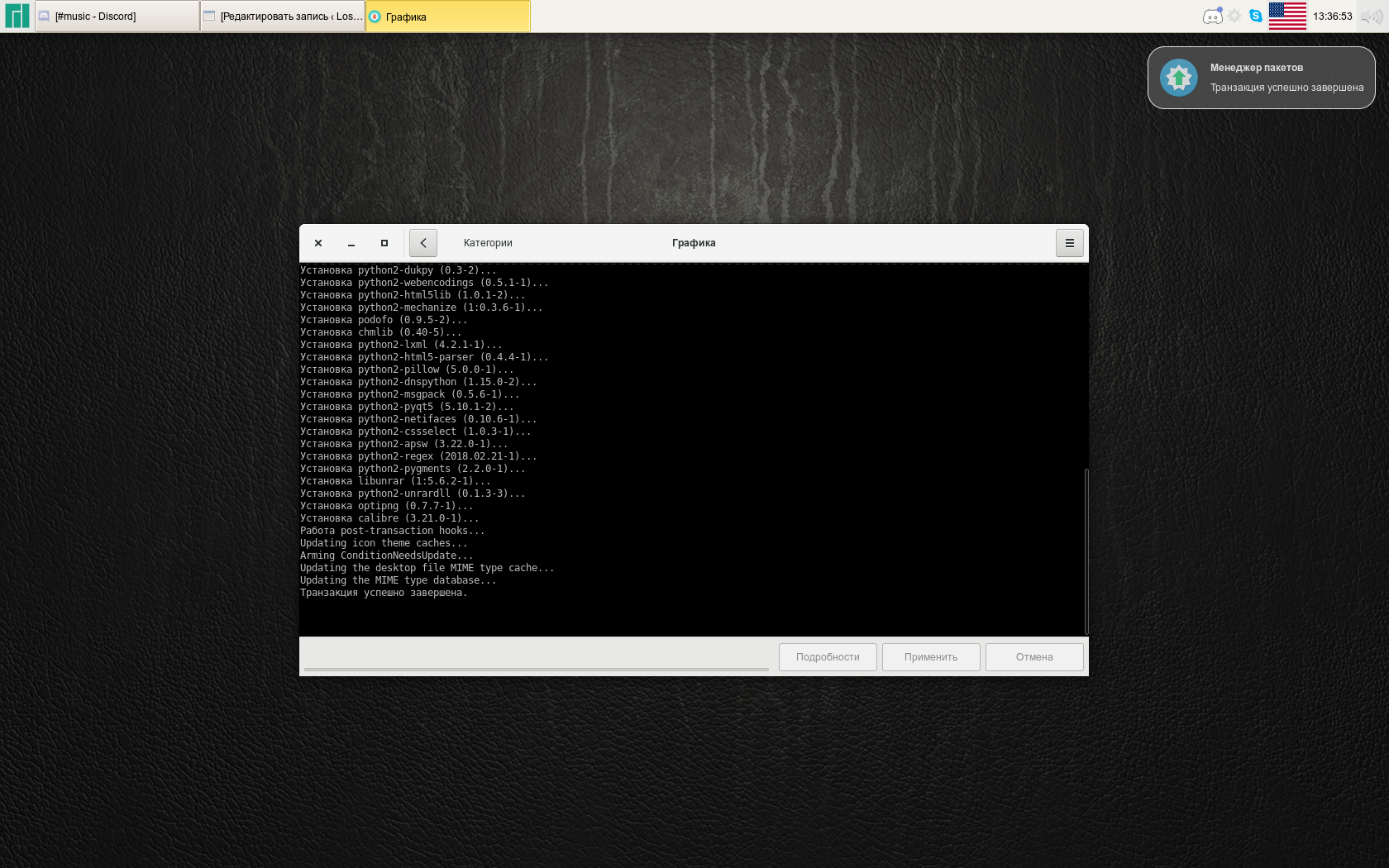
По окончании процесса появится сообщение об успешном завершении транзакции с соответствующим уведомлением.
С помощью стрелки влево вверху окна программы можно вернуться к предыдущему виду. Установленные приложения появятся в необходимом разделе меню.
Таким образом выбранные программы будут установлены в систему графически.
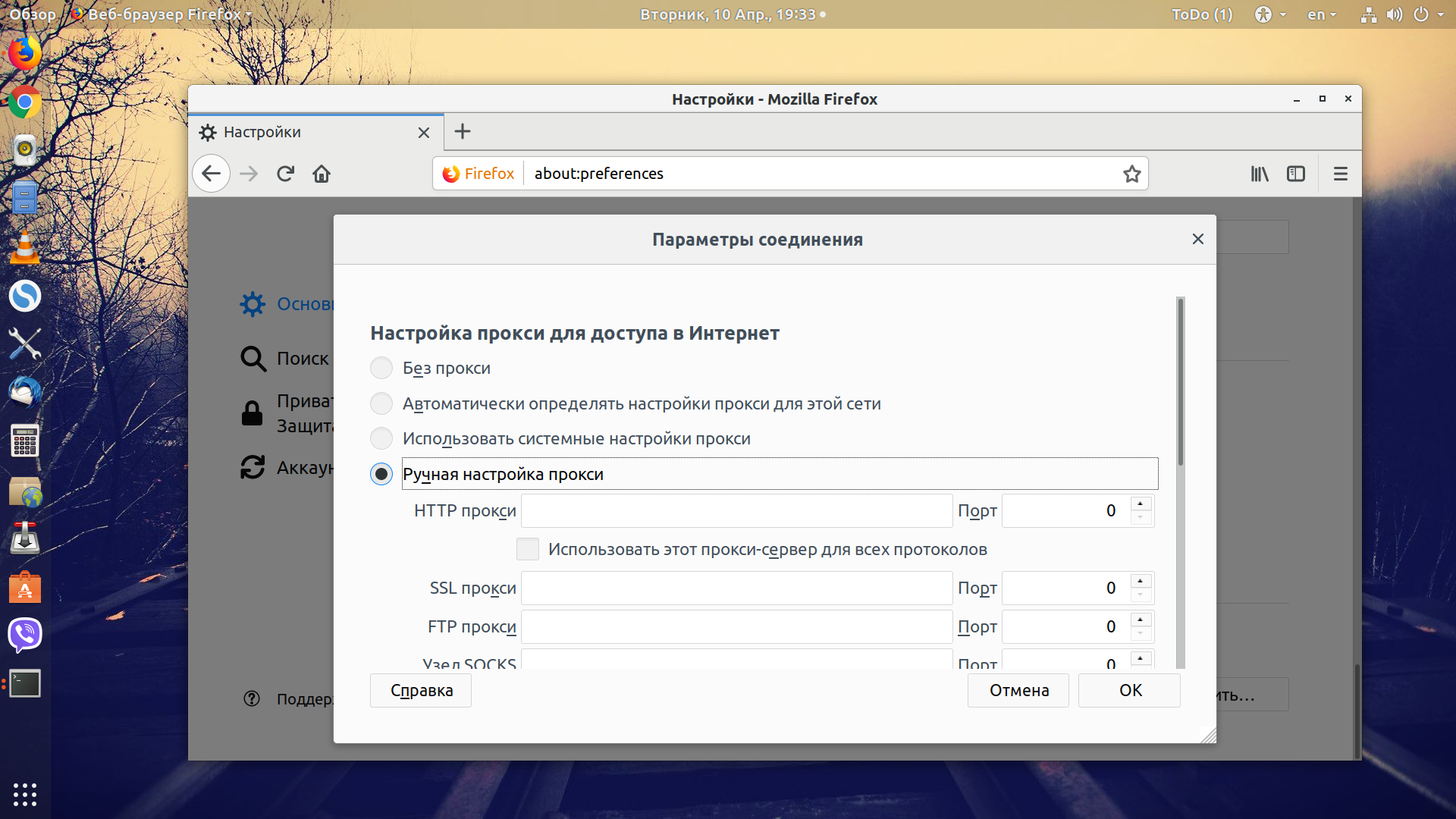
2. Установка пакетов с помощью pacman
Для инсталляции ПО в терминале используется утилита pacman. Этот метод подходит для тех, кто привык управлять установкой и удалением программ «вручную». В некоторых случаях этим способом получается совершать некоторые операции с ПО быстрее, чем в графическом варианте.
Главное отличие pacman от pamac в том, что первый не производит установку из AUR. Для этого используется утилита yaourt. Рассмотрим их по очереди.
Чтобы установить программу с помощью pacman, используйте следующую инструкцию:
sudopacman-SNAME
sudo — выполнить команду от имени суперпользователя;
pacman — название управляющей утилиты;
-S — указание установить программу;
NAME — имя программы в том виде, в каком оно указано в репозитории.
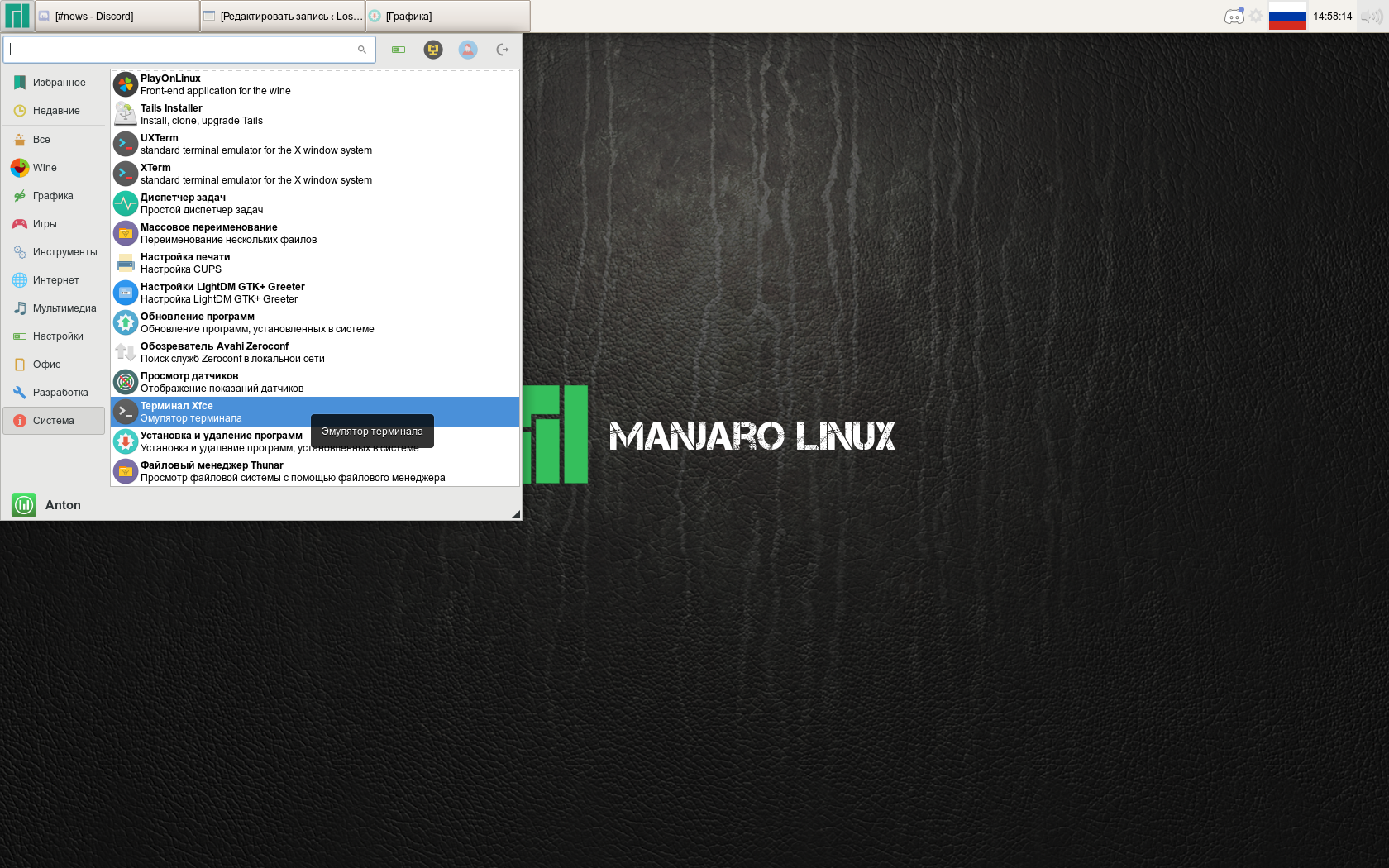
Например, чтобы установить редактор vim, откройте меню Xfce → Настройки → Терминал Xfce.
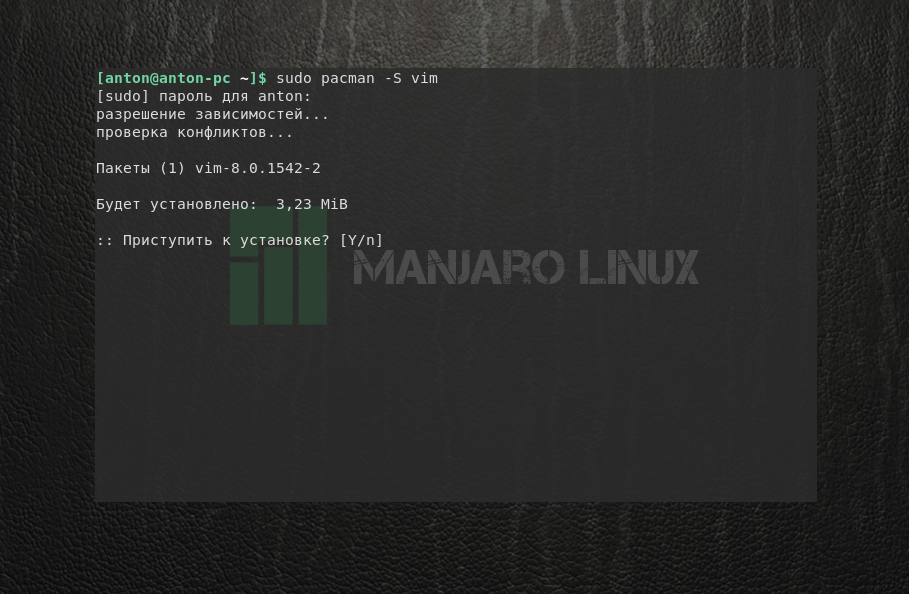
Введите команду установки и, при необходимости, подтвердите паролем.
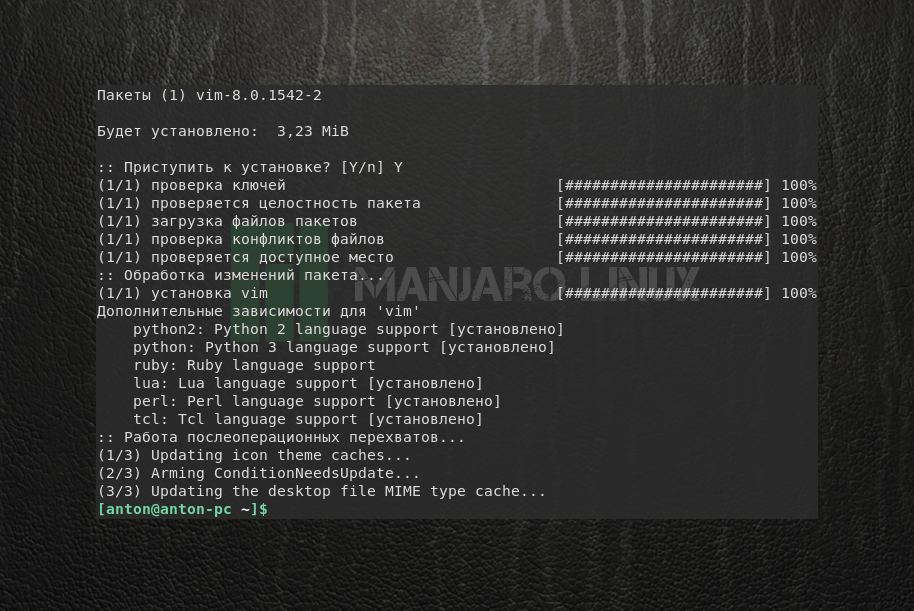
Далее pacman предложит установить пакет в Manjaro, если его имя было введено правильно и он находится в репозитории. Чтобы подтвердить выбор, введите Y и нажмите Enter. Обратите внимание, что в данном случае регистр вводимой буквы не имеет особого значения: большая буква означает, что этот вариант будет выбран по умолчанию, если вы нажмете Enter без точного указания.
Дождитесь, пока установка программы завершится и появится приглашение ввода новой команды.
Таким образом будет установлен текстовый редактор vim.
3. Установка пакетов с помощью yaourt
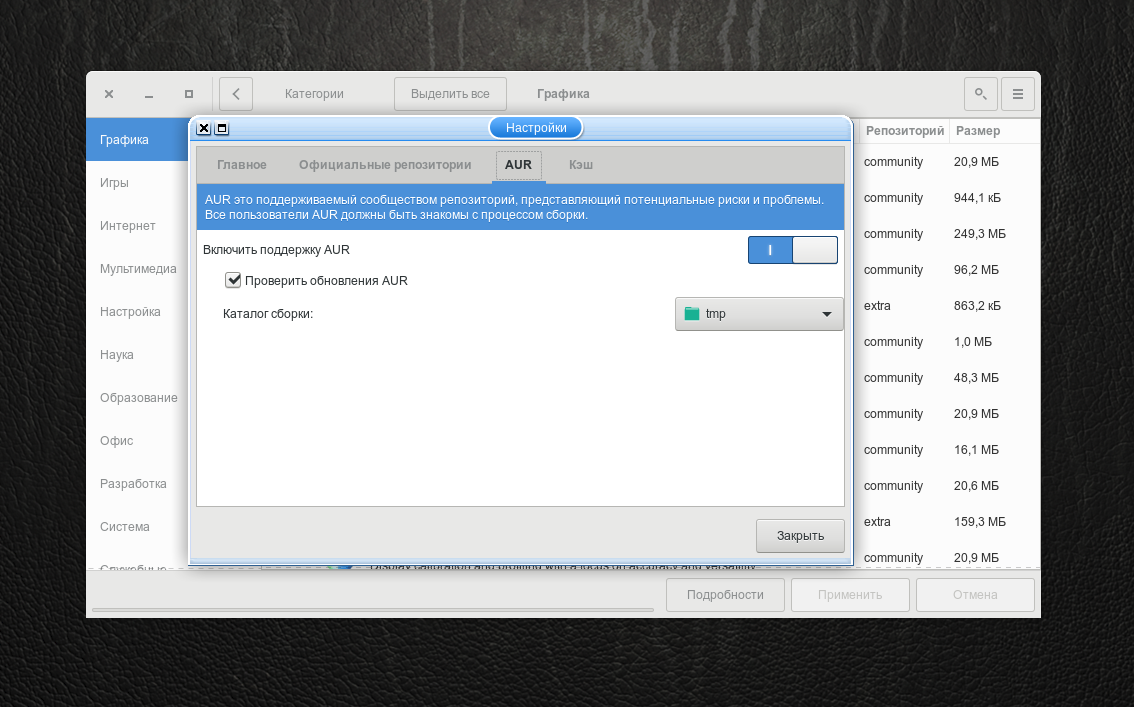
Эта утилита используется для установки приложений из пользовательского репозитория — AUR. Но по умолчанию она не установлена, так как AUR нужно включить вручную. Для этого откройте pamac. В меню программы выберите Настройки.
Во вкладе AUR включите его поддержку.
Закройте pamac. Для установки yaourt воспользуйтесь командой:
sudo pacman -S yaourt
Чтобы установить приложение из AUR, используйте такую инструкцию:
yaourtNAME
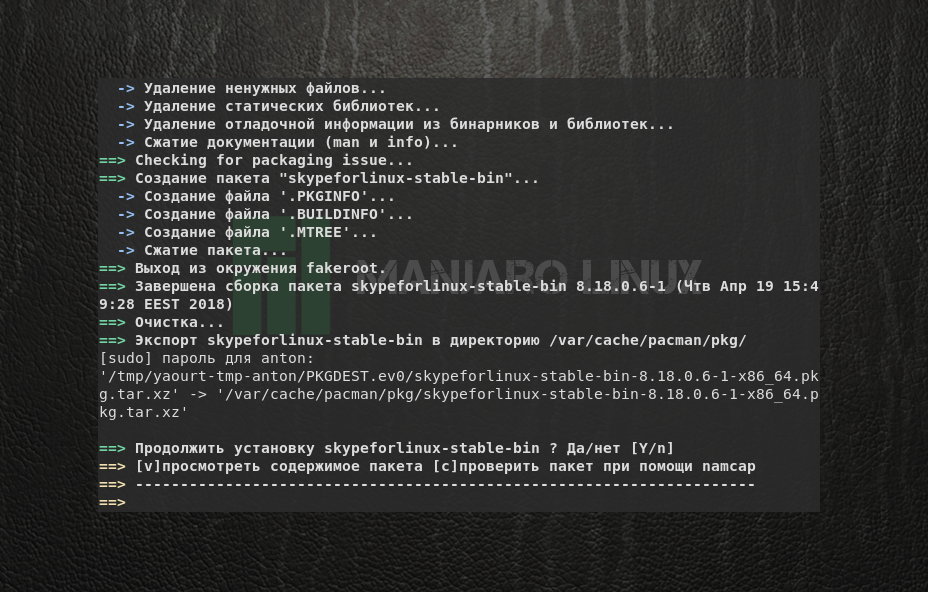
где NAME — имя устанавливаемой программы. Например, для установки программы skype введите команду:
yaourt skype
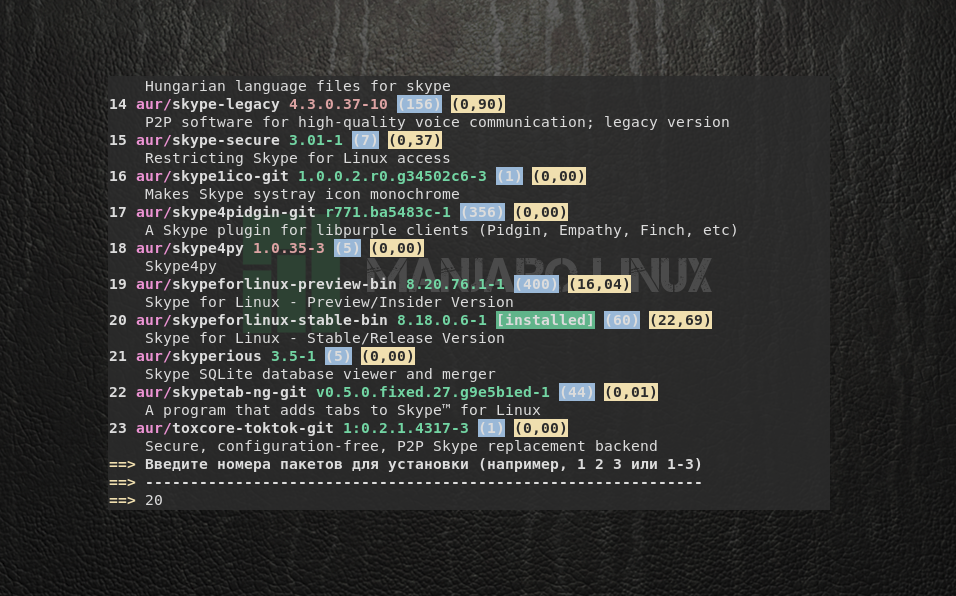
Поскольку в AUR находится много пакетов, в названиях которых содержится skype, необходимо выбрать из списка тот, который необходим. В данном случае это пакет под номером 20. Введите его и нажмите Enter.
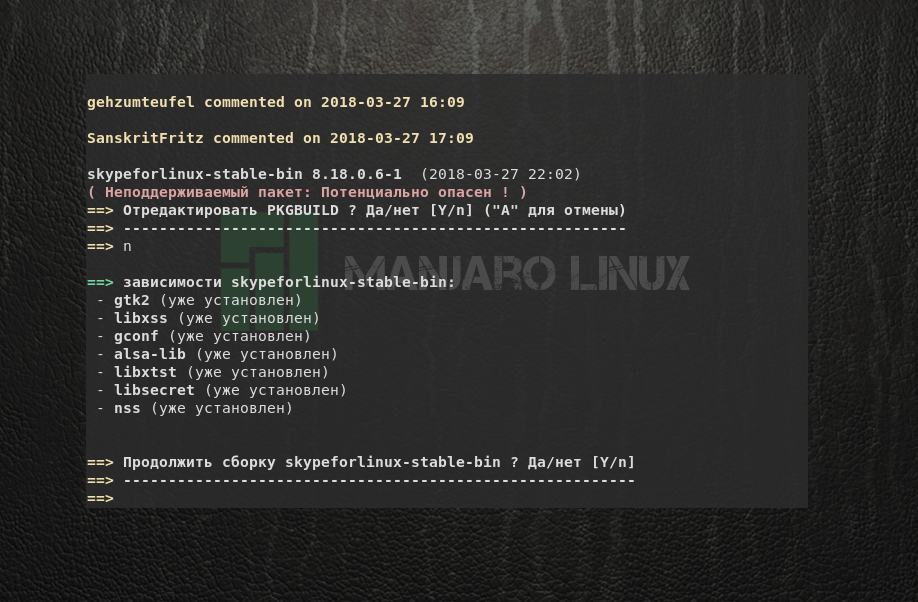
Далее yaourt предупредит, что вы устанавливаете выбранную программу на свой страх и риск и предложит отредактировать файл PKGBUILD, являющийся инструкцией по сборке ПО из исходного кода. На это отвечайте отрицательно буквой N. Обратите внимание, что с этого момента момента ввод буквы не требует подтверждения. Затем отобразится список устанавливаемых пакетов. Подтвердите выбор с помощью буквы Y или нажатием Enter.
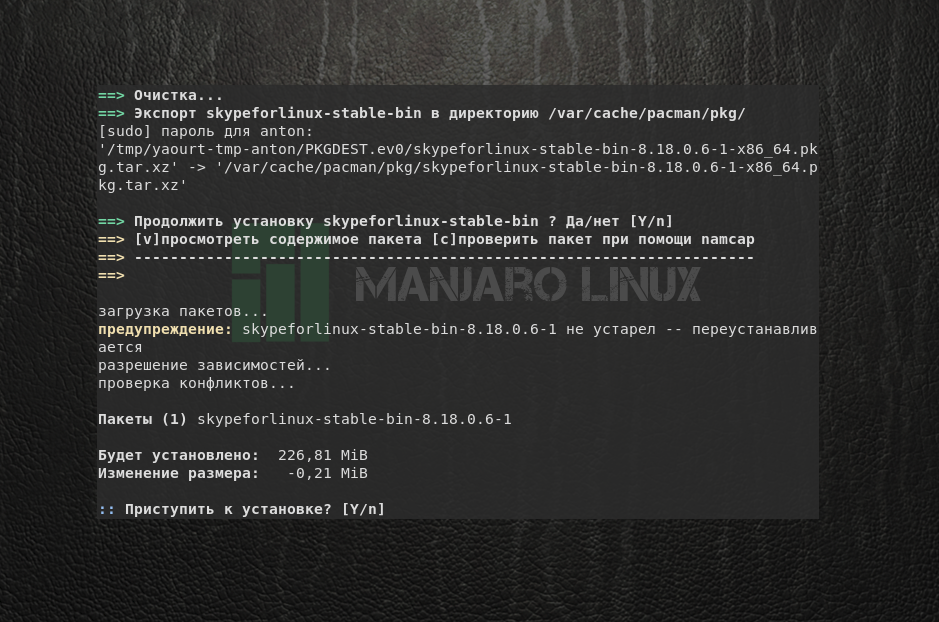
Начнётся процесс скачивания и сборки пакетов. Когда программа будет готова к установке, появится соответствующий вопрос. Ответьте утвердительно.
Запустится установка пакетов Manjaro, где будет показана итоговая информацию по изменению размера свободного места на диске. Подтвердите решение.
После этого программа будет установлена на компьютер и отобразится в соответствующей категории.
Выводы
Установка программ в Manjaro возможна в двух вариантах: графическом и консольном. Отличительная особенность установки в терминале - использование разных утилит для инсталляции ПО из стандартных репозиториев и AUR (а именно — pacman и yaourt).
Часто возникает необходимость, чтобы скрипт командного интерпретатора Bash выводил результат своей работы. По умолчанию он отображает стандартный поток данных — окно терминала. Это удобно для обработки результатов небольшого объёма или, чтобы сразу увидеть необходимые данные.
В интерпретаторе можно делать вывод в файл Bash. Применяется это для отложенного анализа или сохранения массивного результата работы сценария. Чтобы сделать это, используется перенаправление потока вывода с помощью дескрипторов.
Стандартные дескрипторы вывода
В системе GNU/Linux каждый объект является файлом. Это правило работает также для процессов ввода/вывода. Каждый файловый объект в системе обозначается дескриптором файла — неотрицательным числом, однозначно определяющим открытые в сеансе файлы. Один процесс может открыть до девяти дескрипторов.
В командном интерпретаторе Bash первые три дескриптора зарезервированы для специального назначения:
Дескриптор
Сокращение
Название
0
STDIN
Стандартный ввод
1
STDOUT
Стандартный вывод
2
STDERR
Стандартный вывод ошибок
Их предназначение — обработка ввода/вывода в сценариях. По умолчанию стандартным потоком ввода является клавиатура, а вывода — терминал. Рассмотрим подробно последний.
Вывод в файл Bash
1. Перенаправление стандартного потока вывода
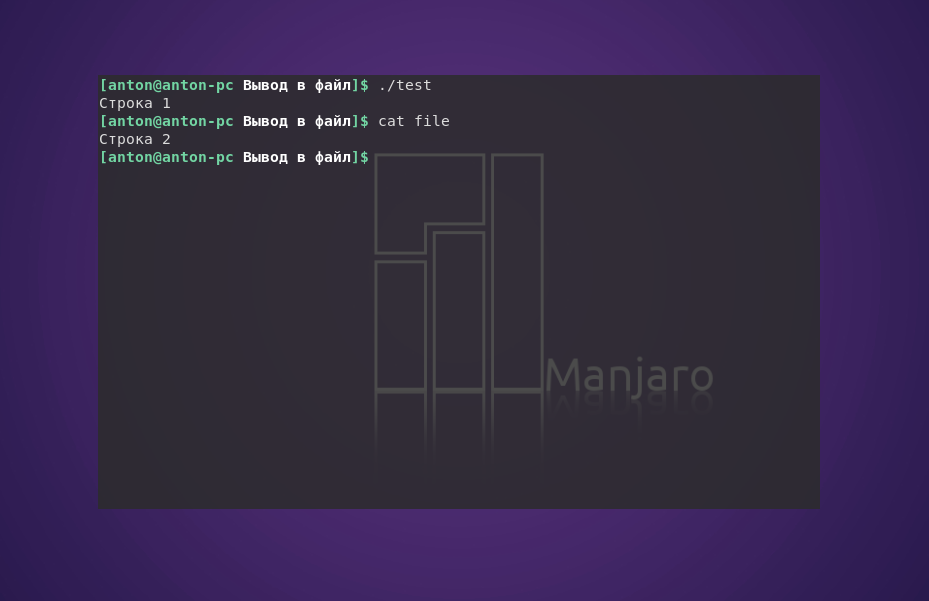
Для того, чтобы перенаправить поток вывода с терминала в файл, используется знак «больше» (>).
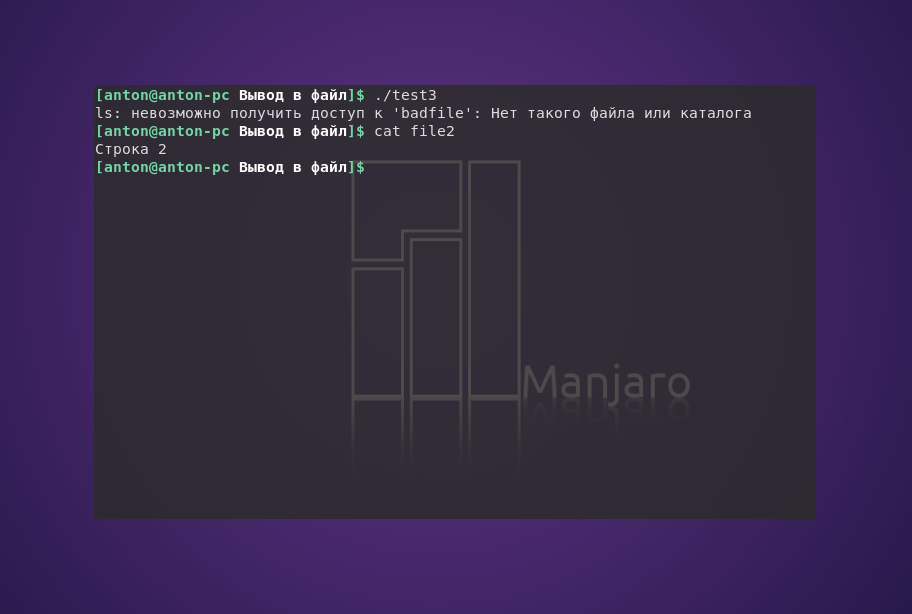
Здесь "Промежуточная строка" перезаписала предыдущее содержание file, а "Строка 2" дописалась в его конец.
Если во время использования перенаправления вывода интерпретатор обнаружит ошибку, то он не запишет сообщение о ней в файл.
#!/bin/bash
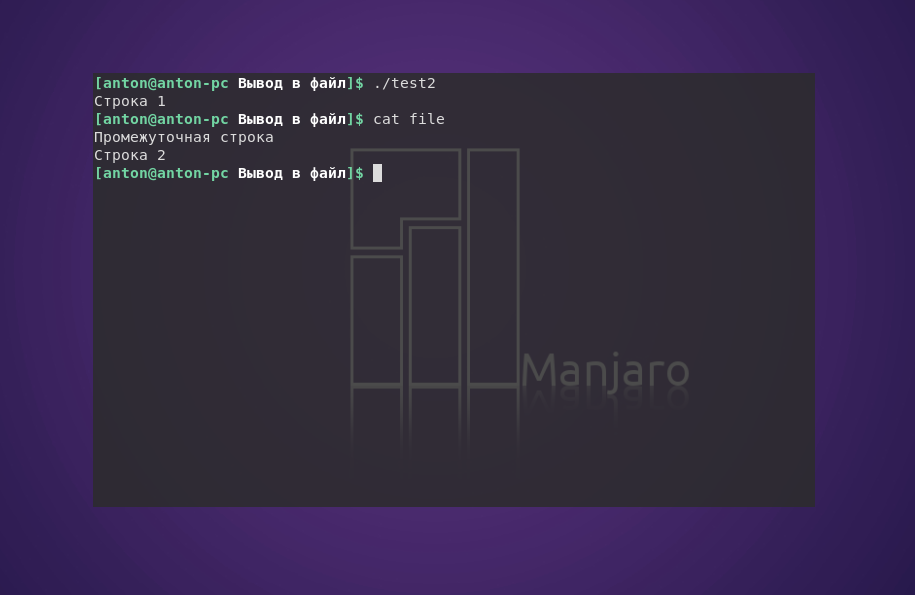
ls badfile > file2
echo "Строка 2" >> file2
В данном случае ошибка была в том, что команда ls не смогла найти файл badfile, о чём Bash и сообщил. Но вывелось сообщение в терминал, а не записалось в файл. Всё потому, что использование перенаправления потоков указывает интерпретатору отделять мух от котлет ошибки от основной информации.
Это особенно полезно при выполнении сценариев в фоновом режиме, где приходится предусматривать вывод сообщений в журнал. Но так как ошибки в него писаться не будут, нужно отдельно перенаправлять поток ошибок для того, чтобы выполнить их вывод в файл Linux.
2. Перенаправление потока ошибок
В командном интерпретаторе для обработки сообщений об ошибках предназначен дескриптор STDERR, который работает с ошибками, сформированными как от работы интерпретатора, так и самим скриптом.
По умолчанию STDERR указывает в то же место, что и STDOUT, хотя для них и предназначены разные дескрипторы. Но, как было показано в примере, использование перенаправления заставляет Bash разделить эти потоки.
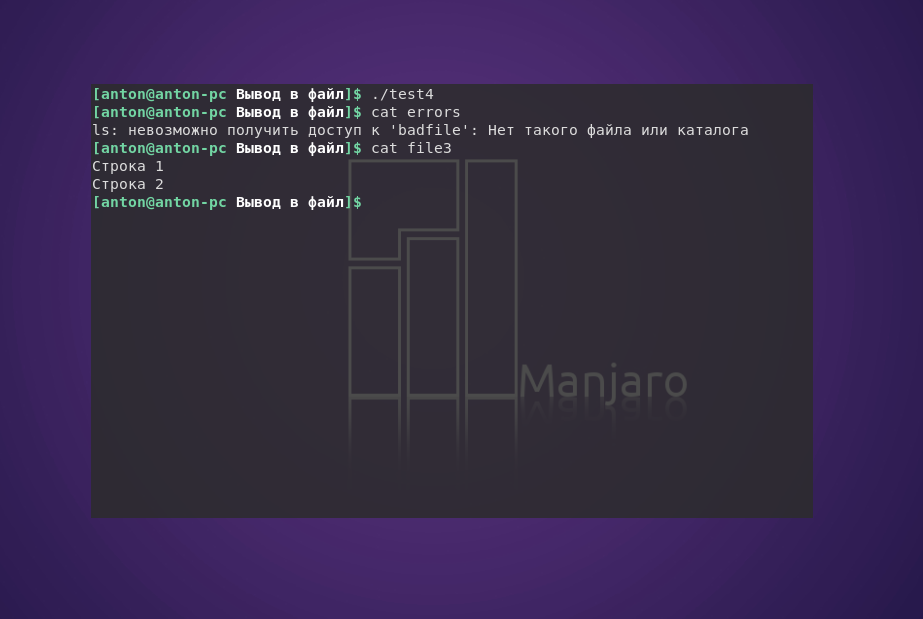
Чтобы выполнить перенаправление вывода в файл Linux для ошибок, следует перед знаком«больше» указать дескриптор 2.
В результате работы скрипта создан файл errors, в который записана ошибка выполнения команды ls, а в file3 записаны предназначенные строки. Таким образом, выполнение сценария не сопровождается выводом информации в терминал.
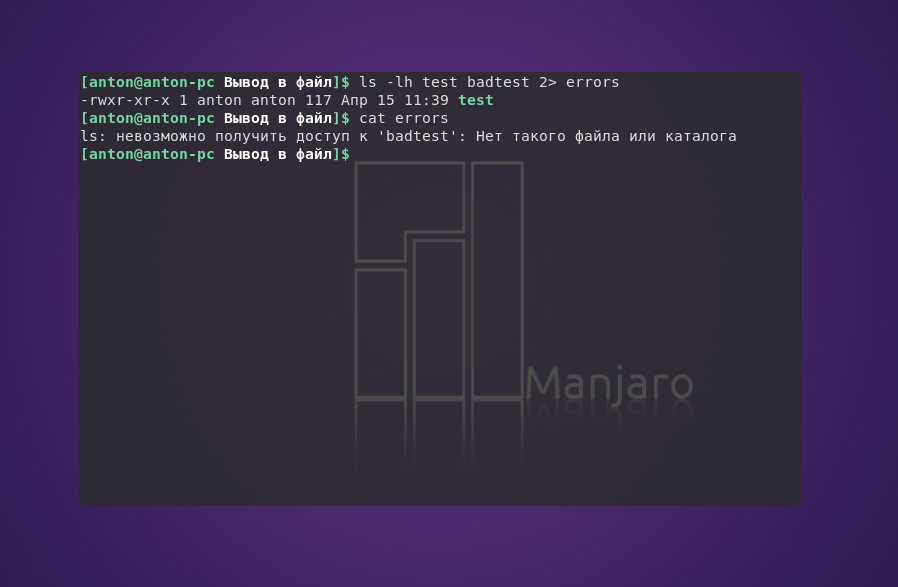
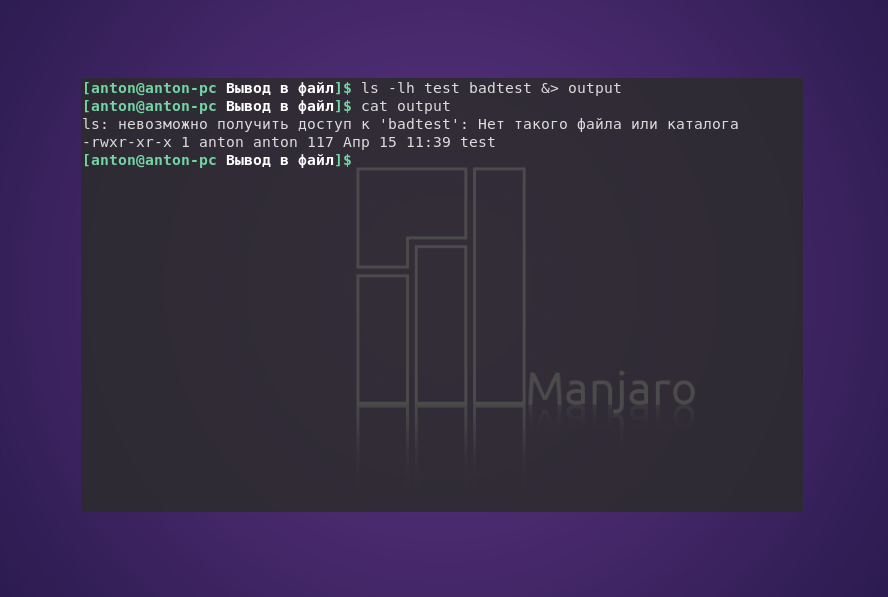
Пример того, как одна команда возвращает и положительный результат, и ошибку:
ls -lh test badtest 2> errors
Команда ls попыталась показать наличие файлов test и badtest. Первый присутствовал в текущем каталоге, а второй — нет. Но сообщение об ошибке было записано в отдельный файл.
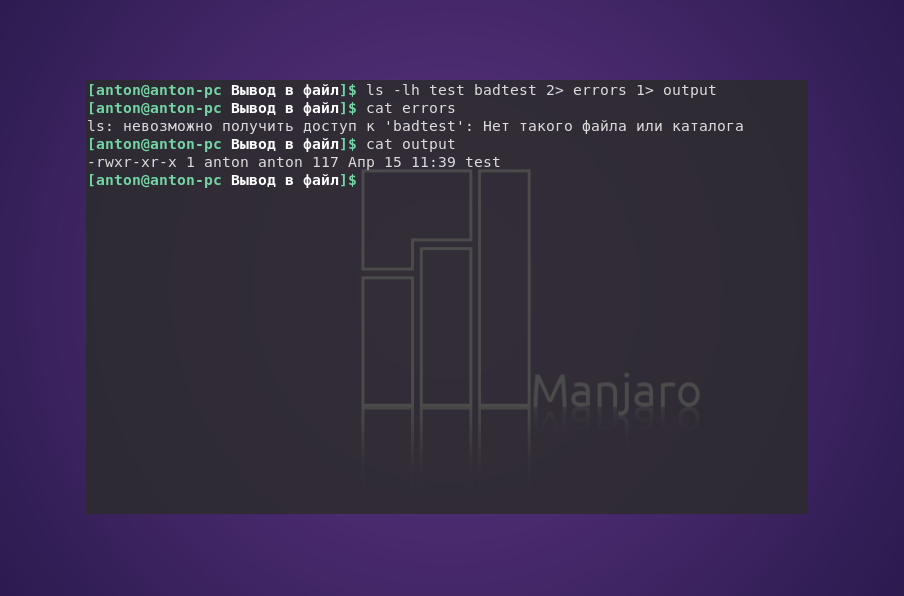
Если возникает необходимость выполнить вывод команды в файл Linux, включая её стандартный поток вывода и ошибки, стоит использовать два символа перенаправления, перед которыми стоит указывать необходимый дескриптор.
ls -lh test test2 badtest 2> errors 1> output
Результат успешного выполнения записан в файл output, а сообщение об ошибке — в errors.
По желанию можно выводить и ошибки, и обычные данные в один файл, используя &>.
ls -lh test badtest &> output
Обратите внимание, что Bash присваивает сообщениям об ошибке более высокий приоритет по сравнению с данными, поэтому в случае общего перенаправления ошибки всегда будут располагаться в начале.
Временные перенаправления в скриптах
Если есть необходимость в преднамеренном формировании ошибок в сценарии, можно каждую отдельную строку вывода перенаправлять в STDERR. Для этого достаточно воспользоваться символом перенаправления вывода, после которого нужно использовать & и номер дескриптора, чтобы перенаправить вывод в STDERR.
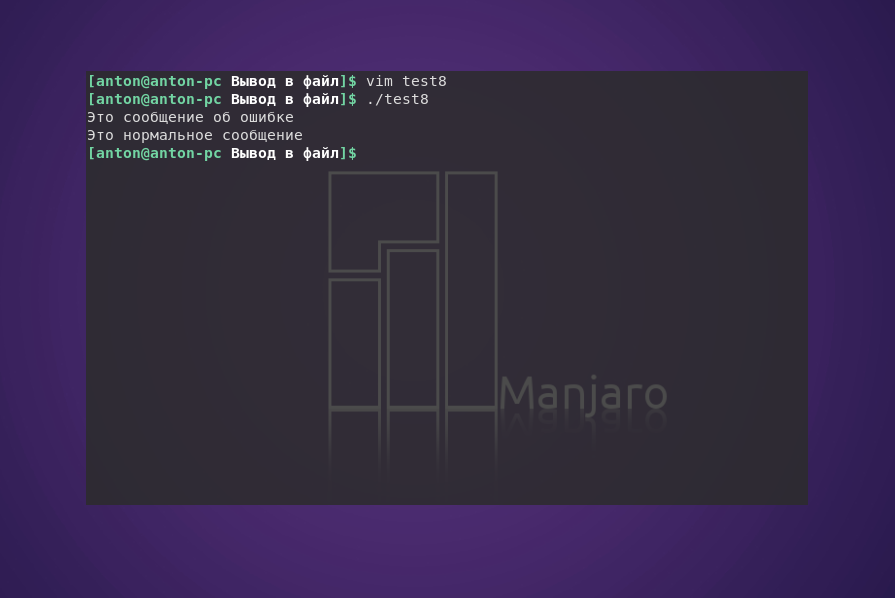
#!/bin/bash
echo "Это сообщение об ошибке" >&2
echo "Это нормальное сообщение"
При выполнении программы обычно нельзя будет обнаружить отличия:
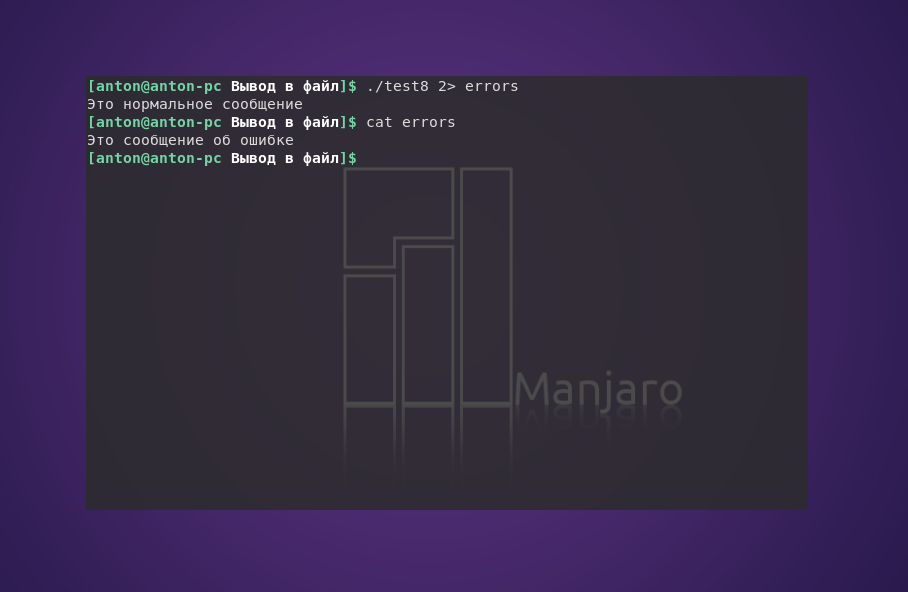
Вспомним, что GNU/Linux по умолчанию направляет вывод STDERR в STDOUT. Но если при выполнении скрипта будет перенаправлен поток ошибок, то Bash, как и полагается, разделит вывод.
Этот метод хорошо подходит для создания собственных сообщений об ошибках в сценариях.
Постоянные перенаправления в скриптах
Если в сценарии необходимо перенаправить вывод в файл Linux для большого объёма данных, то указание способа вывода в каждой инструкции echo будет неудобным и трудоёмким занятием. Вместо этого можно указать, что в ходе выполнения данного скрипта должно осуществляться перенаправление конкретного дескриптора с помощью команды exec:
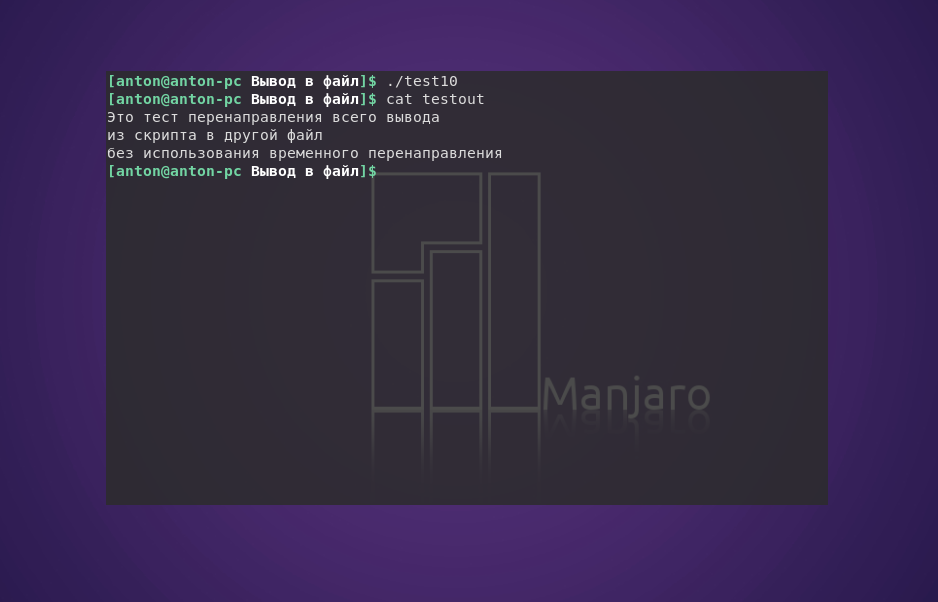
#!/bin/bash
exec 1> testout
echo "Это тест перенаправления всего вывода"
echo "из скрипта в другой файл"
echo "без использования временного перенаправления"
Вызов команды exec запускает новый командный интерпретатор и перенаправляет стандартный вывод в файл testout.
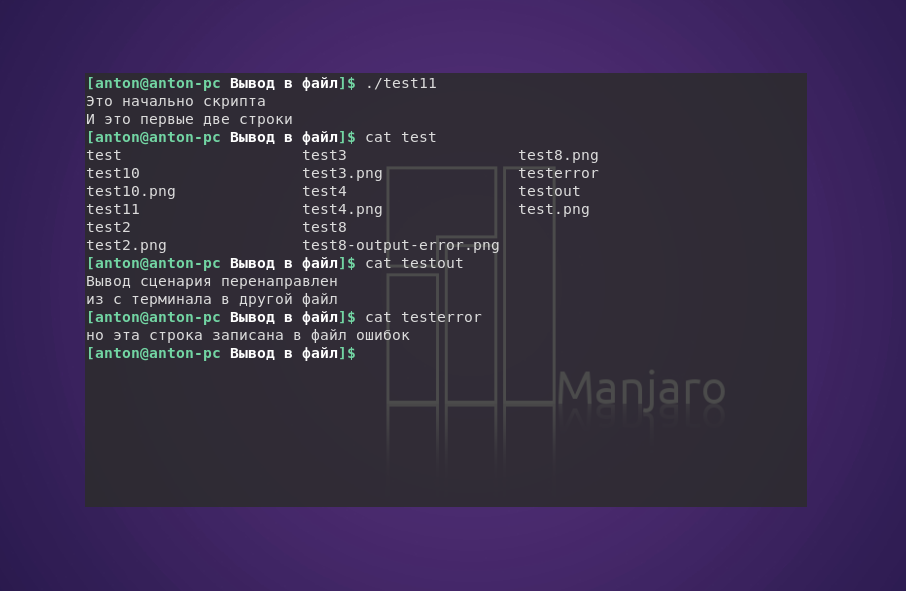
Также существует возможность перенаправлять вывод (в том числе и ошибок) в произвольном участке сценария:
#!/bin/bash
exec 2> testerror
echo "Это начально скрипта"
echo "И это первые две строки"
exec 1> testout
echo "Вывод сценария перенаправлен"
echo "из с терминала в другой файл"
echo "но эта строка записана в файл ошибок" >&2
Такой метод часто применяется при необходимости перенаправить лишь часть вывода скрипта в другое место, например в журнал ошибок.
Выводы
Перенаправление в скриптах Bash, чтобы выполнить вывод в файл Bash, является хорошим средством ведения различных журналов, особенно в фоновом режиме.
Использование временного и постоянного перенаправлений в сценариях позволяет создавать собственные сообщения об ошибках для записи в отличное от STDOUT место.
В операционных системах GNU/Linux любые объекты системы являются файлами. И проверка существования файла bash - наиболее мощный и широко применяемый инструмент для определения и сравнения в командном интерпретаторе.
В рамках интерпретатора Bash, как и в повседневном понимании людей, все объекты файловой системы являются, тем, чем они есть, каталогами, текстовыми документами и т.д. В этой статье будет рассмотрена проверка наличия файла Bash, а также его проверка на пустоту, и для этого используется команда test.
Проверка существования файла Bash
Начать стоит с простого и более общего метода. Параметр -e позволяет определить, существует ли указанный объект. Не имеет значения, является объект каталогом или файлом.
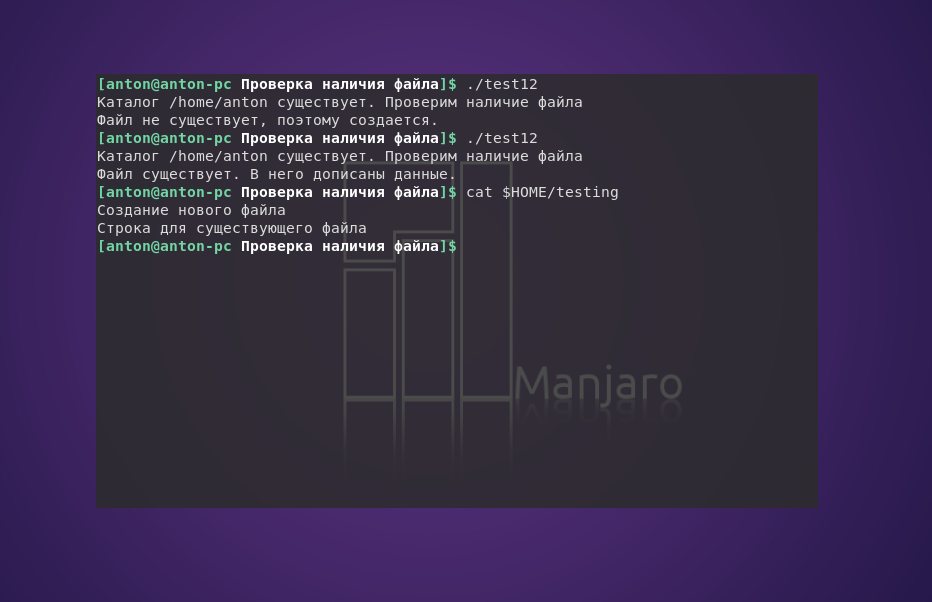
#!/bin/bash
# проверка существования каталога
if [ -e $HOME ]
then
echo "Каталог $HOME существует. Проверим наличие файла"
# проверка существования файла
if [ -e $HOME/testing ]
then
# если файл существует, добавить в него данные
echo "Строка для существующего файла" >> $HOME/testing
echo "Файл существует. В него дописаны данные."
else
# иначе — создать файл и сделать в нем новую запись
echo "Файл не существует, поэтому создается."
echo "Создание нового файла" > $HOME/testing
fi
else
echo "Простите, но у вас нет Домашнего каталога"
fi
Пример работы кода:
Вначале команда test проверяет параметром -e, существует ли Домашний каталог пользователя, название которого хранится системой в переменной $HOME. При отрицательном результате скрипт завершит работу с выводом сообщения об этом. Если такой каталог обнаружен, параметр -е продолжает проверку. На этот раз ищет в $HOME файл testing. И если он есть, то в него дописывается информация, иначе он создастся, и в него запишется новая строка данных.
Проверка наличия файла
Проверка файла Bash на то, является ли данный объект файлом (то есть существует ли файл), выполняется с помощью параметра -f.
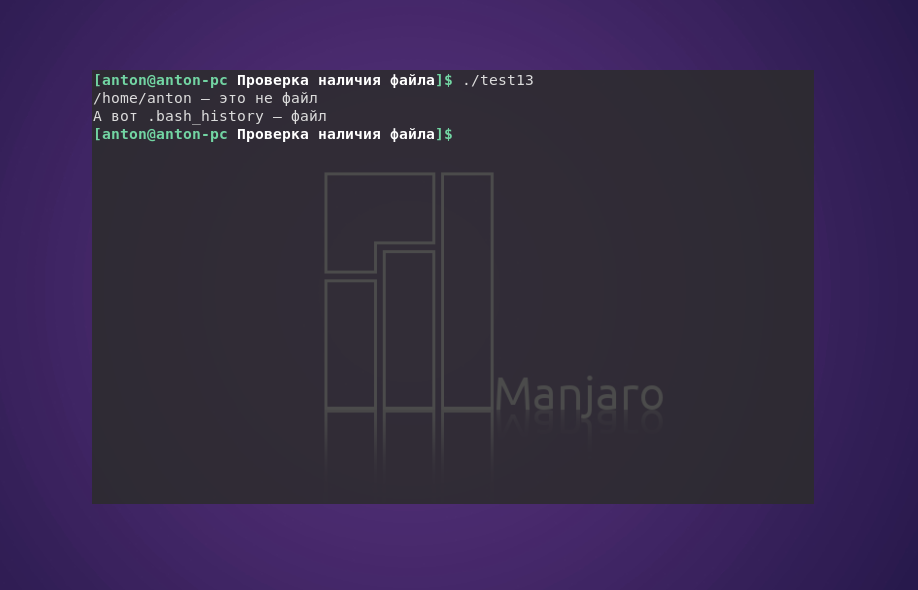
#!/bin/bash
if [ -f $HOME ]
then
echo "$HOME — это файл"
else
echo "$HOME — это не файл"
if [ -f $HOME/.bash_history ]
then
echo "А вот .bash_history — файл"
fi
fi
Пример работы кода:
В сценарии проверяется, является ли $HOME файлом. Результат проверки отрицательный, после чего проверяется настоящий файл .bash_history, что уже возвращает истину.
На заметку: на практике предпочтительнее использовать сначала проверку на наличие объекта как такового, а затем — на его конкретный тип. Так можно избежать различных ошибок или неожиданных результатов работы программы.
Проверка файла на пустоту
Чтобы определить, является ли файл пустым, нужно выполнить проверку с помощью параметра -s. Это особенно важно, когда файл намечен на удаление. Здесь нужно быть очень внимательным к результатам, так как успешное выполнение этого параметра указывает на наличие данных.
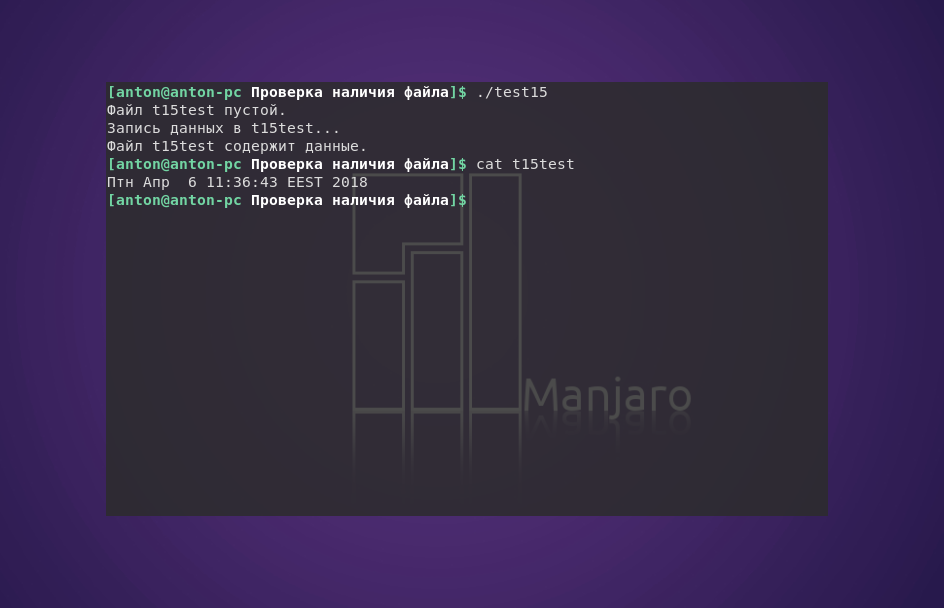
#!/bin/bash
file=t15test
touch $file
if [ -s $file ]
then
echo "Файл $file содержит данные."
else
echo "Файл $file пустой."
fi
echo "Запись данных в $file..."
date > $file
if [ -s $file ]
then
echo "Файл $file содержит данные."
else
echo "Файл $file все еще пустой."
fi
Результат работы программы:
В этом скрипте файл создаётся командой touch, и при первой проверке на пустоту возвращается отрицательный результат. Затем в него записываются данные в виде команды date, после чего повторная проверка файла возвращает истину.
Выводы
В статье была рассмотрена проверка существования файла bash, а также его пустоты. Обе функции дополняют друг друга, поэтому использовать их в связке - эффективный приём.
Хороший тон в написании сценариев командного интерпретатора - сначала определить тип файла и его дальнейшую роль в программе, а затем уже проверять объект на существование.
Существование сценариев, состоящих из отдельных команд, считается нормальным явлением. Но иногда возникают ситуации, когда этого становится недостаточно. Например, часто необходимо использовать данные от команды к команде, чтобы обработать информацию. С этой задачей помогают справиться переменные в скриптах.
В этой статье будут рассмотрены переменные в Bash скриптах с точки зрения области видимости, а также некоторые особенности при работе с ними.
Переменные среды Bash
Командный интерпретатор Bash поддерживает переменные среды, которые отслеживают различную системную информацию:
Имя системы;
Имя пользователя, зарегистрированного в системе;
Идентификатор пользователя (UID);
Исходный (домашний) каталог пользователя по умолчанию и т.п.
Для ознакомления с полным списком локальных переменных среды используется команда set.
set
Результат:
Значения этих переменных Bash можно использовать в сценариях, для чего необходимо указать имя переменной с предшествующим ей знаком доллара ($).
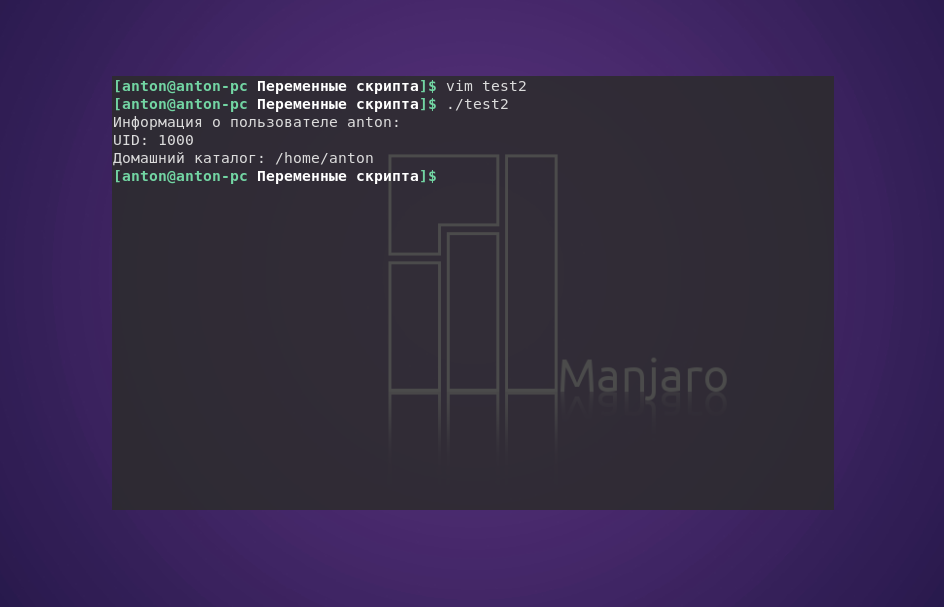
Переменные окружения Bash $USER, $UID и $HOME использовались для отображения запрашиваемой информации о текущем зарегистрированном пользователе.
Обратите внимание: переменные среды в командах echo заменяются их текущими значениями при выполнении программы. Кроме того, переменные, заключённые в кавычках, и вне их интерпретируются правильно.
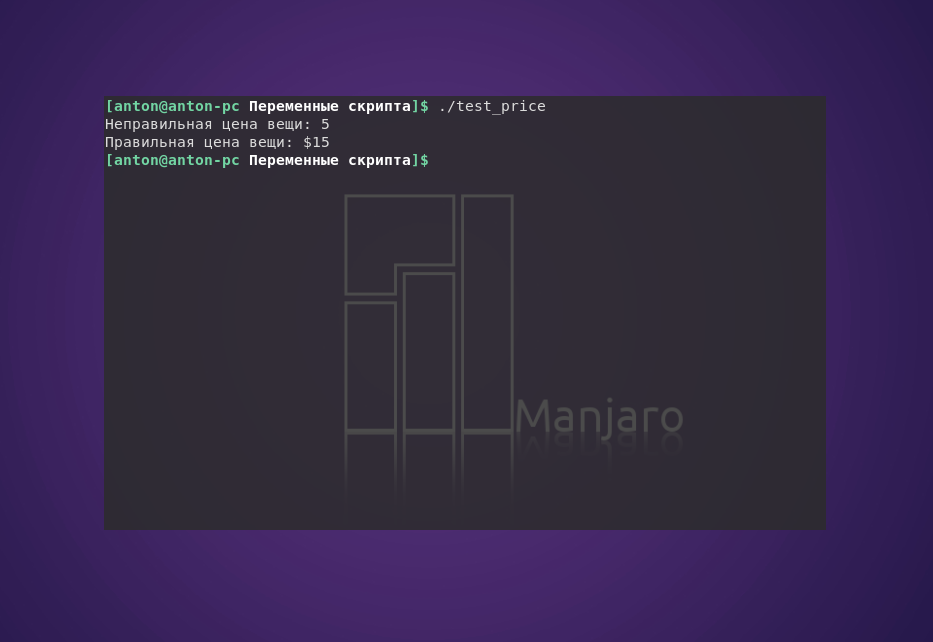
Однако в таком методе есть некоторый недостаток: при попытке отобразить какое-то денежное значение в долларовом эквиваленте необходимо добавить перед знаком доллара обратный слэш для его экранирования, чтобы интерпретатор не посчитал следующую за ним цифру именем переменной, принимающей параметр скрипта по указанному номеру.
В первой строке, где отображается неправильная цена, интерпретатор воспринял $ как знак начала переменной 1, которая считала первый параметр запущенной программы. Поскольку параметр ничего не содержал, то ничего и не было отображено вместо $1.
На заметку: частым случаем является использование фигурных скобок вокруг имени переменной после знака доллара (например ${variable}). Этот приём позволяет просто определить имя переменной, а на её функциональность это никак не влияет.
Пользовательские переменные Bash
В сценариях командного интерпретатора Bash можно не только использовать переменные среды, но также создавать и включать собственные. Задание переменных позволяет сохранять данные и использовать их во время работы скрипта, что делает его более интерактивным.
Пользовательские переменные Bash Linux могут быть названы любой текстовой строкой длиной до 20 символов, состоящей из букв, цифр и символа подчёркивания. В названии учитывается регистр букв, поэтому переменная Var1 не является переменной var1. Новички в области написания сценариев часто забывают об этой особенности, отчего и допускают трудно диагностируемые ошибки.
Присвоение значения переменной Bash выполняется с помощью знака равенства (=). Слева и справа от знака не должно быть разделяющих символов по типу пробела. Это правило также часто забывается неофитами. Вот пример присваивания значений переменным:
Ключевой особенностью интерпретатора Bash является автоматическое определение типа данных, используемого для представления значения переменных. После их определения сценарий сохраняет значения этих переменных на протяжении всего времени работы программы и уничтожает после её завершения.
На заметку: обращение к пользовательским переменным осуществляется так же, как и к системным, — с помощью знака доллара ($). Он не используется, когда переменной присваивается значение.
Выводы
Для обработки информации в сценариях командного интерпретатора используются переменные среды Bash и пользовательские переменные. Последние имеют жизнеспособность по умолчанию до тех пор, пока работает программа. При обращении к пользовательским переменным применяется знак доллара, а при записывании в них данных — нет.
Многие пользователи при установке Ubuntu по старой привычке или следуя некоторым руководствам создают отдельный раздел boot выделяя этому разделу слишком мало места (например, 300-500 МБ). Со временем, из-за накопления старых ядер Linux, при обновлении системы может возникнуть ошибка, сообщающая о нехватке места в /boot
В наше время сети IPv6 набирают очень большую популярность, и множество провайдеров даёт в комплекте с VPS подсеть IPv6 бесплатно. Допустим, вам нужно очень много адресов прокси, и у вас есть сервер с одним публичным адресом IPv4 и подсетью адресов IPv6. Используя эти адреса и прокси сервер Squid, вы можете очень просто получить необходимое количество прокси-серверов IPv6 .
Такие прокси не подходят для многих задач, но для проверки позиций сайта в поисковых системах они - самое то. В этой статье будет рассмотрена настройка Squid для IPv6. Базовая настройка Squid уже рассматривалась в статье установка Squid в Ubuntu.
Как это будет работать
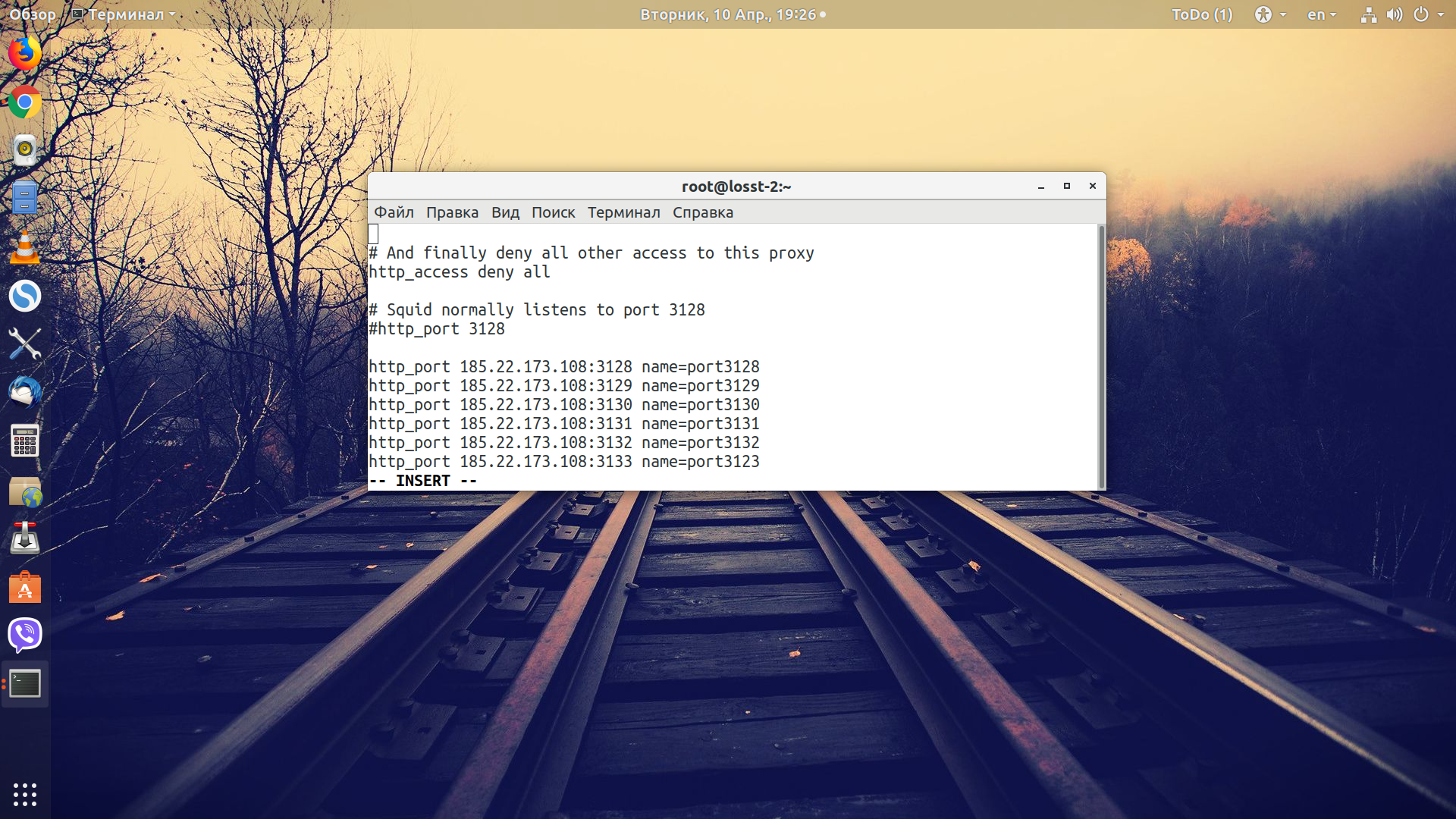
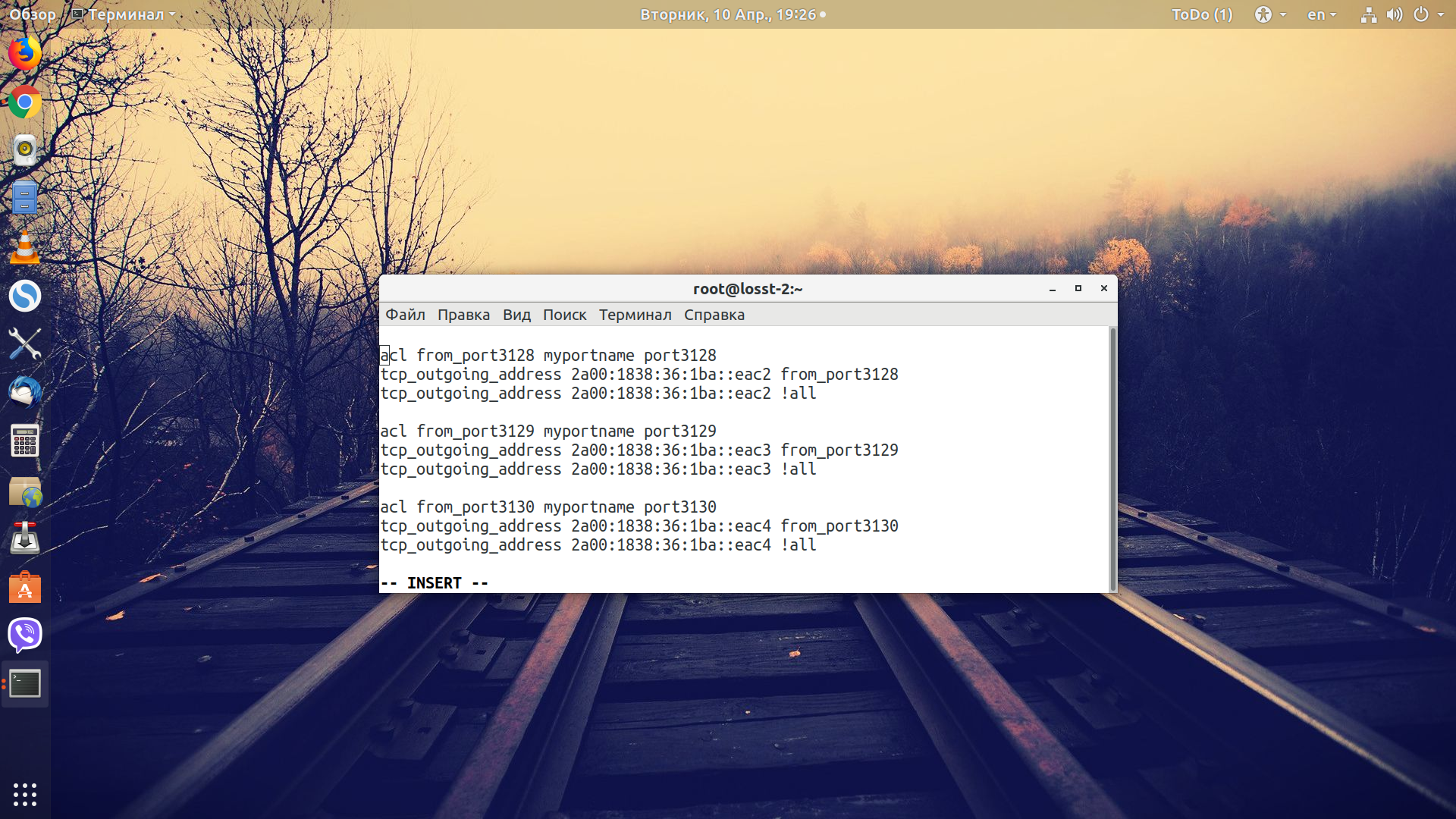
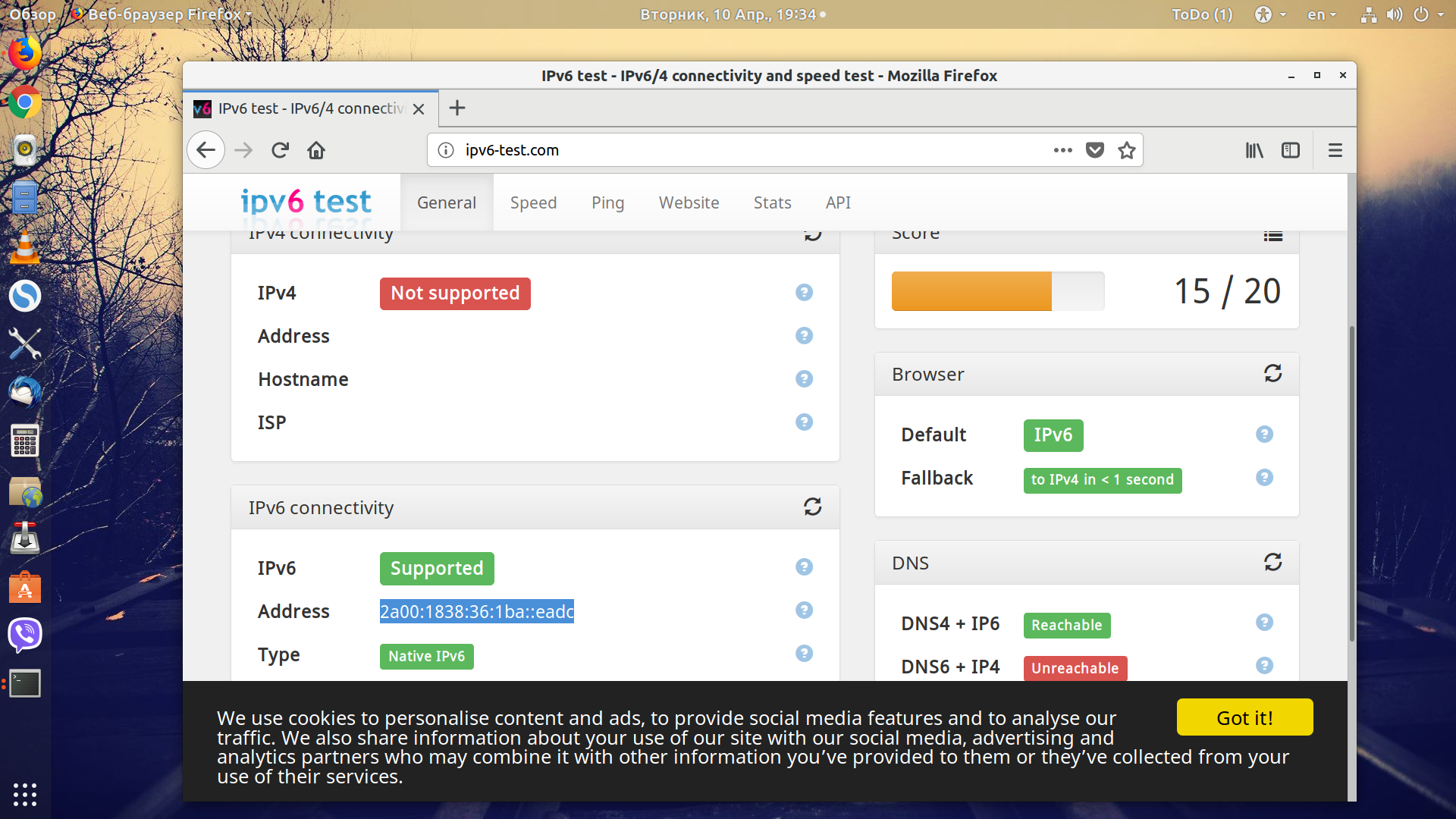
У вас есть только один IP-адрес IPv4, с помощью которого вы можете получить доступ к вашему прокси-серверу. Но нам как-то нужно определиться, какой адрес IPv6 для какого запроса будет использоваться. Для этого будем применять порты. Например, если мы подключаемся к порту 3128, то Squid будет отправлять запрос к сайту с адреса 2a00:1838:36:1ba::eac3, а если с порта 3129, то 2a00:1838:36:1ba::eac4 и так далее. Такие адреса можно добавлять до тех пор, пока производительность вашего сервера будет находится на приемлемом уровне.
Далее мы будем использовать аутентификацию по паролю, для того чтобы никто кроме вас не смог получить доступ к этим прокси-серверам. Отключим дополнительные заголовки, которые добавляет Squid, чтобы не светить ваш основной адрес. А также полностью выключим обращение к IPv4-сайтам, чтобы невозможно было отследить, что у всех этих адресов общий адрес IPv4. А теперь перейдем к настройке.
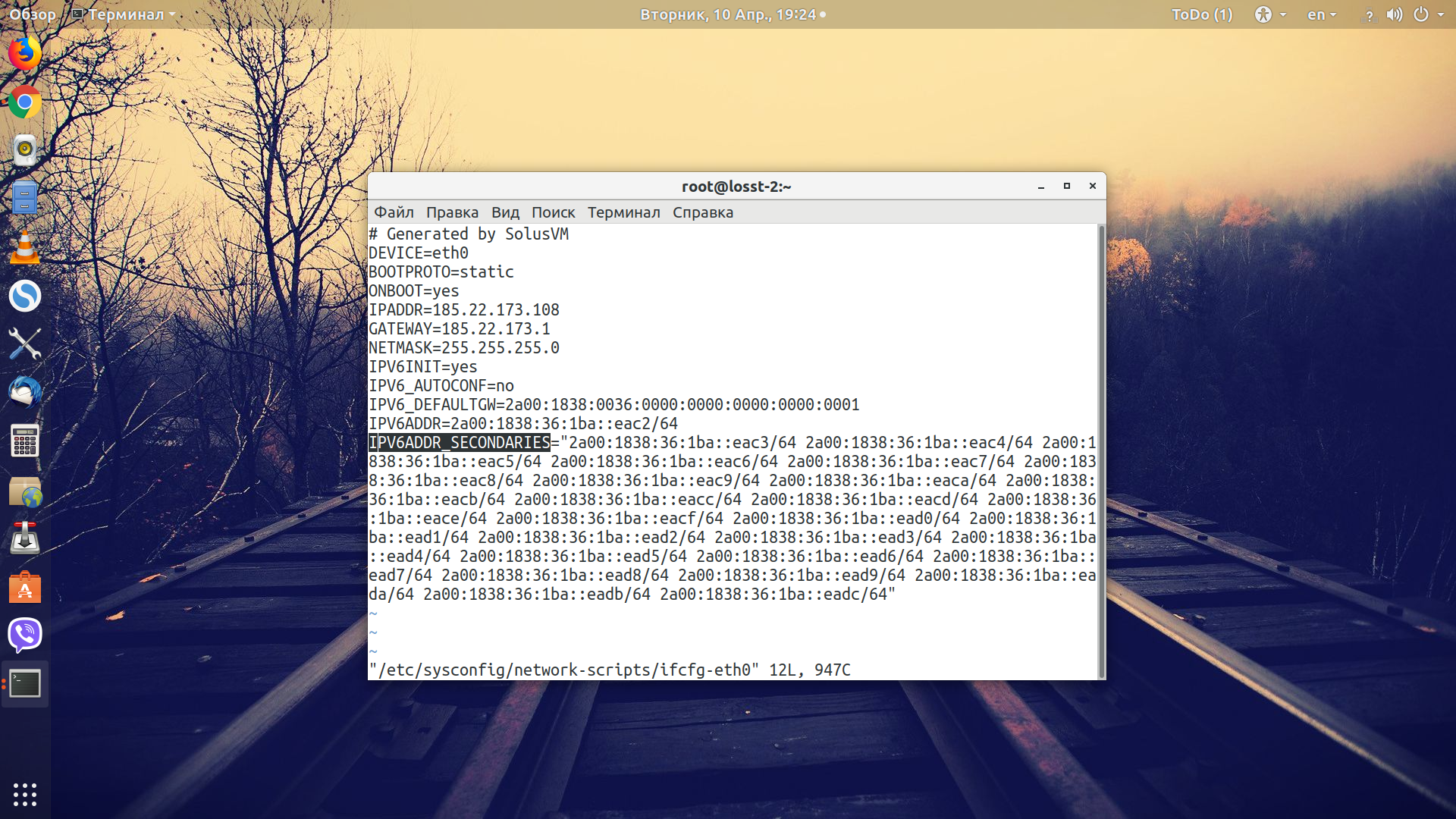
Настройка Squid для IPv6
Начнем с настройки адресов IPv6, обычно их советуют добавлять с помощью команды ip, но лучше прописать их в конфигурационном файле /etc/sysconfig/network-script/ifcfg-eth0, в строке IPV6ADDR_SECONDARIES:
Эти команды актауальны для CentOS 7, в Ubuntu всё будет выглядеть по другому. Далее настроим аутентификацию: для этого создаём файл пользователей и паролей с помощью команды htpasswd:
htpasswd /etc/squid/passwd
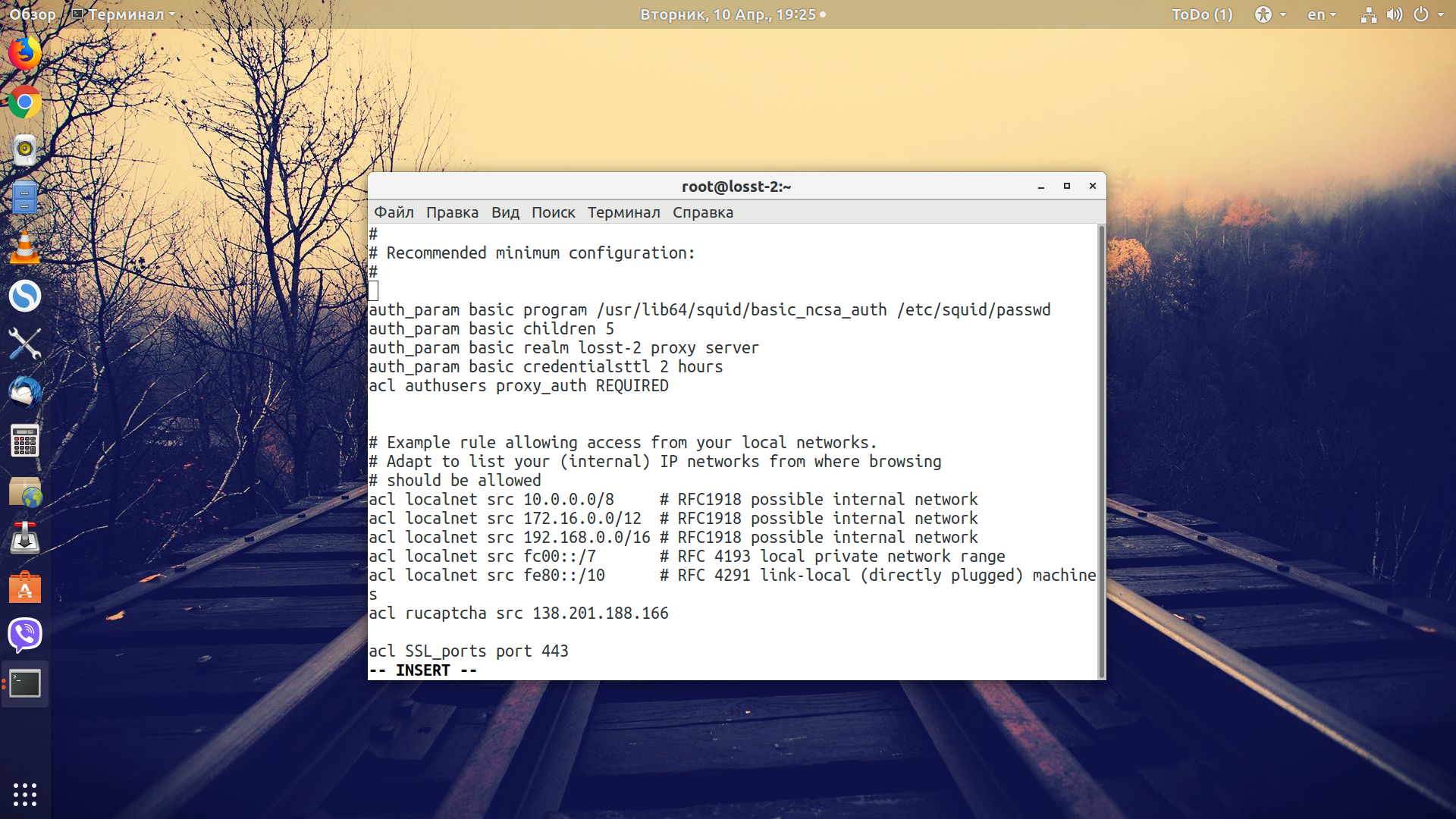
На запрос команды надо ввести логин пользователя и пароль для него. Только теперь мы можем перебраться к конфигурационному файлу Squid. Продолжаем настраивать аутентификацию, для этого добавьте в самом начале такие строки:
auth_param basic program /usr/lib64/squid/basic_ncsa_auth /etc/squid/passwd
auth_param basic children 5
auth_param basic realm kovalets proxy server
auth_param basic credentialsttl 2 hours
acl authusers proxy_auth REQUIRED
basic program - в первой строке мы загружаем модуль аутентификации /usr/lib64/squid/basic_ncsa_auth, в вашей системе путь к библиотеке может отличаться, вам надо найти правильный. В параметры модулю передаётся путь к файлу с паролями /etc/squid/passwd;
basic children - количество обрабатываемых за раз запросов;
basic realm - приветствие;
basic credentialsttl - время, на протяжении которого пользователь считается аутентифицированным.
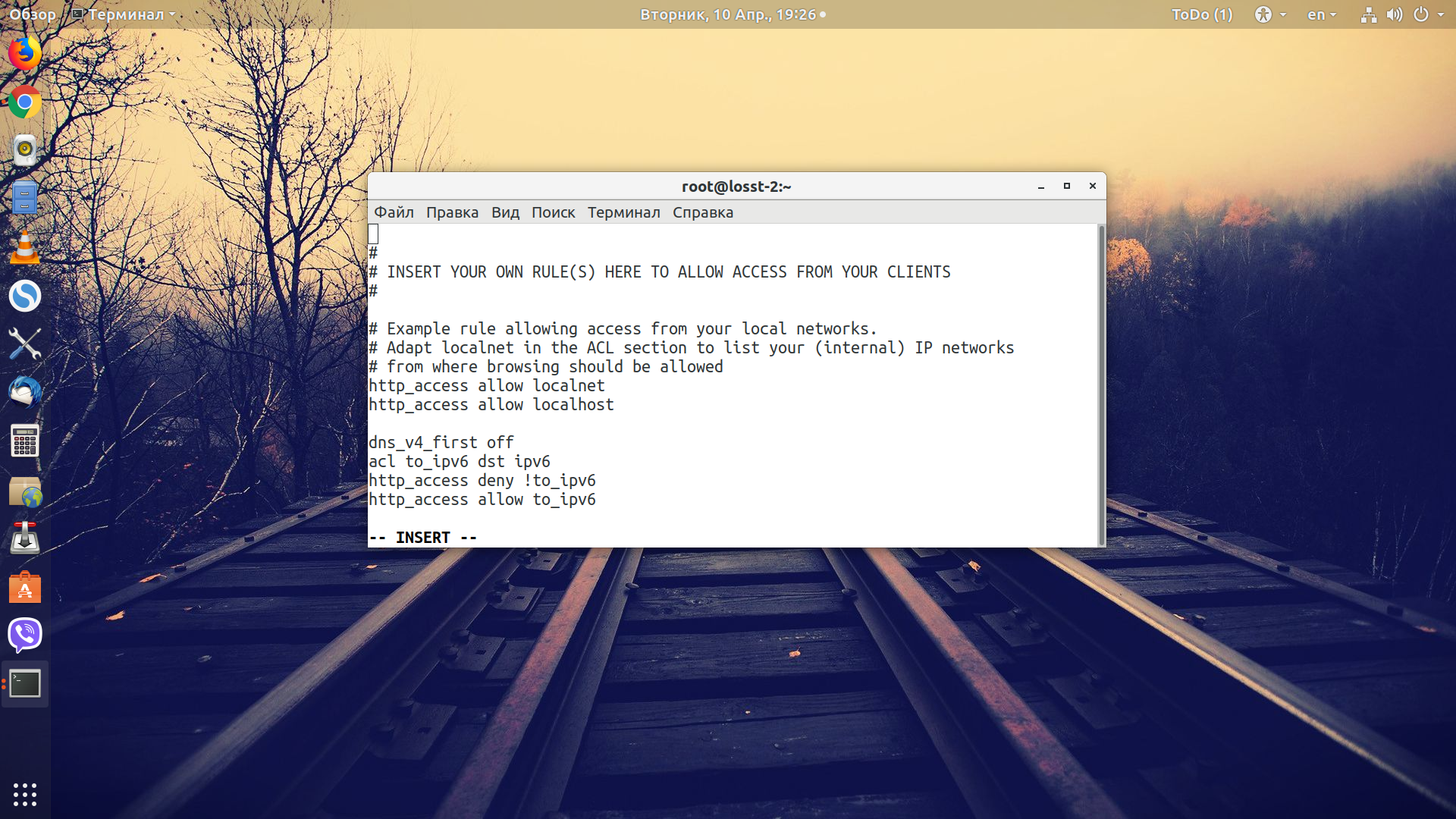
В последней строке мы создаем acl-список для всех аутентифицированных пользователей и позже с помощью него разрешим им доступ к нашему прокси. Дальше удаляем заголовки, которые нарушают приватность:
request_header_access X-Forwarded-For deny all
request_header_access Via deny all
request_header_access Proxy deny all
request_header_access Cache-Control deny all
Запрещаем все исходящие подключения, не через IPv6, с помощью acl-списков:
Теперь для каждого порта создаем acl-список, а затем с помощью директивы outgoing_ip_address указываем, через какой IP будет передаваться запрос во вне:
Теперь вы можете попытаться подключиться через ваш прокси, например, используя Firefox, и проверить, какой адрес используется. Обратите внимание, что сервис не может определить ваш адрес IPv6, а если бы мы не запретили запросы к IPv4, то любой ресурс мог бы подставить вам сайт, который не поддерживает IPv6. Squid просто взял бы его по IPv4, чем выдал бы свой адрес.
Выводы
В этой статье мы рассмотрели, как выполняется настройка Squid для IPv6 и использования нескольких исходящих IP-адресов. Конечно, решение описывать каждый порт и IP отдельно не очень удобно при больших объёмах, и что-то мне подсказывает, что можно решить задачу иначе, если вы знаете более эффективный способ, напишите в комментариях.
Функциональность интерпретатора Bash позволяет работать не только со статистическими данными, записанными в скриптах. Иногда возникает необходимость добавить сценарию интерактивности, позволяя принимать внешние параметры скрипта для манипуляции ими в коде.
В этой статье будет рассмотрено, как принимать аргументы командной строки bash, способы его обработки, проверка опций, а также известные особенности при работе с ними.
Параметры скрипта Bash
Интерпретатор Bash присваивает специальным переменным все параметры, введённые в командной строке. В их состав включено название сценария, выполняемого интерпретатором. Такие переменные называются ещё числовыми переменными, так как в их названии содержится число:
$0 — название сценария;
$1 — первый параметр;
...
$9 — девятый параметр сценария.
Ниже приведён пример использования одного параметра скрипта Bash:
#!/bin/bash
factorial=1
for (( number = 1; number <= $1 ; number++ ))
do
factorial=$[ $factorial * $number ]
done
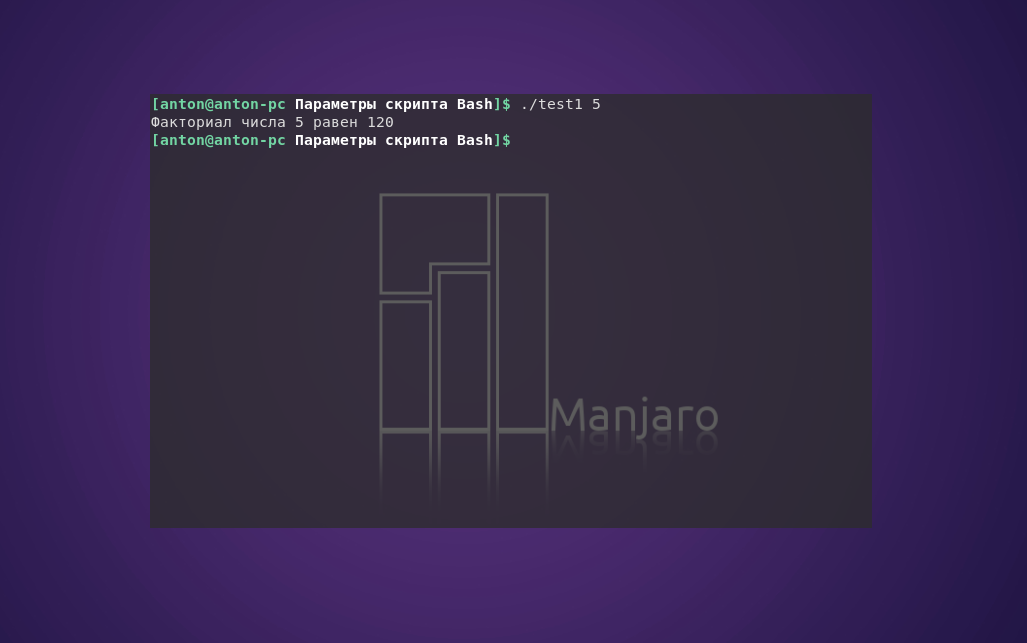
echo "Факториал числа $1 равен $factorial"
Результат работы кода:
Переменная $1 может использоваться в коде точно так же, как и любая другая. Скрипт автоматически присваивает ей значение из параметра командой строки — пользователю не нужно делать это вручную.
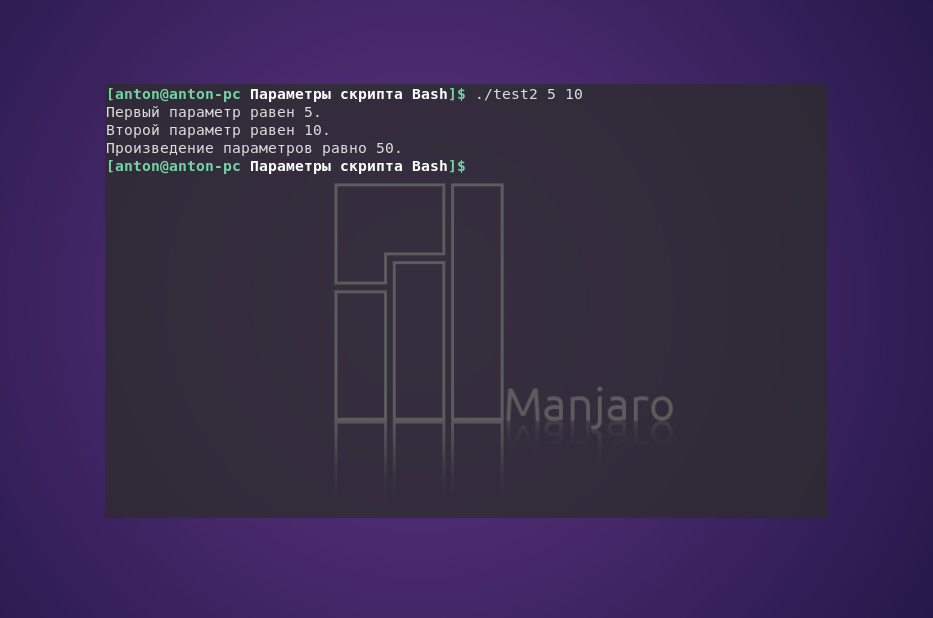
Если необходимо ввести дополнительные параметры, их следует разделить в командной строке пробелами.
Командный интерпретатор присвоил числа 5 и 10 соответствующим переменным — $1 и $2.
Также параметрами могут быть и текстовые строки. Однако, если есть необходимость передать параметр, содержащий пробел (например имя и фамилию), его нужно заключить в одинарные или двойные кавычки, так как по умолчанию пробел служит разделителем параметров командной строки:
#!/bin/bash
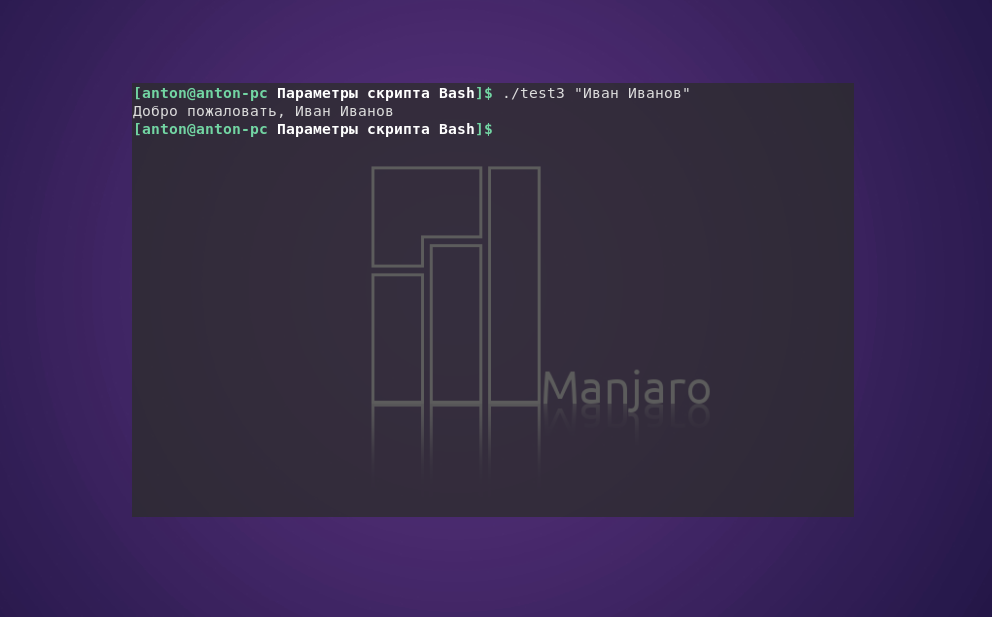
echo "Добро пожаловать, $1"
Пример работы кода:
На заметку: кавычки, которые используются при передаче параметров, обозначают начало и конец данных и не являются их частью.
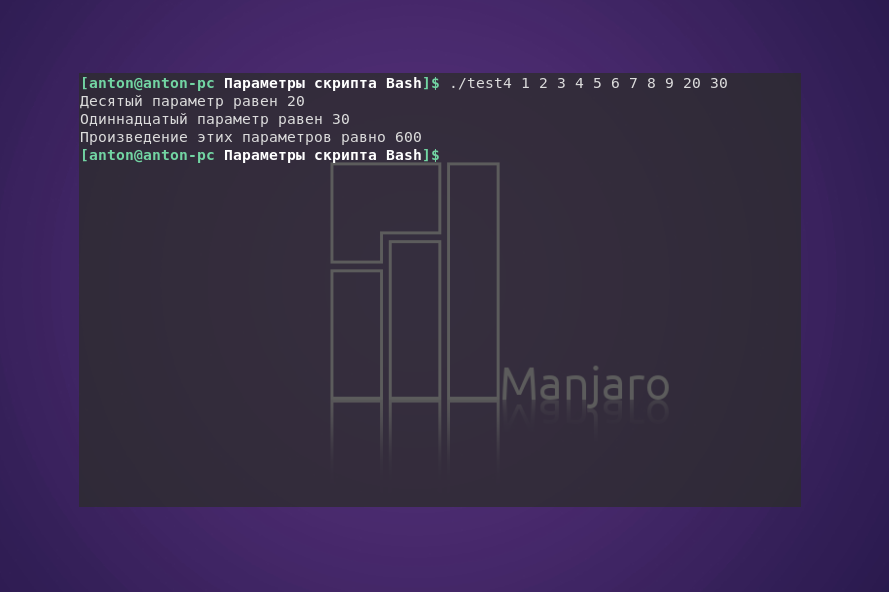
Если необходимо использовать больше 9 параметров для скрипта, то названия переменных немного изменятся. Начиная с десятой переменной, число, стоящее после знака $, необходимо заключать в квадратные скобки (без внутренних пробелов):
Как уже упоминалось, имя сценария является самым первым параметром скрипта. Чтобы определить название программы, используется переменная $0. Такая необходимость возникает, например, при написании скрипта, который может выполнять несколько функций. Однако при этом возникает одна особенность, которую нужно учитывать на практике:
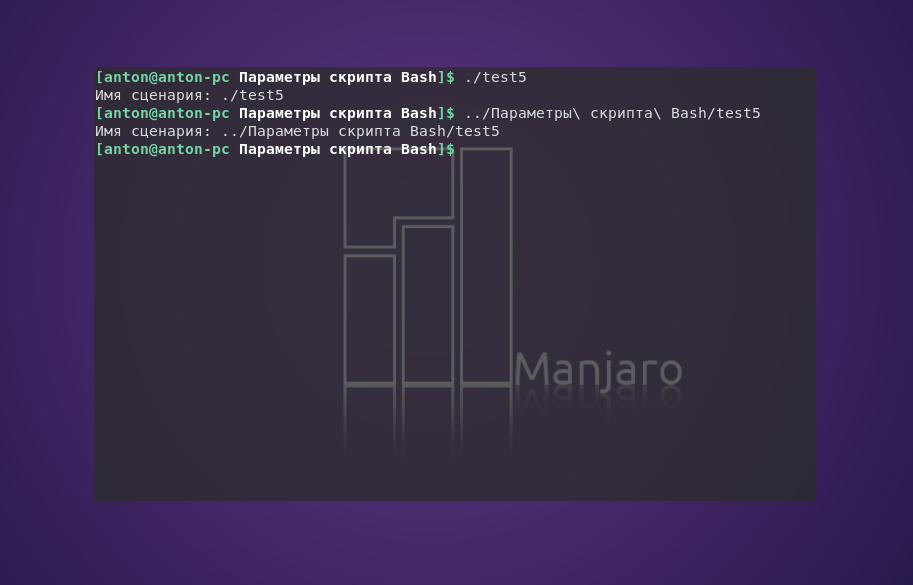
#!/bin/bash
echo "Имя сценария: $0"
Пример работы кода:
Как видно, если строкой, фактически переданной в переменную $0, является весь путь к сценарию, то на вывод будет идти весь путь, а не только название программы.
Если нужен скрипт, выполняющий различные функции с учётом того, под каким именем он был вызван из командной строки, придётся проделать дополнительную работу: удалить сведения о пути, который использовался для его вызова.
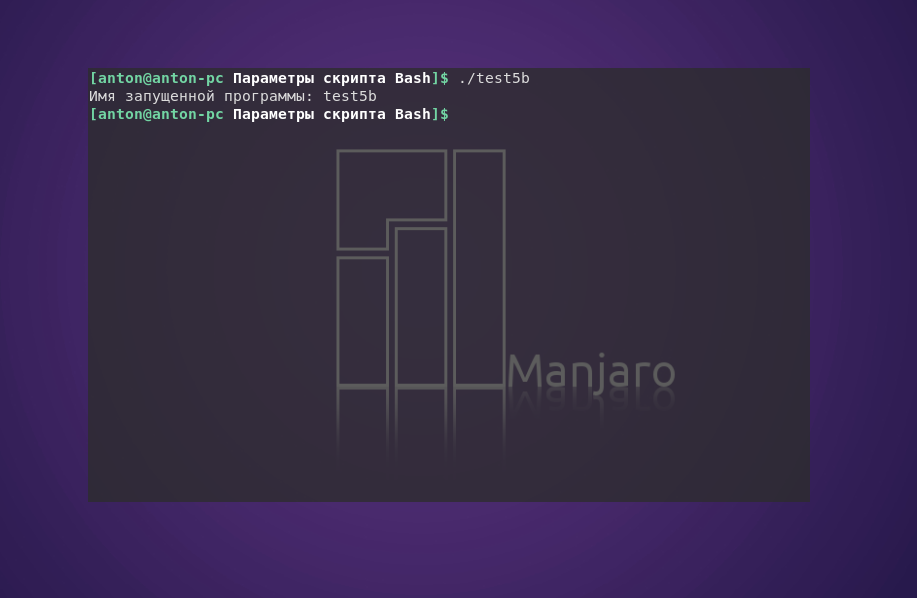
Для этого специально предусмотрена небольшая команда. Команда basename возвращает только название скрипта без абсолютного или относительного пути к нему:
Передача параметров Bash вынуждает соблюдать осторожность. Если сценарий написан с применением параметров, но запускается без них, то возникнут проблемы в работе программы.
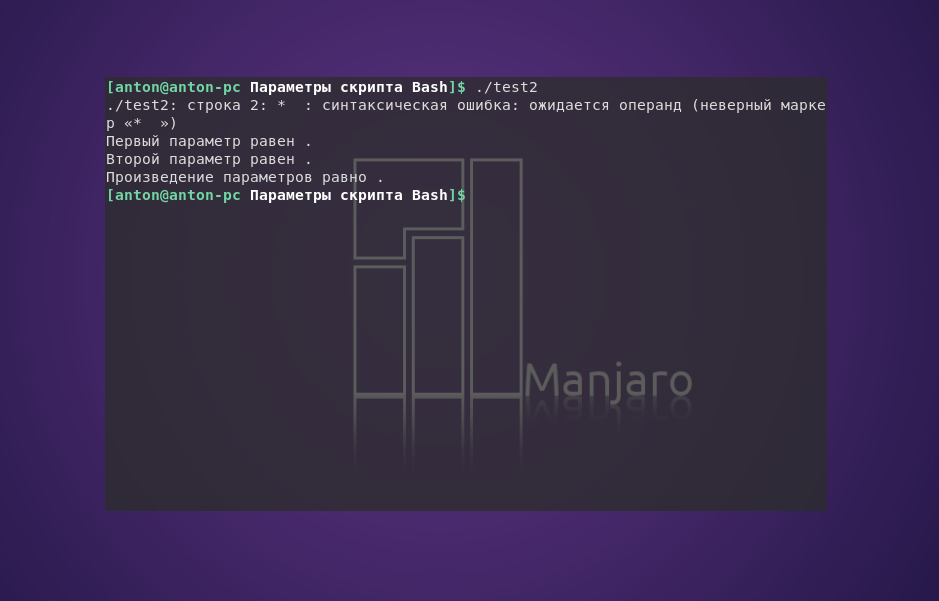
Если попробовать запустить написанный ранее скрипт test2 без аргументов, то перед выводом команд echo будет отображена ошибка:
Чтобы предотвращать подобные ситуации, необходимо действовать на упреждение — проверять аргументы скрипта на наличие значений. Это настоятельная рекомендация при использовании параметров в командной строке, и только после ревизии стоит пускать их в дело:
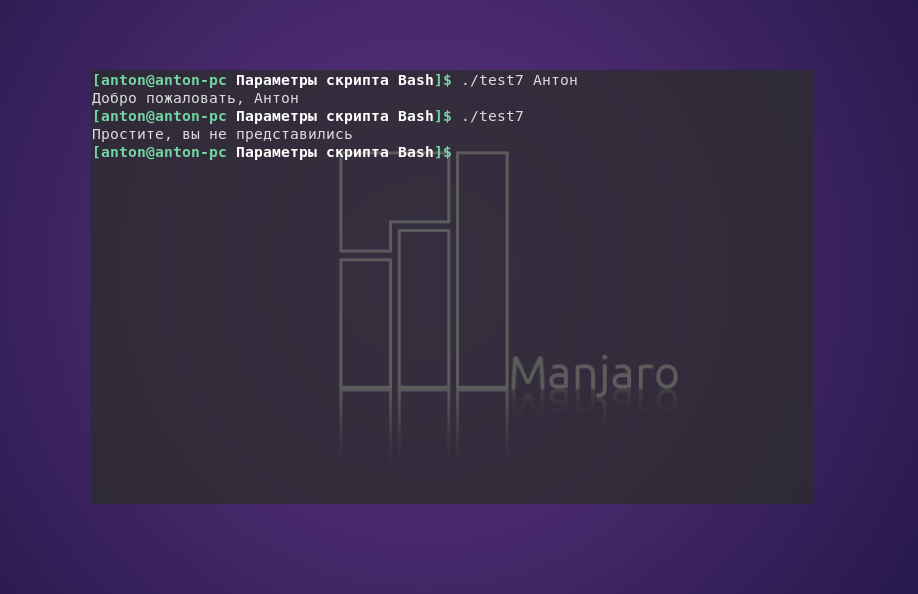
#!/bin/bash
if [ -n "$1" ]
then
echo "Добро пожаловать, $1"
else
echo "Простите, вы не представились"
fi
Пример работы кода:
В данном случае использовалась опция -n из предыдущей статьи о сравнении строк в Bashдля проверки на наличие значения в переменной, которая считала параметр.
Обработка неизветсного числа параметров
Для начала рассмотрим один из часто используемых инструментов при работе с параметрами Bash — команду shift. Её прямое назначение заключается в сдвиге параметров на одну позицию влево. Таким образом, значение из переменной $3 переместится в $2, а из $2 — в $1. Но из $1 значение просто отбросится и не сместится в $0, так как там неизменно хранится название запущенной программы.
Эта команда является эффективным способом обработки всех параметров, переданных сценарию, особенно, когда нельзя заранее узнать их количество. Достаточно лишь обработать $1, сделать сдвиг и повторить процедуру.
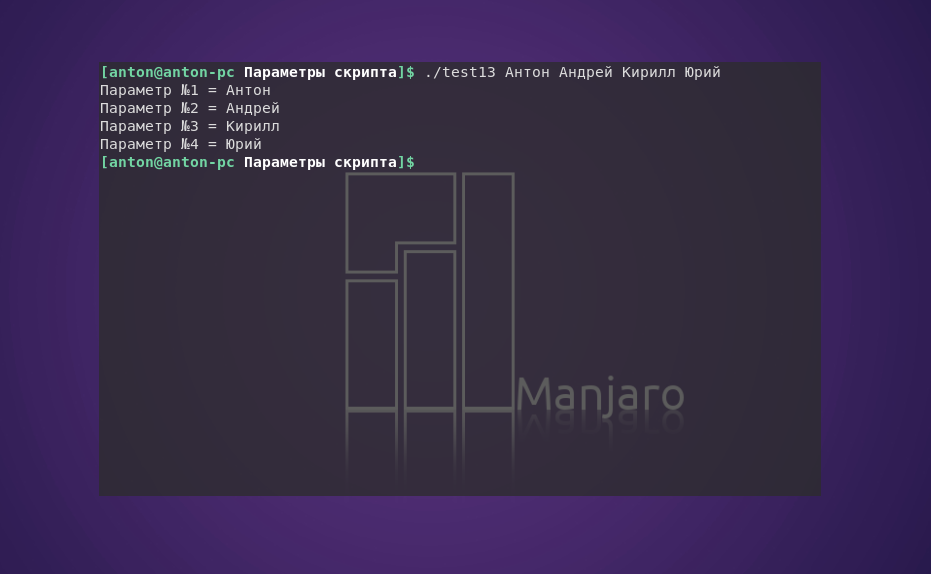
#!/bin/bash
count=1
while [ -n "$1" ]
do
echo "Параметр №$count = $1"
count=$[ $count + 1 ]
shift
done
Пример работы кода:
Этот скрипт выполняет цикл while, в условии которого указана проверка первого параметра на длину. И если она равна нулю, цикл прерывает свою работу. При положительном результате проверки команда shift сдвигает все параметры влево на одну позицию.
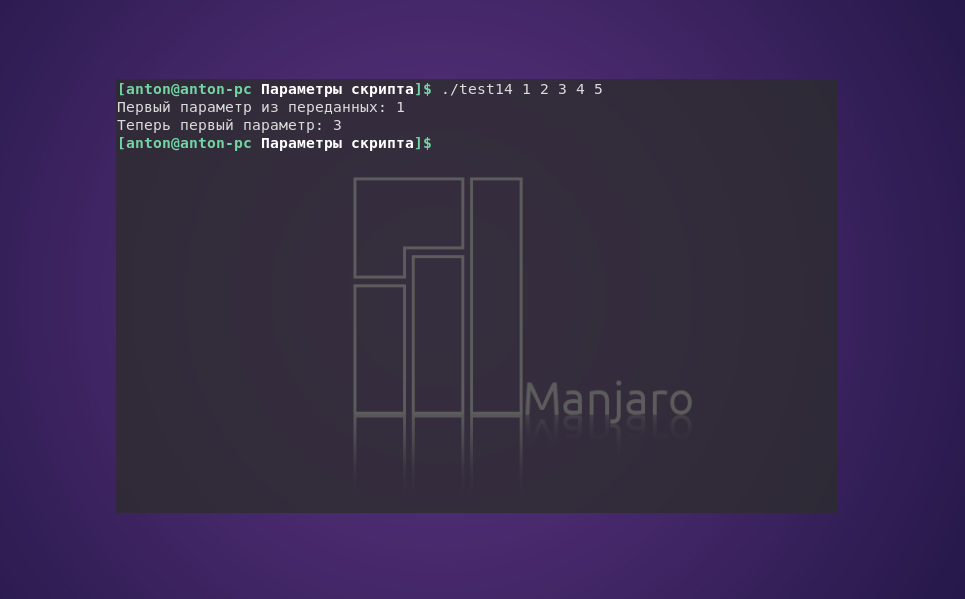
Ещё один вариант использование shift — смещать на несколько позиций. Для этого достаточно через пробел указать количество, на которое будет смещён ряд параметров скрипта.
#!/bin/bash
echo "Первый параметр из переданных: $1"
shift 2
echo "Теперь первый параметр: $1"
Пример работы скрипта:
На заметку: при использовании shift нужно быть осторожным, ведь сдвинутые за пределы $1 параметры не восстанавливаются в период работы программы.
Обработка опций в Bash
Помимо параметров скрипт может принимать опции — значения, состоящие из одной буквы, перед которыми пишется дефис. Рассмотрим 3 метода работы с ними в скриптах. Сперва кажется, что при работе с опциями не должно возникать каких-либо сложностей. Они должны быть заданы после имени запускаемой программы, как и параметры. При необходимости можно сделать обработку опций командной строки по такому же принципу, как это делается с параметрами.
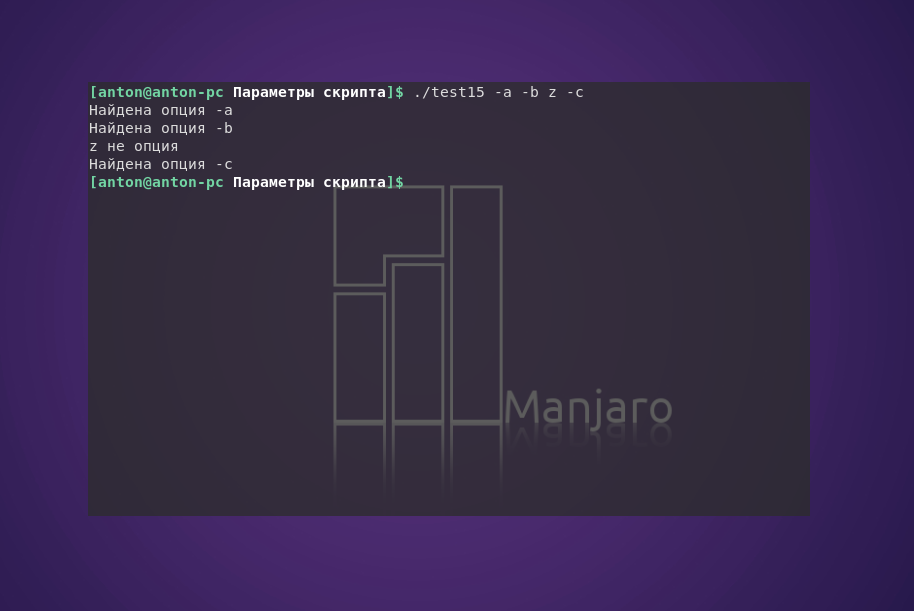
По примеру выше можно применять shift для обработки простых опций. С помощью инструкции case можно определять, являются ли аргументы Bash опциями:
#!/bin/bash
while [ -n "$1" ]
do
case "$1" in
-a | -b | -c) echo "Найдена опция $1" ;;
*) echo "$1 не опция" ;;
esac
shift
done
Пример работы программы:
Блок case работает правильно вне зависимости от того, как расположены аргументы командной строки bash.
Выводы
Для того, чтобы сделать свою программу более интерактивной, можно использовать параметры Bash. Встроенные переменные, в названиях которых фигурирует число, обозначают порядок указанных для программы параметров.
Команда basename используется для обрезания пути запущенного сценария, что часто необходимо для создания гибких программ. Использование команды shift позволяет эффективно проходить по переданным скрипту параметрам, особенно когда их количество неизвестно.
MySQL - это самая популярная система баз данных, которая используется для обеспечения работы большинства сайтов. Пока вы размещаете свой сайт на хостинге, вам нет необходимости думать о её настройке или своевременной перезагрузке, потому что этим занимаются системные администраторы хостинга. Но когда вы переберётесь на VPS, это всё будет уже в зоне вашей ответственности.
В этой статье мы рассмотрим, как выполняется перезапуск MySQL в разных дистрибутивах Linux, а также как сделать, чтобы MySQL перезапускалась автоматически после падения.
Linux Mint - один из распространённых дистрибутивов Linux, основанный на Ubuntu. Долгое время он занимал первом месте в рейтинге популярных дистрибутивов по версии веб-сайта DistroWatch. Основатели, Клемент Лефевр и команда разработчиков "Mint Linux Team", ставили перед собой цель создать удобный, мощный и простой в использовании дистрибутив Linux, и у них это получилось!
Однако несмотря на всю простоту использования и настройку системы, поначалу у многих пользователей возникают проблемы с установкой нового программного обеспечения. В Linux установка новых программ выполняется из репозиториев с помощью специальных пакетов, и в этой статье мы рассмотрим различные способы установки программ в Linux Mint.