Ваш путеводитель по одной из самых популярных и влиятельных операционных систем в мире. От базовых команд и установки дистрибутивов до глубокого изучения ядра и сетевых технологий — здесь вы найдете статьи и руководства на самые разные темы, связанные с Linux. Независимо от вашего уровня подготовки, здесь найдется что-то интересное и полезное.
Если вы захотите настроить резервное копирование базы данных на другой сервер, или протестировать соединение с базой данных из другого сервера. И тогда вы можете столкнуться с ошибкой access denied for user root localhost, даже если вы указали верное имя пользователя, базу данных и пароль.
В этой небольшой статье мы рассмотрим почему возникает эта ошибка, а также как ее исправить и подключиться к MySQL из другого сервера через интернет.
Что означает access denied for user root localhost?
Если переводить дословно, то эта ошибка означает что у вас нет доступа к данной базе данных от имени этого пользователя. В примере я использовал пользователя root, но вы можете использовать и другого пользователя. Это может быть вызвано несколькими причинами:
Пароль введен неверно;
По каким-либо причинам у пользователя нет прав на доступ к базе данных;
В настройках этого пользователя запрещено авторизоваться с этого сервера;
Для безопасности базы данных в mysql была придумана настройка хоста, из которого пользователь может авторизоваться. По умолчанию для пользователей устанавливается разрешение на авторизацию только с localhost. Чтобы разрешить подключение с других хостов, нужно менять настройки. Рассмотрим как это делается с помощью Phpmyadmin и в терминале.
Исправляем ошибку access denied for user root localhost
1. Подключение с другого хоста
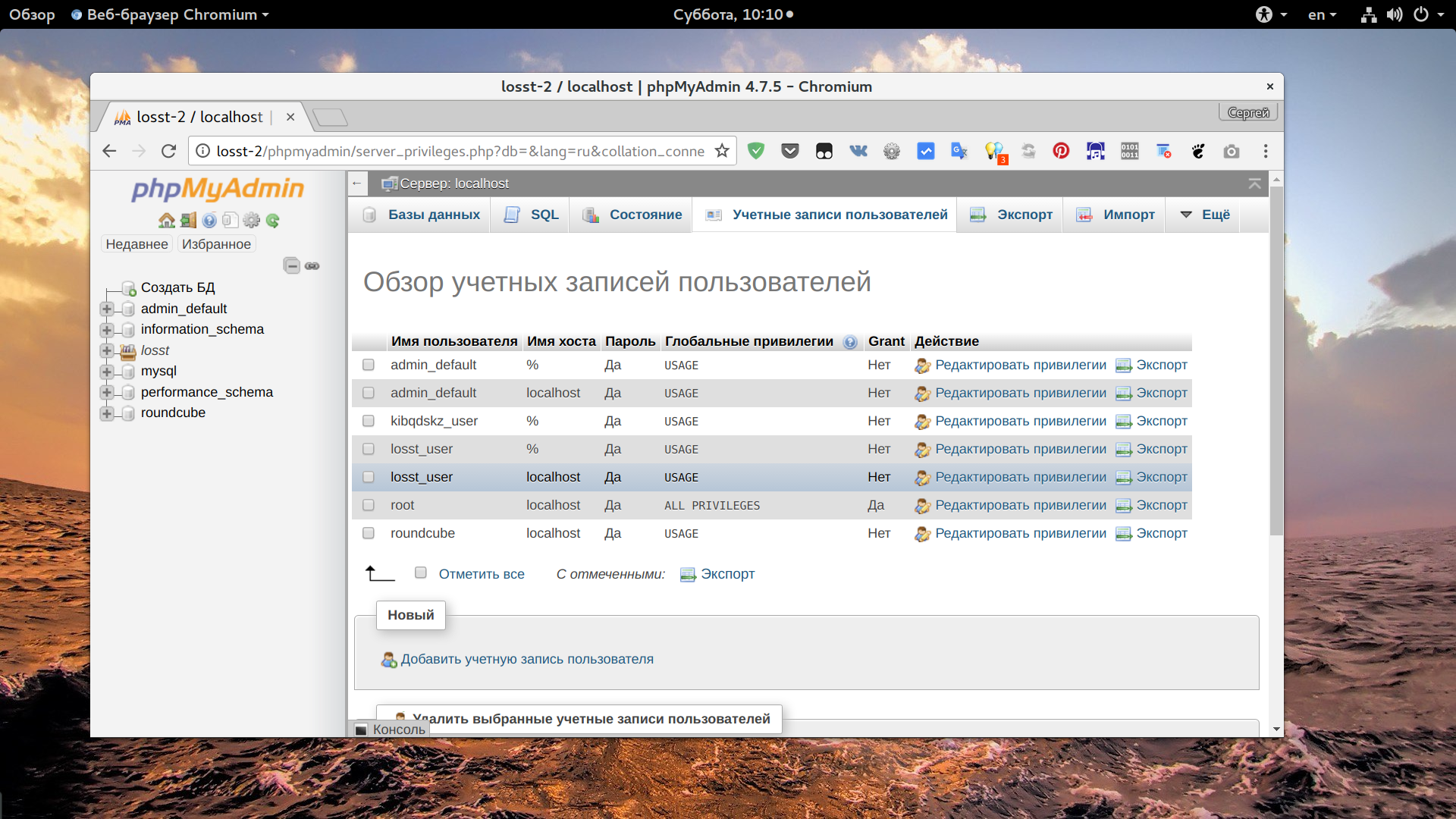
Сначала рассмотрим как работать с Phpmyadmin. Это намного проще для начинающих и тех, кто не любит работать в терминале. Откройте Phpmyadmin, авторизуйтесь в программе с правами root и перейдите на вкладку "Учетные записи пользователей":
Здесь, вы увидите, кроме обычных полей, поле "имя хоста", которое указывает с какого хоста может подключаться пользователь. Если в этом поле написано localhost, значит этот пользователь может авторизоваться только с локальной машины. Также, в этом поле может находиться IP адрес, с которого есть разрешение или символ %, который означает, что пользователь может подключаться с любого IP.
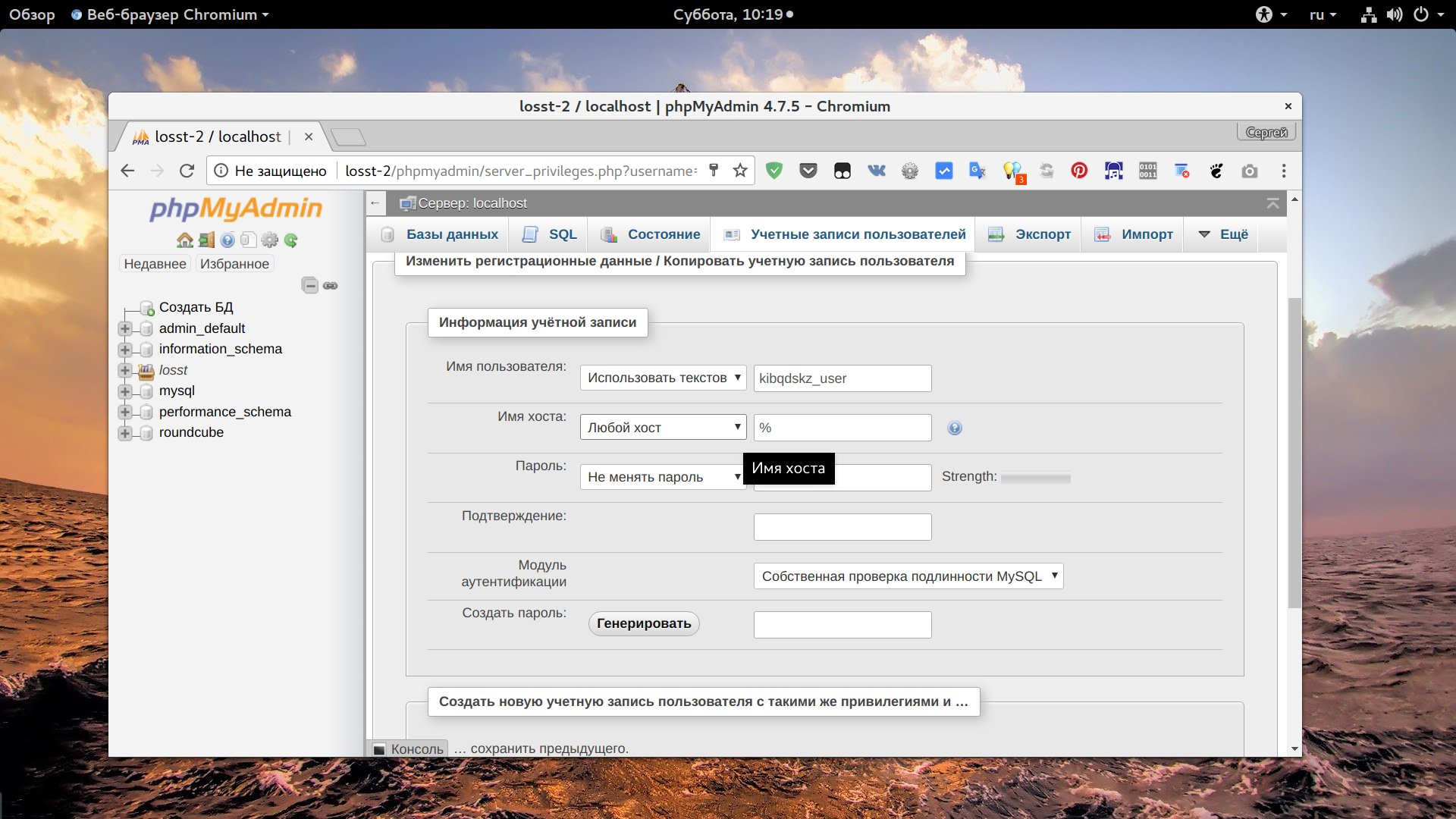
Чтобы изменить права для пользователя, нужно нажать на ссылку "Редактировать привилегии" для него, на открывшейся странице перейдите на вкладку "Информация об учетной записи":
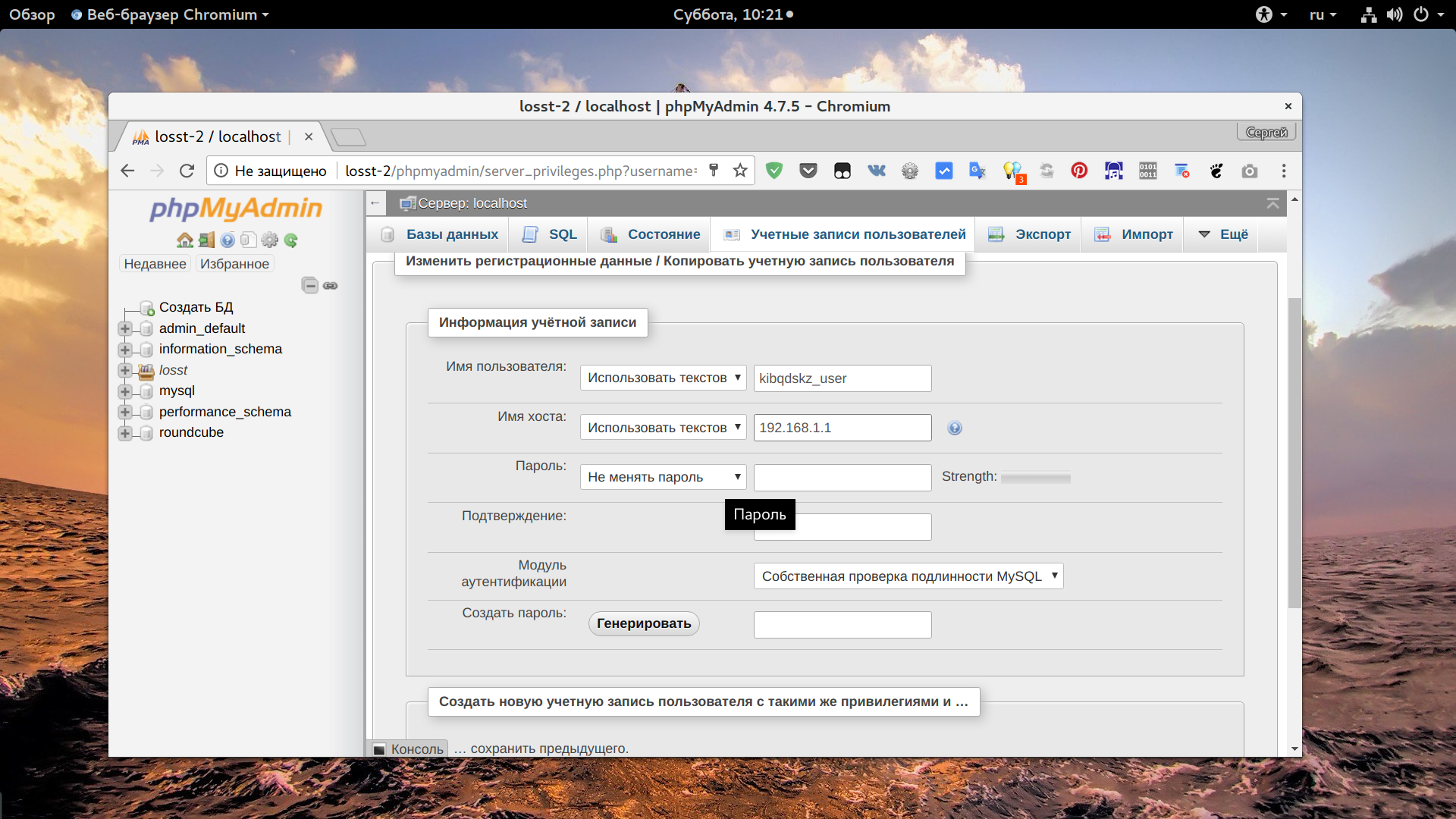
Затем установите в поле "Имя хоста" значение "Любой хост" чтобы разрешить этому пользователю авторизоваться с любого IP. Если вы хотите разрешить только определенный IP, выберите "Использовать текстовое поле" и укажите нужный адрес или подсеть:
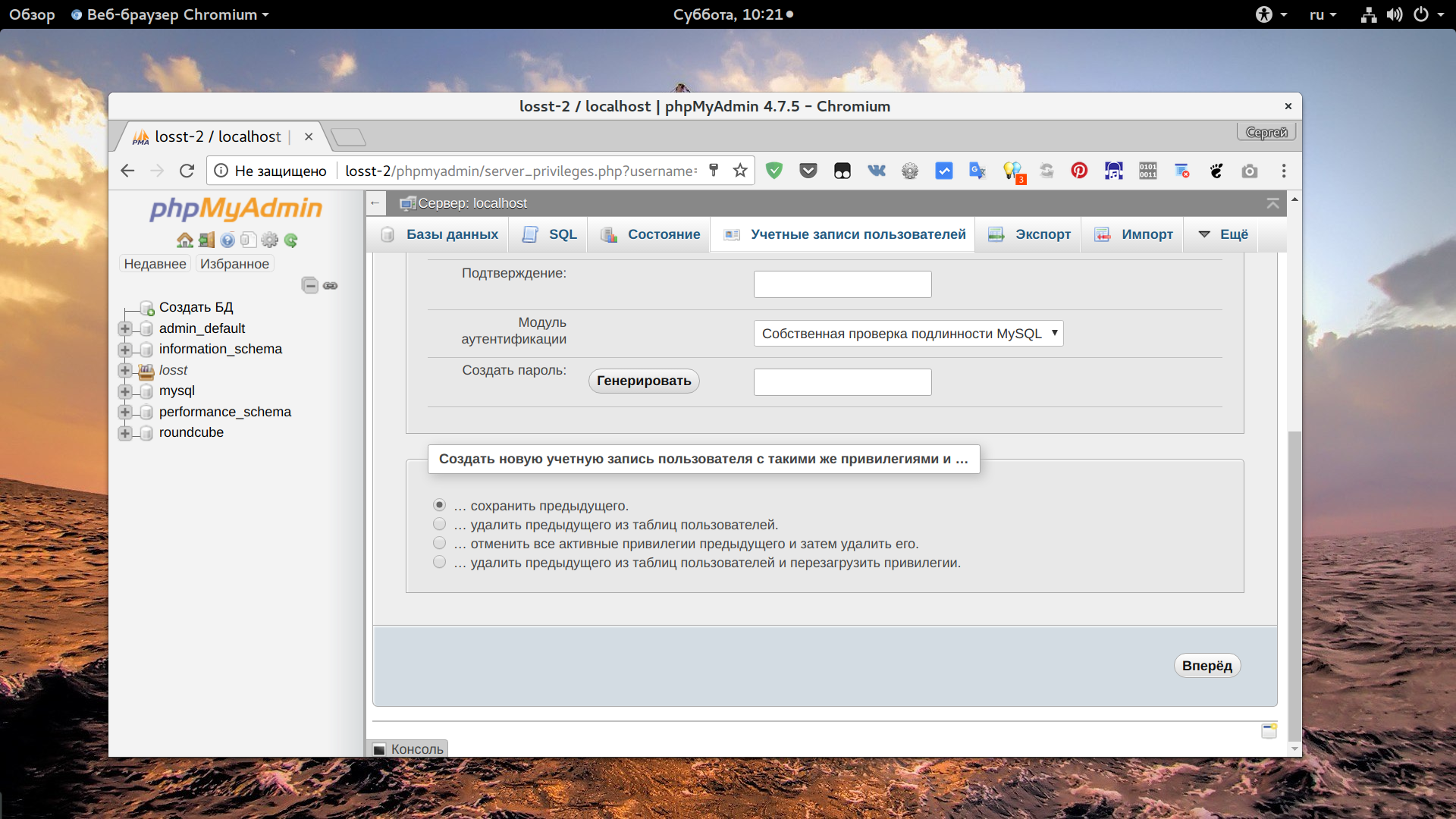
После этого останется нажать кнопку "Вперед" чтобы сохранить настройки. Если вам нужно чтобы был доступ и с локального IP, и с другого, то необходимо создать еще одного пользователя. После этого вы сможете авторизоваться от имени этого пользователя.
Теперь рассмотрим другой способ решить ошибку 1045 access denied for user root localhost, с помощью терминала. Это немного проще, поскольку вам нужно только выполнить несколько команд:
mysql
> UPDATE mysql.user SET Host='%' WHERE Host='localhost' AND User='имя_пользователя';
> UPDATE mysql.db SET Host='%' WHERE Host='localhost' AND User='имя_пользователя';
> FLUSH PRIVILEGES;
Уже после этого, вы можете подключаться к серверу баз данных с любого другого компьютера и не получите никаких ошибок. Вместо символа %, можно указать нужный ip или localhost, если ограничение нужно вернуть обратно.
2. Неверный пароль root
Иногда случается, что при установке базы данных пароль для root задается, но вы его не знаете. Поскольку это главный пользователь и если вы не можете войти от его имени, то вы не сможете ничего исправить. Сначала попробуйте авторизоваться от имени root в системе и подключиться к базе без пароля:
mysql
Иногда это работает. Если не сработало, остановите службу mysql и запустите ее без проверки безопасности, а затем попробуйте снова:
systemctl stop mysqld mysqld --skip-grant-tables mysql
> USE mysql;
> UPDATE user SET Password=PASSWORD('ваш_пароль') where USER='root';
> FLUSH PRIVILEGES;
Еще можно попытаться выдать права над всеми таблицами нашему пользователю, если это необходимо:
> GRANT ALL ON *.* TO 'root'@'localhost' WITH GRANT OPTION;
Обратите внимание на хост localhost, если вы хотите чтобы удаленные узлы тоже могли подключаться к этому пользователю, то нужно использовать %. Дальше можно перезапустить базу данных и работать как обычно.
Выводы
Теперь вы знаете как решается mysql access denied for user root localhost и что делать в таких ситуациях, чтобы решить проблему. Надеюсь, эта информация была полезной для вас. Если у вас остались вопросы, спрашивайте в комментариях!
Зачастую первое действие, которое выполняют фотографы в процессе обработки фотографий является кадрирование. Иными словами нужно обрезать фото, отбросить все лишнее, чтобы внимание зрителя при просмотре фото акцентировалось в нужном месте. Затем откадрированное изображение можно распечатать, поместить в рамку и повесить на стену, чтобы яркие впечатления о путешествиях наполняли вас положительной энергией долгими зимними вечерами.
Как и в любом другом редакторе в gimp имеется инструментарий для обрезки изображений. Как обрезать фото в gimp. Как это сделать удобным способом. Как добиться наилучшего результата и какие инструменты нам в этом помогут. Вот об этом мы сегодня и поговорим.
Обрезка изображения в Gimp
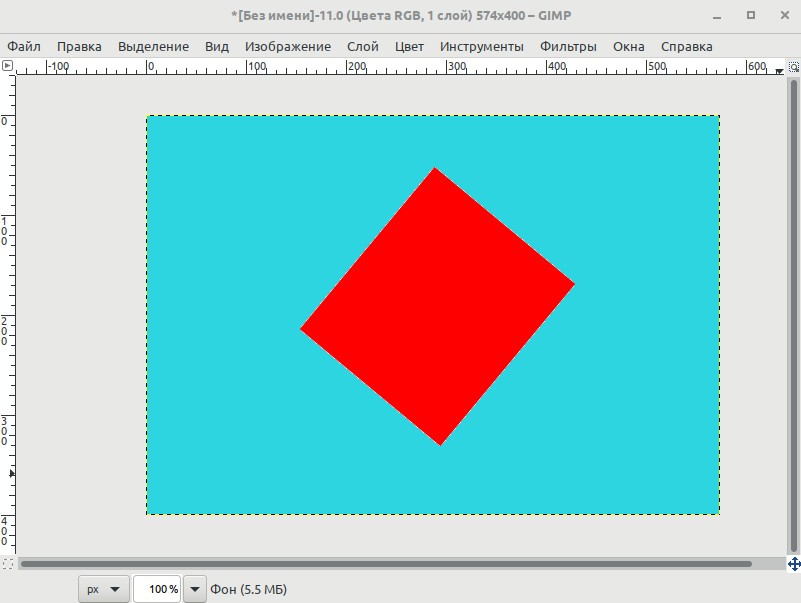
Наша цель обрезать изображение в Gimp по контуру представленному на следующем изображении.
Чтобы потом поместить фото в рамку и повесить на стену.
За обрезку изображений в GIMP отвечает инструмент “Кадрирование”, на панели инструментов его кнопка имеет изображение скальпеля:
Всплывающая подсказка дает нам краткое описание того, что делает этот инструмент и сочетание клавиш на клавиатуре для его вызова:
Активировать инструмент “Кадрирование” можно 3-я способами:
Через основное меню gimp: Инструменты/Преобразование/Кадрирование;
Соответствующая кнопка на панели инструментов: ;
Сочетание клавиш Shift + C.
В зависимости от стиля работы в gimp можно выбрать наиболее подходящий для работы метод выбора инструмента. Кому-то нравится кликать мышкой по панели инструментов, но есть и такие кому удобней нажать Shift+C.
Обрезка изображения выделением
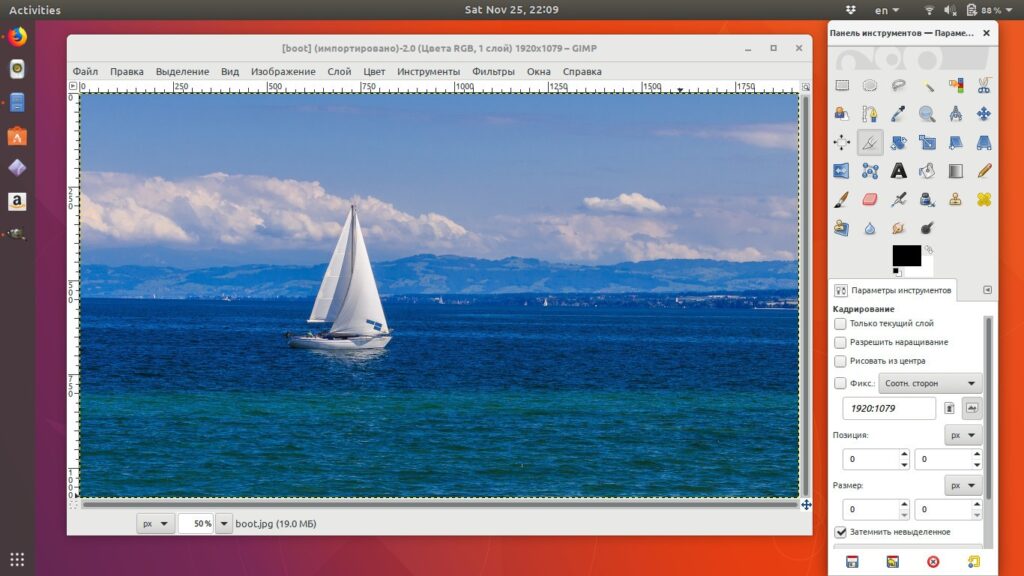
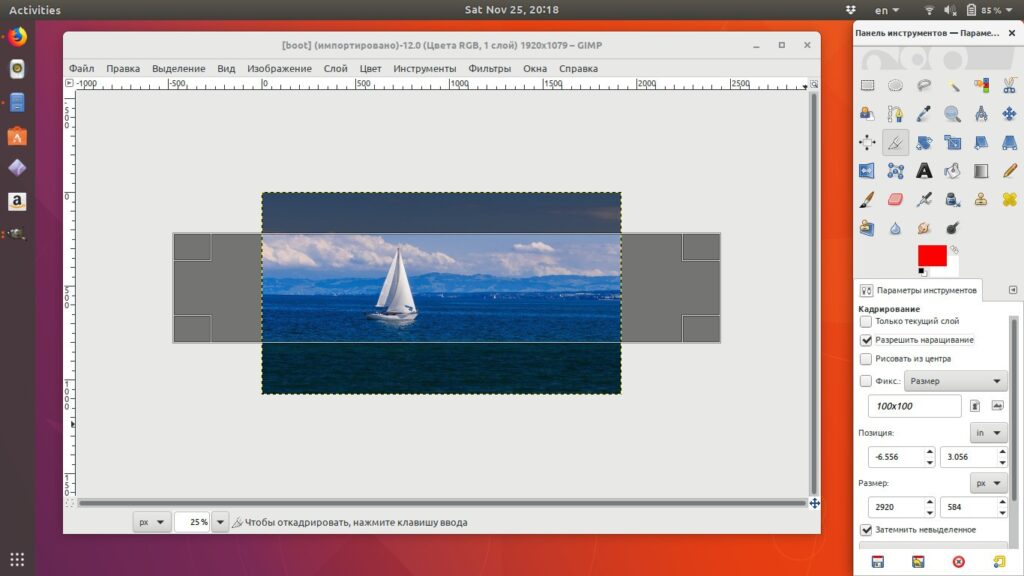
Для примера возьмем фотографию яхты и попробуем обрезать изображение с помощью инструмента “Кадрирование”. Предположим, что мы хотим сделать яхту покрупнее, а часть неба и моря вокруг просто отбросить.
Для этого активируем инструмент “Кадрирование” одним из трех способов, описанных выше. Курсор мышки сразу поменяется (появится изображение скальпеля).
Зажимаем правую кнопку мыши и рисуем мышкой прямоугольную область, которую мы хотим оставить. При этом выделенная часть изображения будет иметь яркость, как в оригинале, а вот та часть изображения, которую мы собираемся отбросить, будет затемлена. Это сделано не случайно, при этом очень удобно оценить будущее (обрезанное изображение) и его положение внутри оригинала.
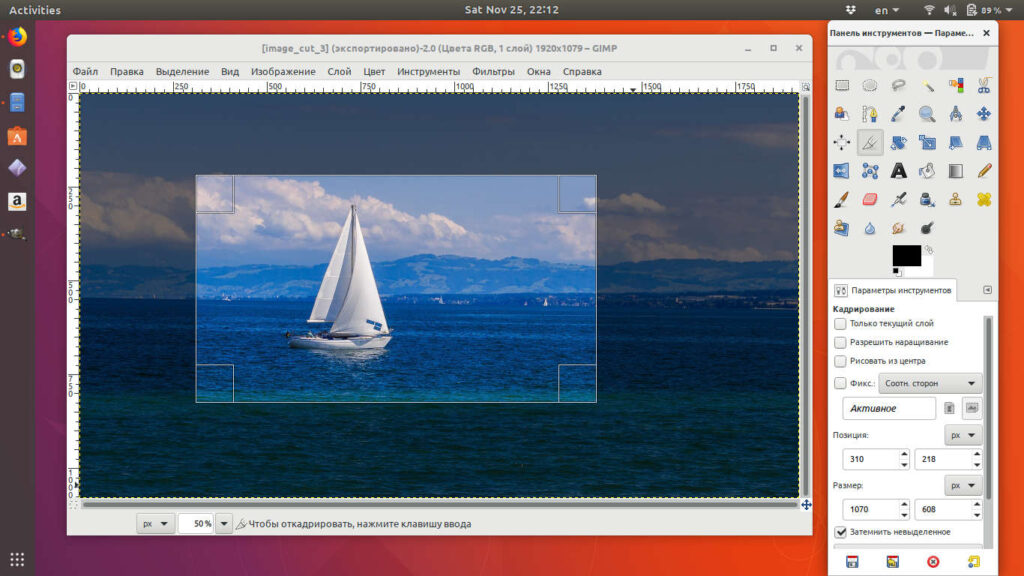
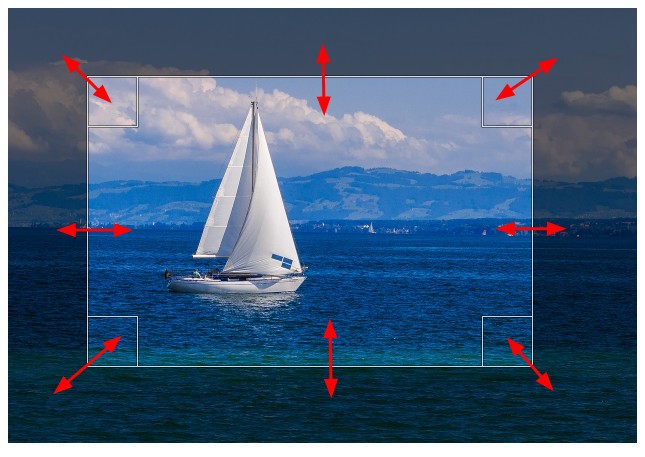
После того, как необходимый участок выделен, gimp позволяет скорректировать границы участка по которому будет проводиться обрезка изображения. Для этого, предварительно зажав правую кнопку мыши потяните за контур выделения вдоль любой из стрелок:
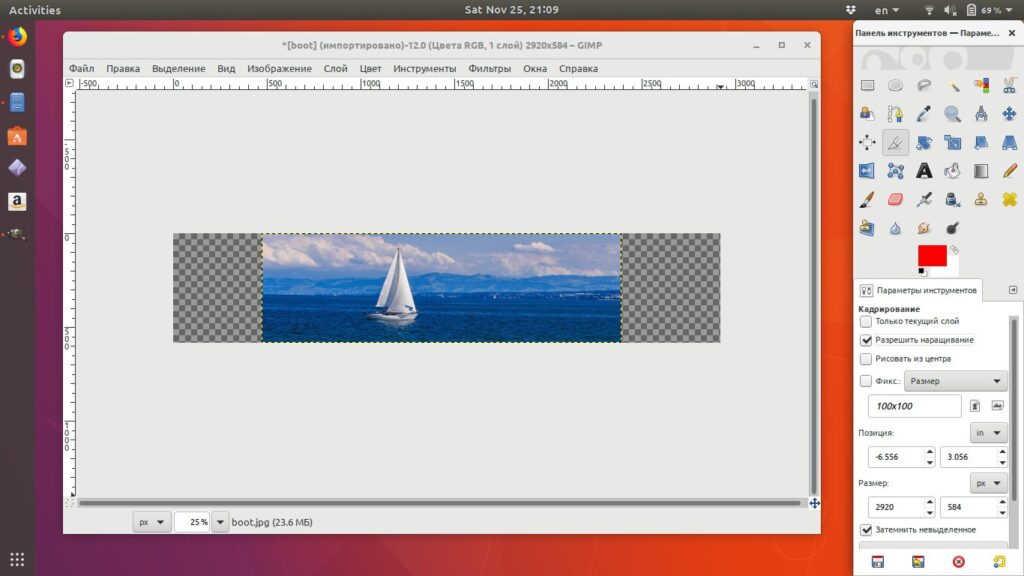
После того, как границы обрезки подогнаны с ювелирной точностью можно осуществить само кадрирование. Для этого в gimp есть два способа:
Нажимаем клавишу Enter и все ненужное будет отброшено, а выделенная область останется.
Просто кликаем мышкой в центр выделенной области.
Итак, в быстром старте мы рассмотрели, как обрезать в gimp фотографию. Как видно, ничего сложного в этом нет.
Продвинутая обрезка изображения
Как и любой другой инструмент в GIMP, “Кадрирование” имеет большое количество параметров, позволяющих сделать работу эффективной и в тоже время удобной.
Параметры “Кадрирования” на панели инструментов собраны в одну группу, которая выглядит следующим образом:
Пройдемся по всем параметрам и рассмотрим их назначение.
Только текущий слой - обрезка изображения будет применена только к тому слою, который в данный момент активен, другие слои останутся нетронутыми.
Разрешить наращивание - если выделение области для обрезки изображения выйдет за пределы самого изображения, то GIMP автомотически дополнит этот участок (дополнит прозрачной заливкой). Следует сказать, что очень удобная возможность для HTML-верстальщиков.
Рисовать из центра - при этом способе контур области выделения будет рисоваться от места, где кликнут мышью (удобно для обрезки изображения по какому то объекту).
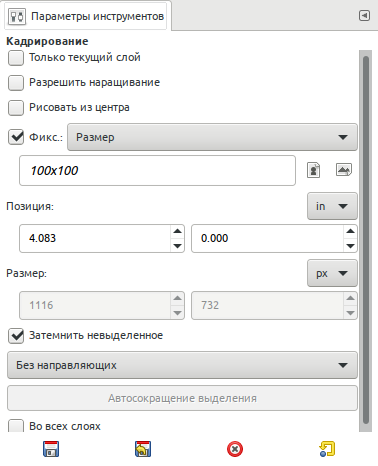
Далее идет очень важный параметер, отвечающий за форму области выделения. Следует сказать, что они активны только при установленном флажке в поле "Фикс.". То есть, мы заранее фиксируем форму будущей области выделения. Четкое задание размеров области выделения. Нужно только кликнуть мышкой на изображении и сразу же выделится участок заданным размером (в данном случае 640x480).
В этом случае соотношение сторон области выделения будет равно 1:1 (можно было использовать 5:5, 100:100, 99:99 было бы тоже самое).
Ширина фиксирована, высота может быть любой.
Высота фиксирована, ширина может быть любой.
Затемнить не выделенное
Следующие изображения наглядно демонстрируют работу этой опции:
Далее идет параметр, отвечающий за художественную составляющую при выборе объектов в результирующем кадре. Ведь нужно не только знать как обрезать картинку в gimp, но и сделать это максимально правильно. Чтобы в процессе обрезки удобнее было размещать объекты на плоскости изображения, gimp накладывает на область выделения вспомогательные линии (сетку) по которым пользователь ориентируется в процессе кадрирования.
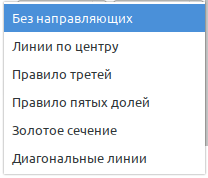
Gimp предлагает 6 вариантов сетки:
Без направляющих
Линии по центру
Правило третей
Правило пятых долей
Золотое сечение
Диагональные линии
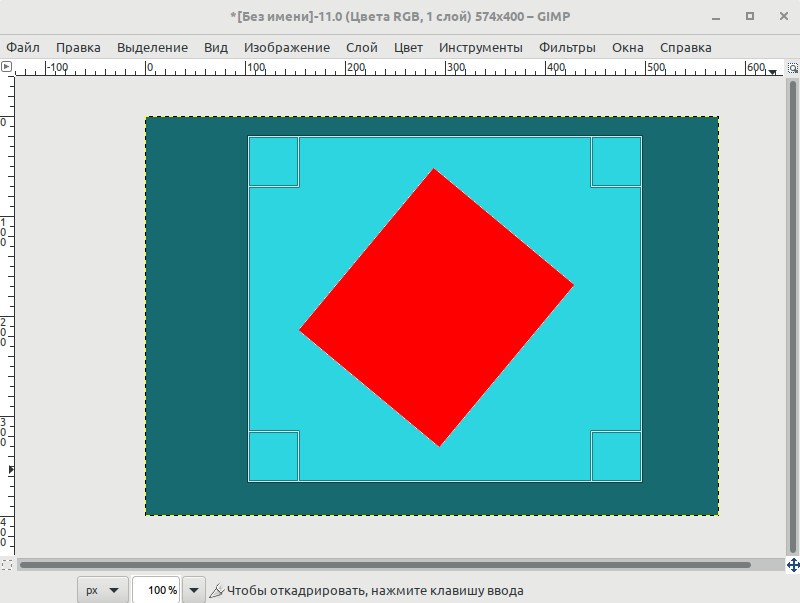
Автосокращение выделения - данный параметр, позволяет в один клик ужать область выделения до ближайшего объекта расположенного внутри этой области. Главное, чтобы объект контрастировал с фоном. А фон был однородным. Действие этой опции продемонстрируем на следующем примере, где чтобы обрезать изображение gimp применит метод "Автосокращение".
Исходное изображение. Попробуем обрезать его так, чтобы в кадре остался один прямоугольник.
С помощью инструмента "Кадрирование" выделяем область вокруг фигуры с "запасом".
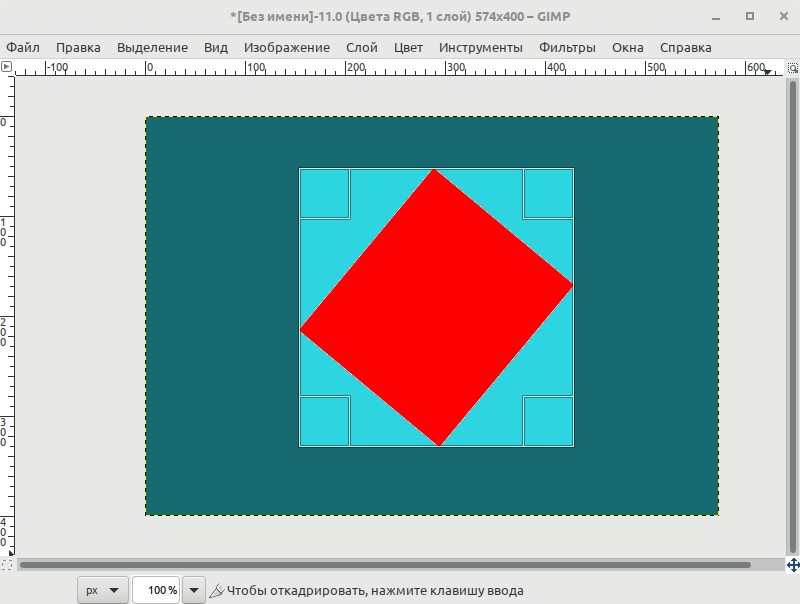
Затем жмем кнопку "Автосокращение выделения" и область выделения автоматически сжимается вокруг нашего прямоугольника.
Выводы
В этой статье мы подробно рассмотрели как обрезать фото в gimp. В деталях рассмотрена работа инструмента "Кадрирование", с помощью которого делается обрезка. Рассмотрены различные режимы выделения области по которой будет осуществляться финальное кадрирование. Чтобы обрезать изображение gimp использует тот же подход, что и другие фоторедакторы и это огромный плюс для тех, кто решил попробовать перенести свой рабочий процесс по обработке изображений в связку Linux+Gimp, ведь не надо все учить заново, дасточно воспользоваться имеющимися навыками.
По разным причинам вам может понадобиться перенести свой сайт на другой хостинг или VPS сервер. Это может быть вызвано тем, что ваш проект развивается и для него уже недостаточно ресурсов сервера, а может просто вас не устраивает уровень обслуживания. За все время развития kovalets я менял хостинг провайдера много раз, то, что описано в истории сайта далеко не все. Возможно, позже у меня дойдут руки дописать, но не сейчас.
В этой статье я расскажу как выполняется перенос сайта WordPress, как это лучше сделать, что вам необходимо знать для того чтобы переезд прошел гладко и незаметно для пользователей.
В операционных системах семейства Linux основным пакетом для создания и редактирования различных документов является LibreOffice. В отличие от Microsoft Office данный продукт является полностью бесплатным, но ничем не ограничивается в возможностях. Давайте разберемся, как пользоваться LibreOffice, и насколько в целом удобен данный программный пакет?
Установка LibreOffice
LibreOffice – это совершенно бесплатный пакет офисных программ, в который выходит множество продуктов, предназначенных для создания текстовых документов, таблиц, презентация и многого другого. Программа работает с собственным типом файлов, но полностью совместима с файлами от Microsoft Office.
LibreOffice Writer является прямым аналогом Microsoft Word, что значительно облегчает переход пользователей с одной системы на другую, особенно если вы привыкли к версии от 2003 года, которая до сих пор используется в некоторых учебных учреждениях и на предприятиях.
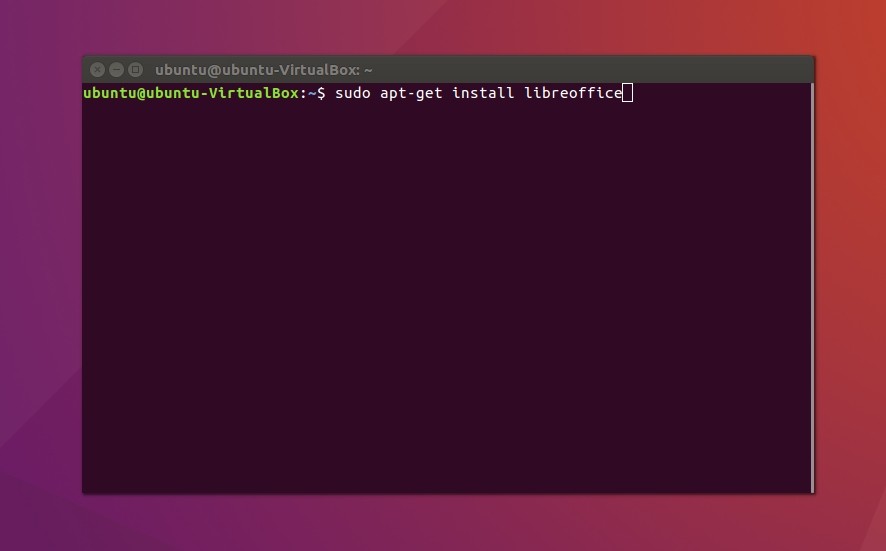
LibreOffice Writer входит в стандартный набор программ большинства дистрибутивов Linux и поставляется вместе с Ubuntu, xUbuntu и многими другими. Все необходимые пакеты находятся в стандартных репозиториях, и если у вас все же офиса на компьютере нет, тогда необходимо открыть терминал и ввести:
sudo apt-get install libreoffice
Подтвердите установку программы и дождитесь скачивания всех необходимых пакетов.
Процесс установки LibreOffice в Windows ничем не отличается от других программ — запустите установщик, отметьте пакеты, которыми вы будете пользоваться, нажмите несколько раз кнопку «Далее» и можете приступать к использованию комплекта ПО.
Как выглядит программа?
Внешне LibreOffice сильно напоминает Microsoft Word До 2007 года выпуска:
по центру экрана находится главная рабочая область,
справа - панель быстрого доступа к наиболее часто используемым функциям,
над основным рабочим полем — линейки, панель операций и меню.
У пользователей Linux с оболочками Unity и Gnome, панель меню встраивается в интерфейс и появляется при появлении курсора.
Само меню управления довольно стандартное, здесь вы найдете привычные пункты: файл, правка, сервис, вид, стили, формат и многое другое, чем вы будете пользоваться в процессе создания документов.
Основы форматирования и выделения
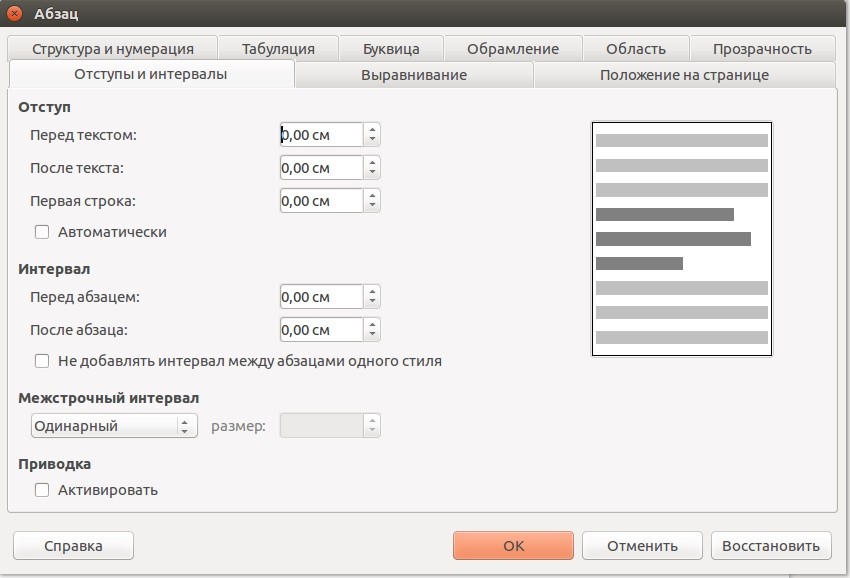
LibreOffice изначально использует собственные стили форматирования, которые восстанавливаются при создании нового документа. Для изменения настроек необходимо воспользоваться пунктом меню «Формат» и произвести конфигурацию, например, на вкладке «Абзац». Перед вами появится окно с текущими настройками документа, которые легко изменить.
Здесь вы можете задать высоту строк, добавить обрамление, выбрать прозрачность и настроить многие другие параметры. Если вы хотите произвести смену тех же интервалов уже в готовом документе, тогда выделите нужный отрезок документа при помощи стандартных комбинаций клавиш, и только тогда производите все необходимые операции.
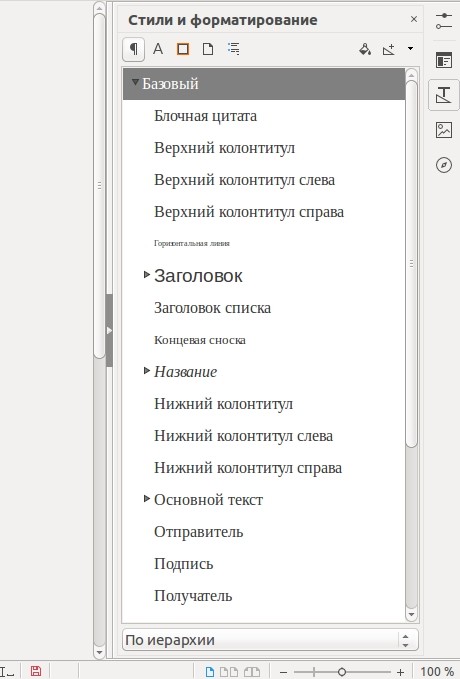
В правой части главного окна есть окно с предустановленными и пользовательскими стилями форматирования.
Пользователь может редактировать уже готовые стили, а также создавать свои собственные.
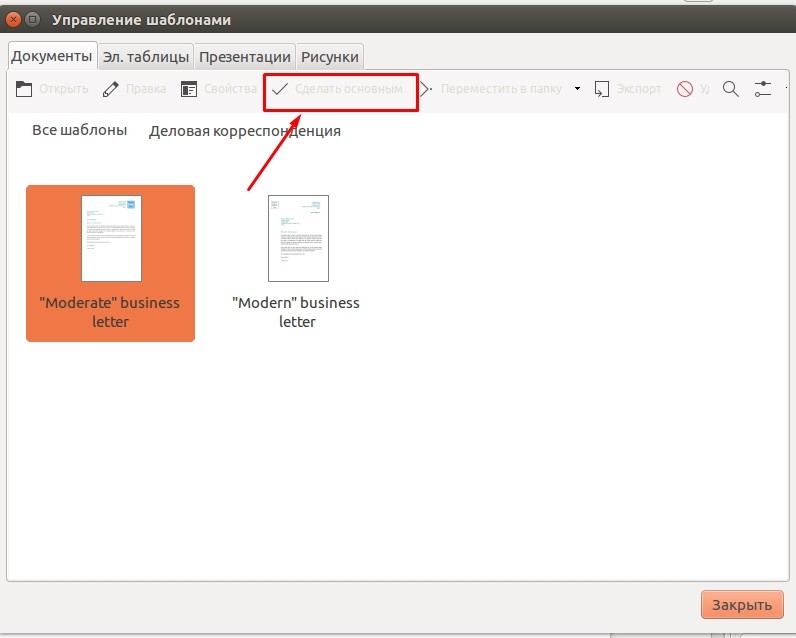
Если вам не хочется менять настройки документа после каждого запуска, тогда можно заранее задать все настройки и указать программе, что вы хотите использовать их по умолчанию. Для этого перейдите в меню «Файл», выберите пункт «Шаблоны» и нажмите «Сохранить как шаблон».
Далее, перед вами появится окно управления шаблоном, где вам нужно выбрать сохраненные предустановки и нажать кнопку «Сделать основным». Теперь, после каждого запуска LibreOffice Writer, программа будет запускать конкретно ваши предустановки.
Как работать с титульными листами?
С титульными листами чаще всего приходится сталкиваться студентам, ученикам и абитуриентам при создании дипломных, курсовых, самостоятельных работ и рефератов. При их создании чаще всего используются следующие функции:
выравнивание текста — по центру, слева или справа;
разрывы строк — при оформлении наименований документов и мест для простановки даты/подписи.
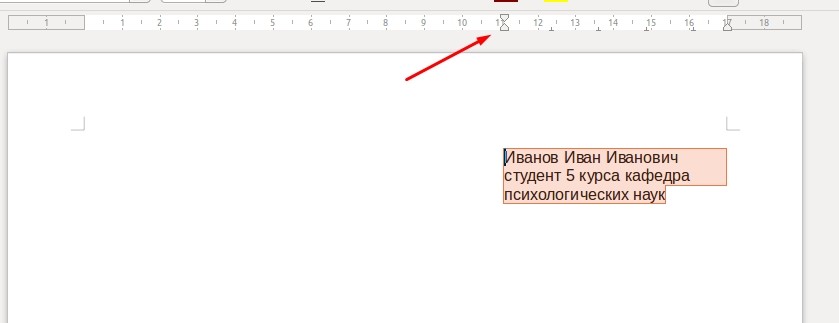
Независимо от учебного учреждения или организации, существуют общие правила. Сверху титульного листа указывается название учреждения, по центру — название и тип работ, по центру справа — имя студента/ученика/сотрудника, работавшего над проектам, а в левой нижней (или правой нижней части) — личные данные проверяющего.
Существует множество приемов для оформления листа, но основная задача — сделать все это так, чтобы в дальнейшем можно было легко отформатировать каждый пункт, не нарушая общую структуру документа.
Начинается работа всегда с оформления названия учреждения — нажмите Caps Lock, введите требуемое имя и начните новый абзац.
Если вы ввели все изначально строчными буквами — ничего страшного, выделите при помощи мыши или клавиатуры необходимый текст, после чего несколько раз нажмите SHIFT + F3, пока буквы не превратятся в прописные.
Чтобы переместить блок с вашими данными в правую часть, выделите необходимый текст и передвиньте ползунок верхней линейки вправо.
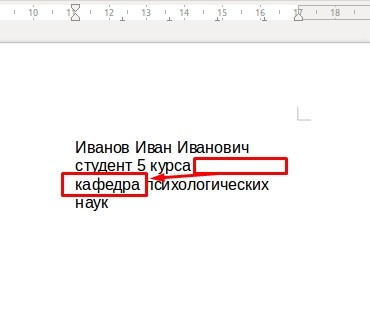
Если вы видите, что одно из слов находится не на нужной строке, сделайте перенос при помощи кнопок Shift + Enter. Данная комбинация оставит нужную часть текста в пределах абзаца, а значит, сохранится структурная целостность документа.
При редактировании таких блоков (добавлении или удалении слов), слова не будут произвольно прыгать, а также сохранятся стили отдельного абзаца.
Работа с заголовками и оглавлением
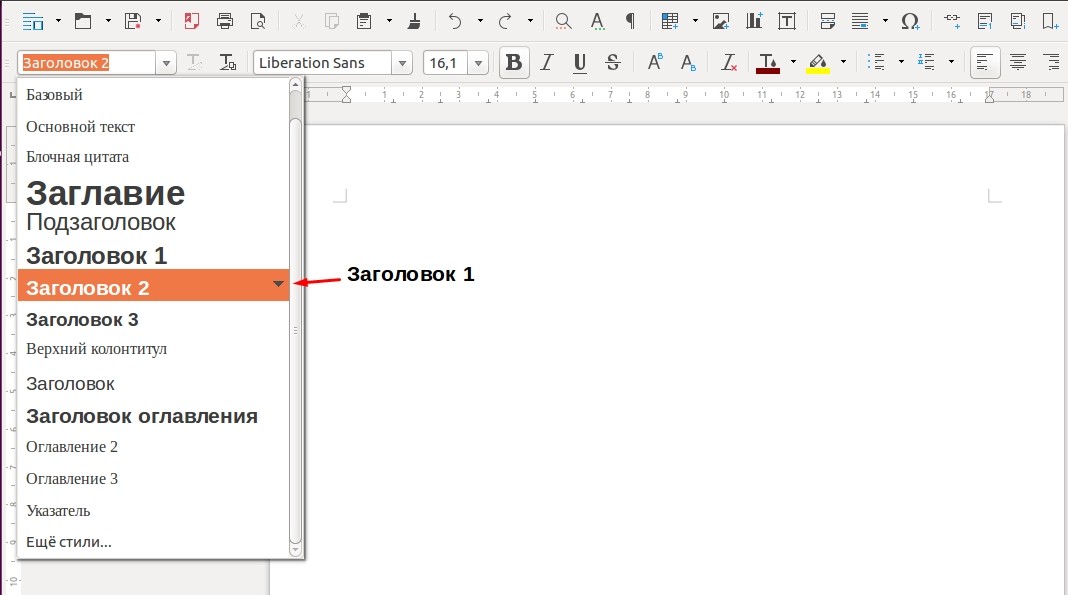
Для оформления заголовков в офисных документах недостаточно просто выделить нужную часть текста жирным и сделать шрифт побольше. Здесь необходимо использовать специальные стили, которые в дальнейшем позволят создавать оглавление в автоматическом режиме.
Представим себе документ, который состоит из трех заголовков, а один из них содержит в себе два подзаголовка. Заголовки отмечает специальным стилем, который так и называется «Заголовок 2», а подзаголовки «Заголовок 3». Сделать это можно также при помощи комбинаций клавиш Ctrl + 2 и Ctrl + 3 соответственно.
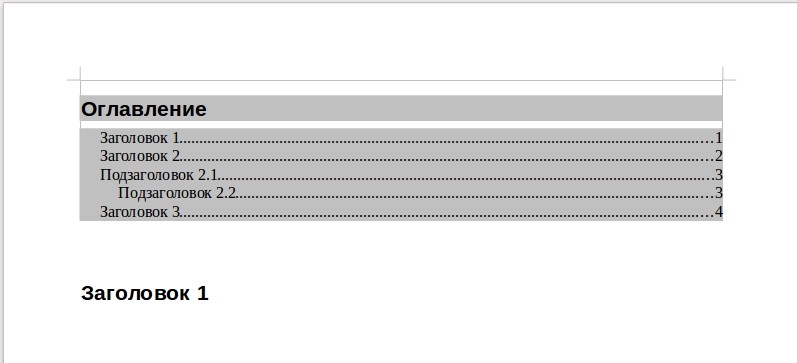
Далее, перейдем в пункт меню «Вставка», выбираем здесь «Оглавление и указатели», а в открывшемся меню выбираем «Оглавление, указатель или библиография...». В этом окне вы можете дать название оглавлению, а также отредактировать необходимые настройки (уровень заголовков и многое другое).
По окончании установки параметров нажмите кнопку «Ок».
Конечно же, можно вручную прописывать каждый пункт, делать списки и проставлять ссылки, но редактирование всех элементов в случае смещения страницы или изменение названия займет в разы больше времени. Дальше поговорим о том, как работать в libreoffice и изображениями и диаграммами.
Как вставить изображения и диаграммы?
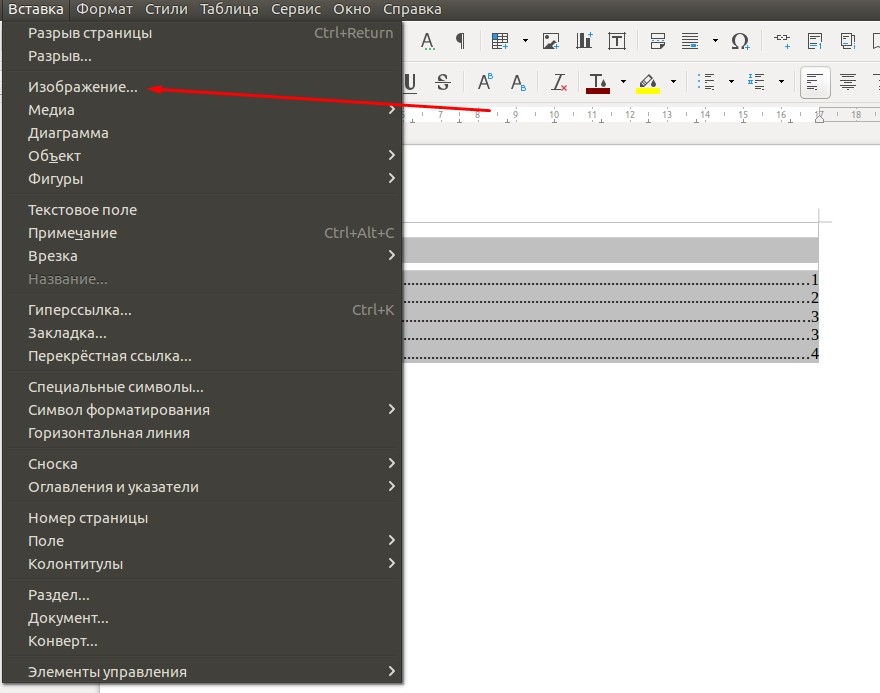
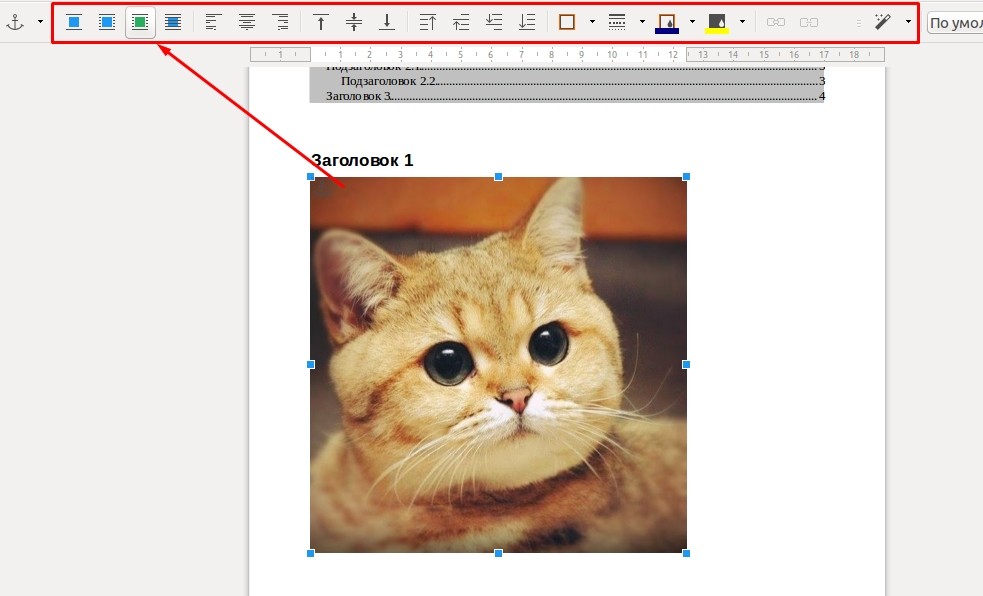
LibreOffice Writer поддерживает вставку диаграмм и изображений. Последние можно просто перетащить из файлового менеджера или вставить посредством меню «Вставка», используя пункт «Изображение».
После того, как вы вставите картинку, в панели инструментов появится дополнительное меню, посредством которого можно будет настроить отступы, обтекание, заливку фона и другие параметры медиафайла.
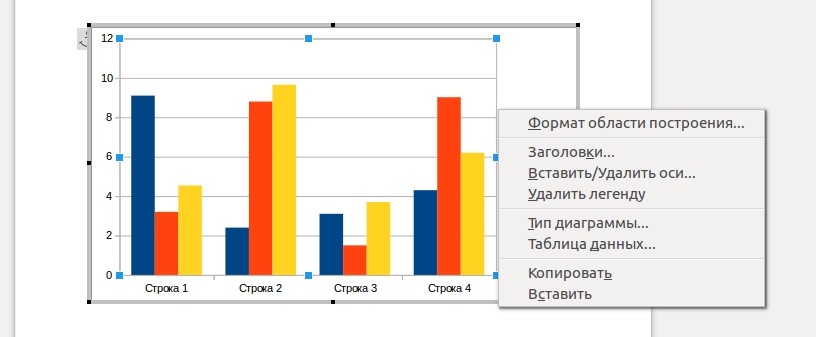
Чтобы добавить в документ диаграмму, также перейдите в меню «Вставка» и выберите пункт «Диаграмма». Перед вами сразу появится готовый элемент, но его необходимо будет отредактировать согласно той информации, которой вы хотите поделиться.
Для редактирования диаграммы нажмите на элемент правой кнопкой мыши и выберите один из нужных пунктов:
таблицы данных — позволяет изменить имя колонок или сегментов диаграммы;
тип диаграммы — выбирайте внешний вид (график, столбцы, круговая и т. д.);
вставить/удалить оси — добавляйте новые колонки или сегменты;
заголовки — позволяет задать имя диаграммы.
Также очень важны пункты «Формат области построения» и «Размер», которые позволят изменить положение графика в документы, а также определить ее внутренние рабочие области.
Вставка таблиц в документ
Диаграммы достаточно часто являются визуализацией информации, представленной в таблицах. Такой подход позволяет упросить понимание читателя относительно того или иного аспекта деятельности, особенно если необходимо понять динамику различных процессов.
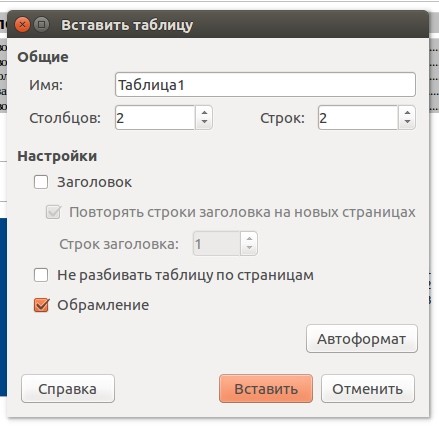
Для создания таблицы используйте пункт меню «Таблица - Вставить таблицу» или нажмите комбинацию Ctrl + F12. Перед вами появится окно начальной настройки, где вы сможете задать количество колонок и столбцов, а также задать другие параметры.
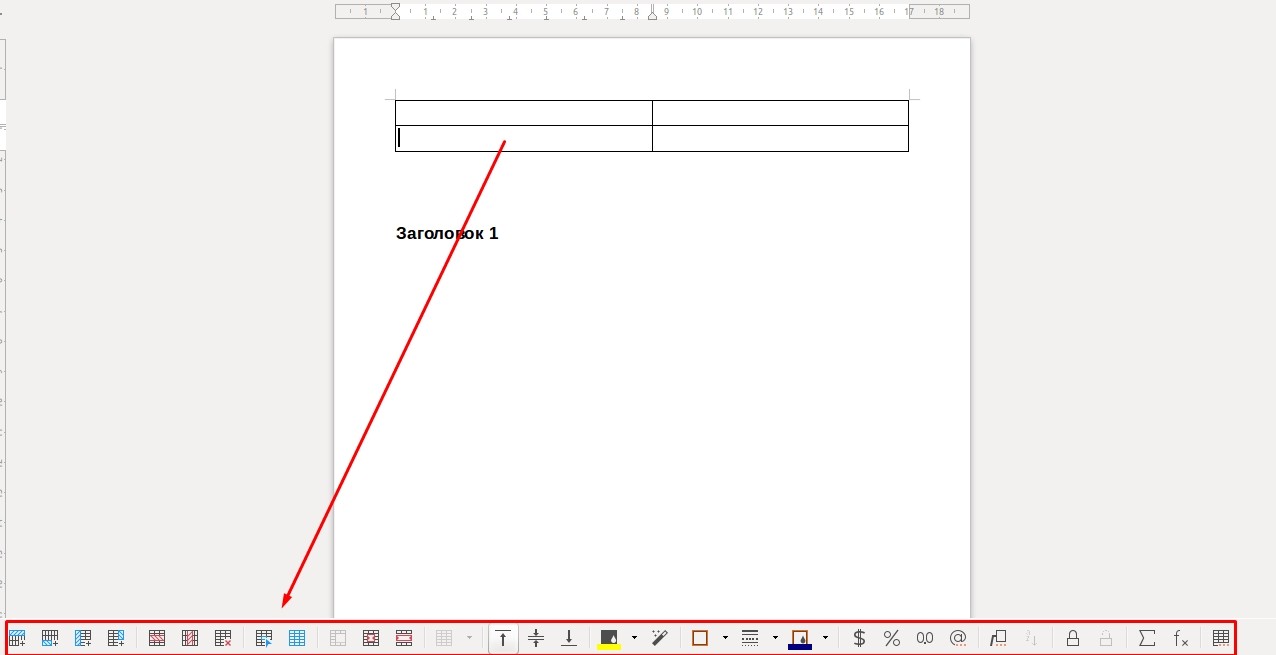
Редактирование элементов таблицы может производиться как через меню, так и посредством дополнительной панели инструментов, которая располагается в нижней части рабочей области. Также многие основные операции можно производить посредством контекстного меню.
Библиография и списки литературы
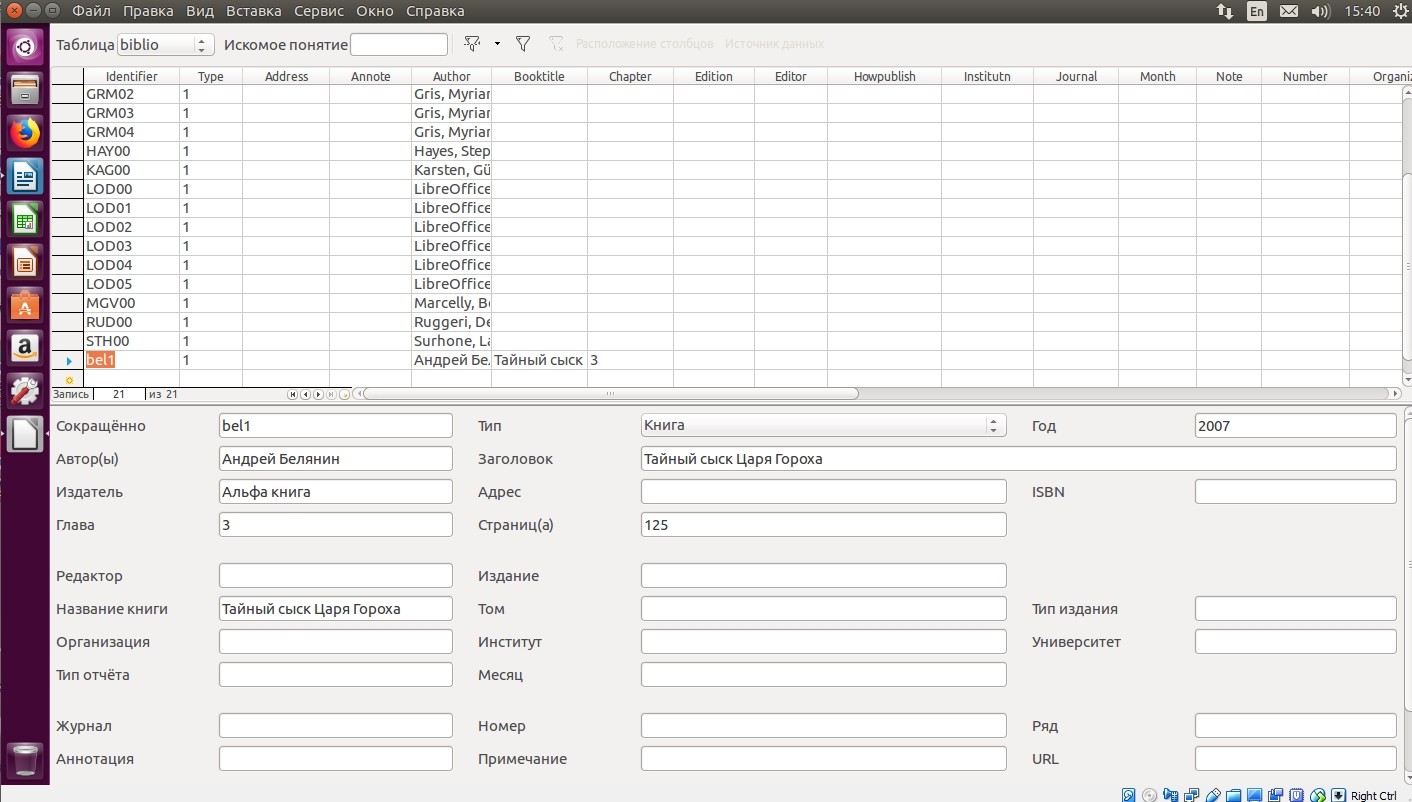
Дальше рассмотрим как настроить LibreOffice для работы со списками литературы. В LibreOffice существует возможность автоматического создания списка использованной литературы. Для этого пользователям понадобится добавить соответствующие записи в базу данных библиографии:
откройте меню «Сервис - Базы данных библиографии»;
выделите пустую строку в таблице и перейдите в нижнюю часть окна, где можно будет ввести полную информацию об источнике;
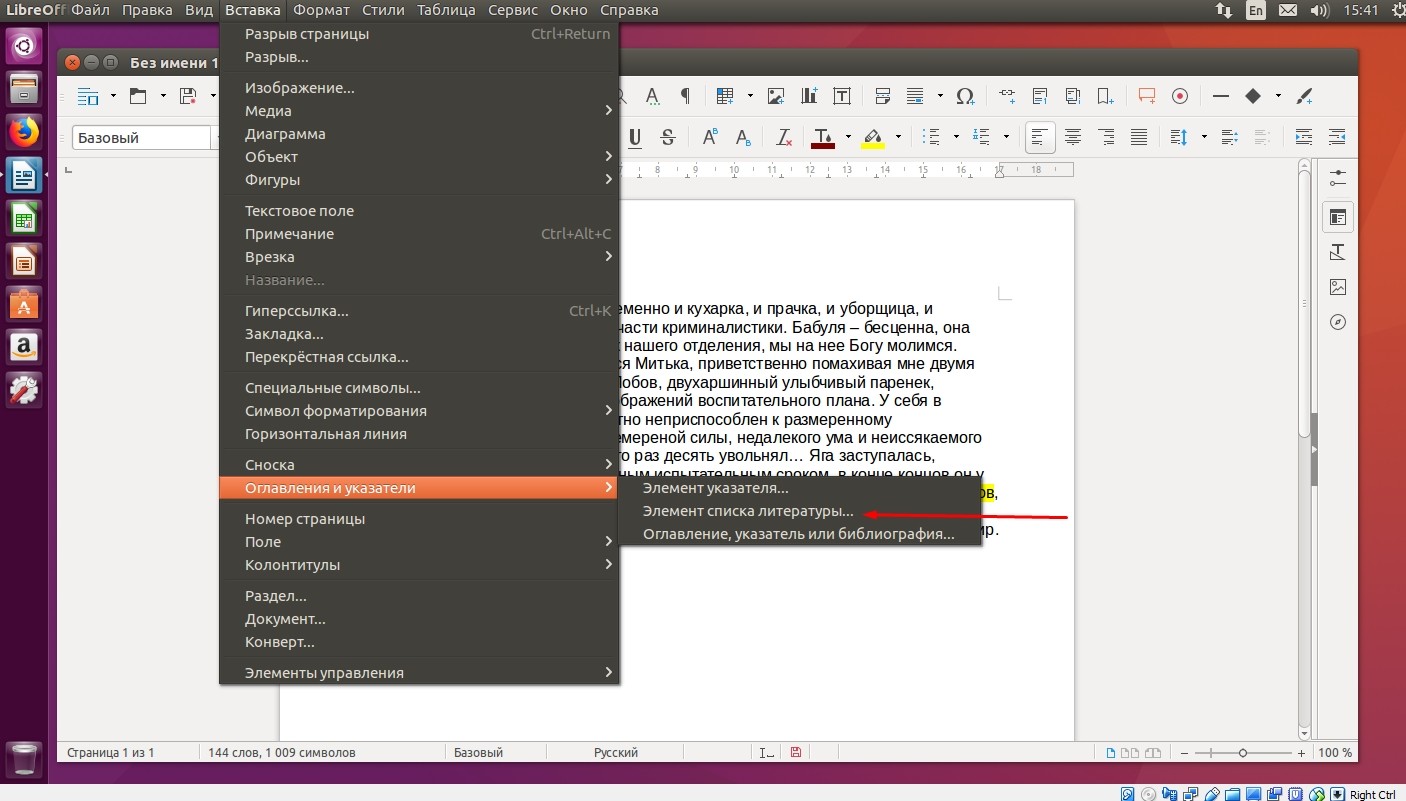
далее, перейдите к части документа, которая ссылается на ту или иную информацию из источника, установите курсор в конец цитаты;
нажмите «Вставка - Оглавление и указатели - Элемент списка литературы», а в выпадающем списке выберите сокращенное название, которое вы ввели ранее.
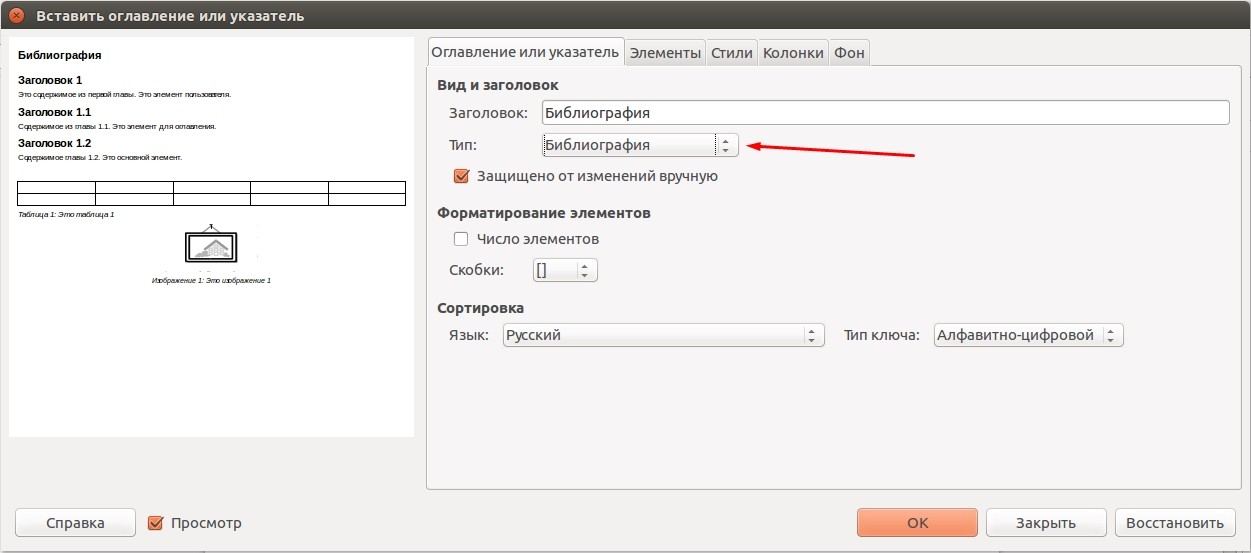
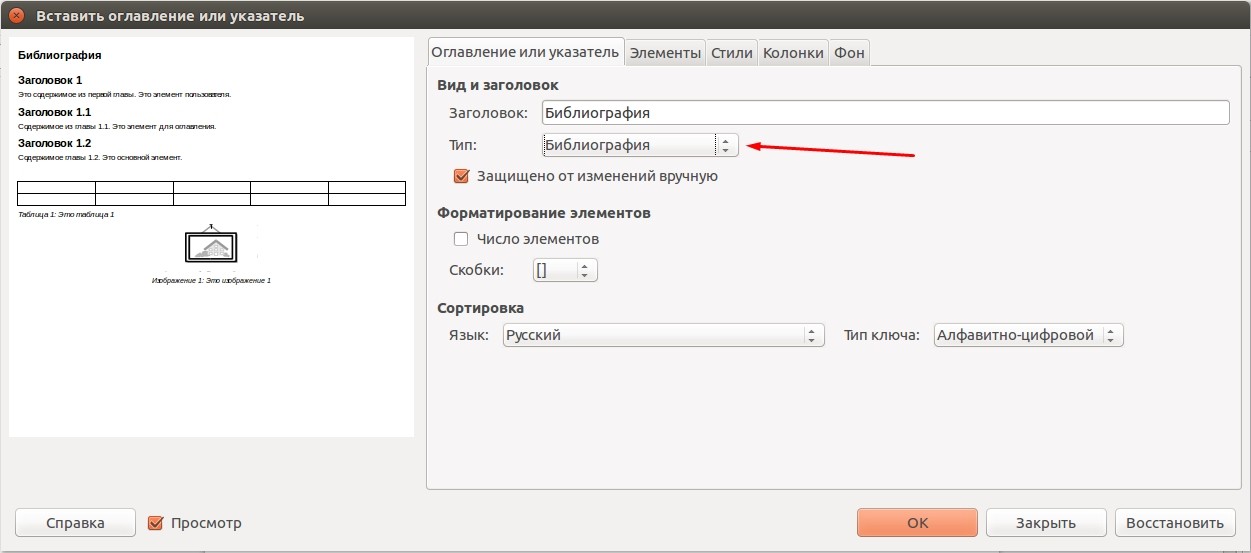
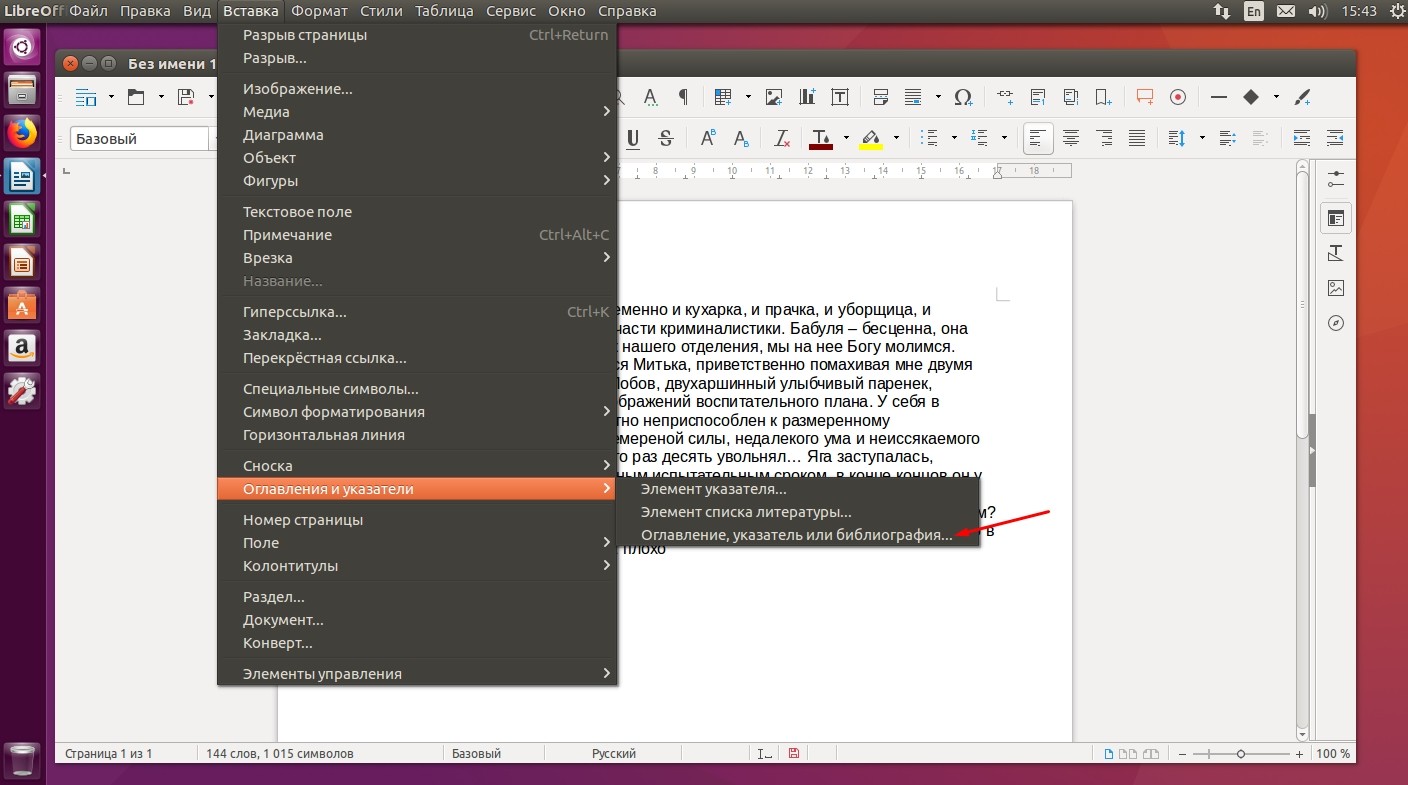
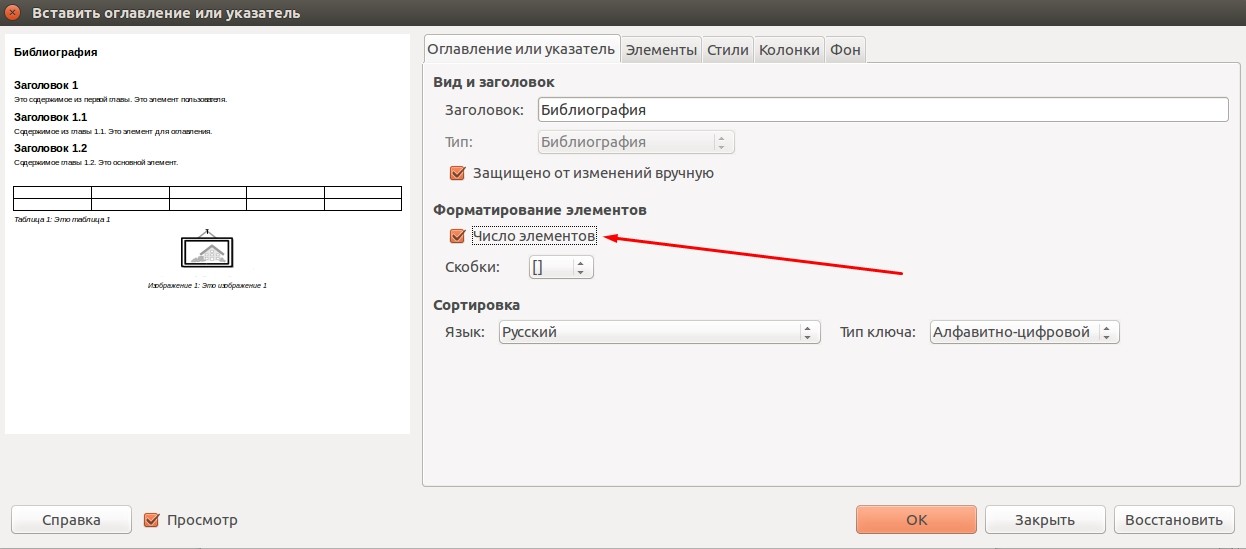
Данную процедуру нужно проводить во всех случаях, когда вы ссылаетесь на сторонние литературные источники. По окончании простановки ссылок, можно сгенерировать список литературы. Для этого перейдите в меню «Вставка - Оглавления и указатели - Оглавление, указатели и библиография», а в выпадающем списке «Тип», выберите пункт «Билиография», после чего нажмите Ок.
При этом ссылки на литературу будут все также выглядеть в виде сокращений, указанных в базе данных. Чтобы перевести все это в привычную нумерацию, необходимо нажать правой кнопкой мыши на поле с источниками, выбрать пункт «Править оглавление или указатель», а в поле «Форматирование элементов» отметить флажком пункт «Число элементов». После этого наша библиография приведет привычный вид. Кстати, в этом же окне на разных вкладках вы можете задать все тонкости форматирования, согласно требованиям того или иного заведения.
Выводы
В этой статье мы рассмотрели как пользоваться Libreoffice, полноценным офисным пакетом, который может использоваться для создания самых различных документов. По своим возможностям он ничем не уступает платным аналогам, а в некоторых ситуациях даже превосходит их. А вы используете LibreOffice? Напишите в комментариях!
Ни для кого не секрет, что большинство платформ для создания веб-сайтов, и в том числе такая популярная платформа, как WordPress, используют базу данных для хранения информации. Работа с базой данных намного быстрее, чем с файлами поэтому такой подход и набрал большую популярность. Но иногда при мы можем сталкиваться с такой проблемой, как ошибка установки соединения с базой данных WordPress.
Эта ошибка будет выводиться на каждой странице вашего сайта и вы потеряете посетителей, а также доход, который могли получить. В этой статье мы рассмотрим почему возникает ошибка error establishing a database connection WordPress, а также способы борьбы с ней на хостинге и на VPS.
Mozilla Thunderbird – это бесплатный мультиплатформенный почтовый клиент, который позволит пользователям обмениваться с друзьями, близкими и коллегами по работе, электронными сообщениями. Благодаря широким функциональным возможностям данную программу можно использовать как в домашних условиях, так и на работе, а благодаря специальным расширениям и дополнениям, ее можно легко кастомизировать под собственные требования. Давайте разберемся, как пользоваться Thunderbird, и какие функциональные возможности предлагает нам клиент после сразу после установки.
Установка Thunderbird
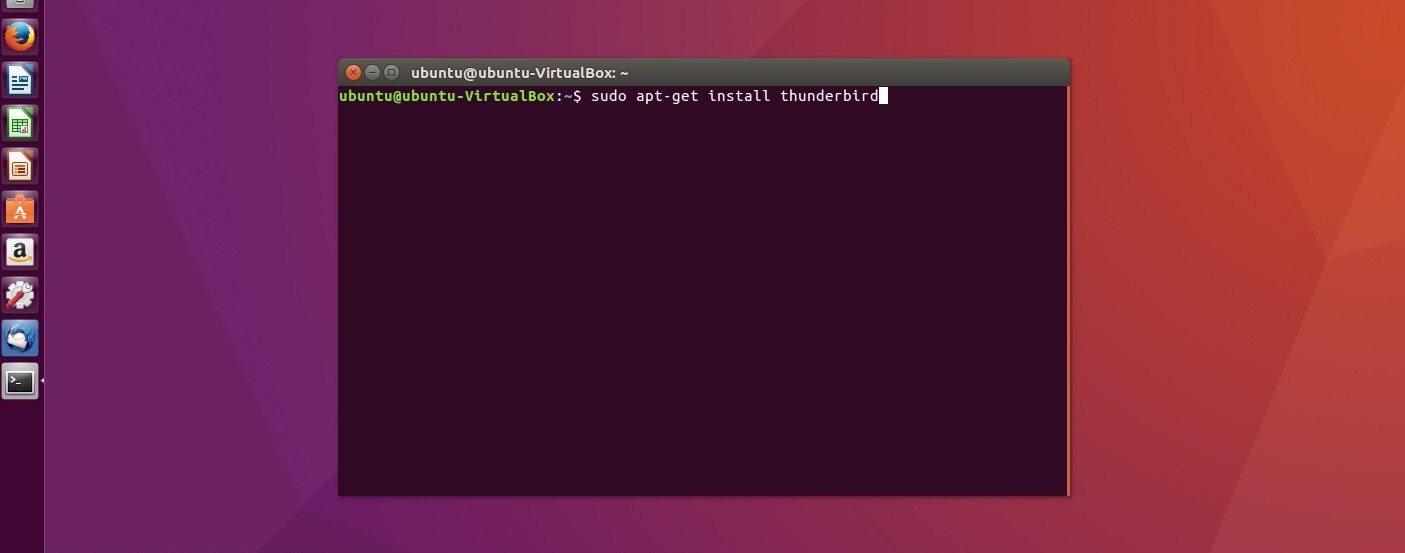
Thunderbird является частью стандартного набора программ в большинстве современных дистрибутивов Linux, поэтому чаще всего не нуждается в установке. Если же по умолчанию данной программы у вас нет, тогда необходимо открыть терминал и ввести в строке:
sudo apt-get install thunderbird
После этого подтвердите установку программы и дождитесь завершения всех процедур. Стабильные версии всегда доступны в базовых репозиториях Linux, поэтому подключение дополнительных ресурсов не требуется. Также установку Thunderbird можно провести произвести посредством центра приложений (Ubuntu, Mint и другие, ориентированные на рядового пользователя дистрибутивы).
Так как Thunderbird доступна на всех современных операционных системах, почтовый клиент можно установить на Windows и даже Mac OS. Для этого достаточно перейти по ссылке https://www.mozilla.org/ru/thunderbird и скачать подходящий установщик. Официальный сайт автоматически определит вашу ОС и подберет наиболее оптимальную версию. Процесс последующей настройки выглядит точно так же, как и в Linux.
Интерфейс программы
Внешне Thunderbird выглядит, как и большинство аналогичных программ. По умолчанию в левой части окна находятся все ваши почтовые папки, а справа предпросмотр сообщений, ссылки на RSS-ленты, группы новостей и многое другое. Панель меню содержит в себе ссылки на наиболее популярные пользовательские действия, такие как получение почты, фильтр, адресная книга, чат и фильтр по меткам.
Все эти элементы можно редактировать и изменять, исходя из собственных предпочтений. Достаточно кликнуть правой кнопкой мыши и выбрать в контекстном меню пункт «Настроить».
Как настроить Thunderbird
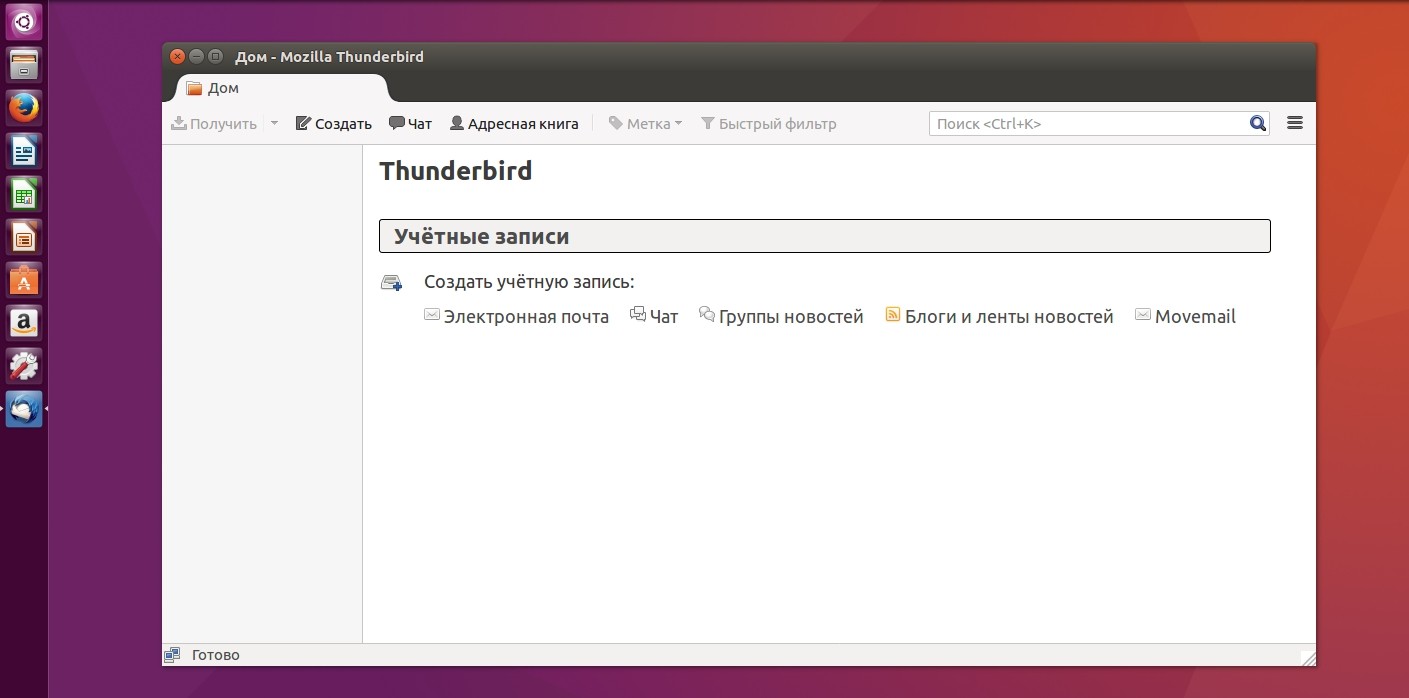
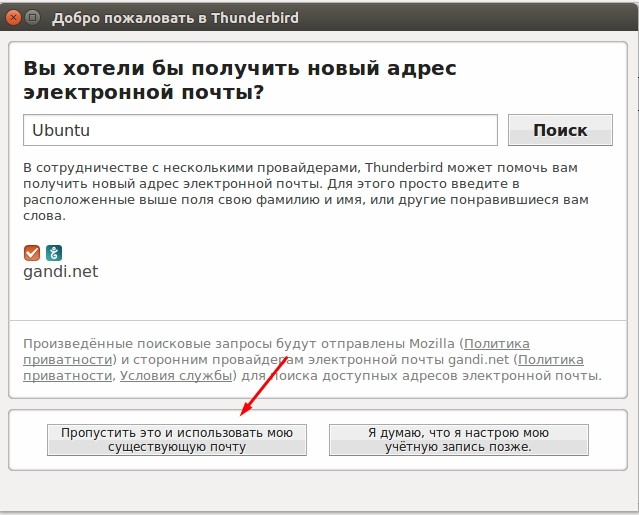
Настройка Thunderbird – это один из самых важных этапов. Программа содержит множество функций, в которых по началу может быть сложно разобраться, поэтому после первого запуска нас встречает специальный мастер. На данном этапе вы сможете как зарегистрировать новый почтовый ящик, так и использовать уже существующий.
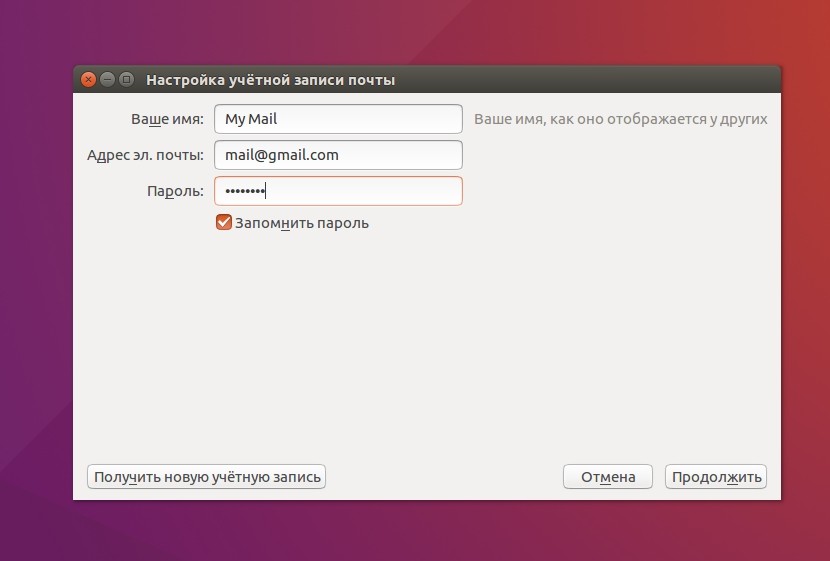
После нажатия на соответствующую кнопку начнется настройка почты в Thunderbird. Здесь вам достаточно ввести свой e-mail, имя, которое будет отображаться в левой части окна и пароль.
После ввода данных Thunderbird проверит ваши учетные данные, а по возможности подтянет необходимые настройки для соединения с почтовым сервисом. Здесь же пользователь сможет выбрать, какой протокол ему использовать — IMAP или POP3. Первый предоставляет удаленный доступ к письмам на сервере, второй — будет скачивать все письма на ПК.
При использовании корпоративной почты или малоизвестного поставщика услуг, необходимо ввести будет параметры отправки/приема сообщений самостоятельно, используя кнопку «Ручная настройка». Как только данные будут введены, программа автоматически проверит конфигурацию и вы сможете сразу начать работу.
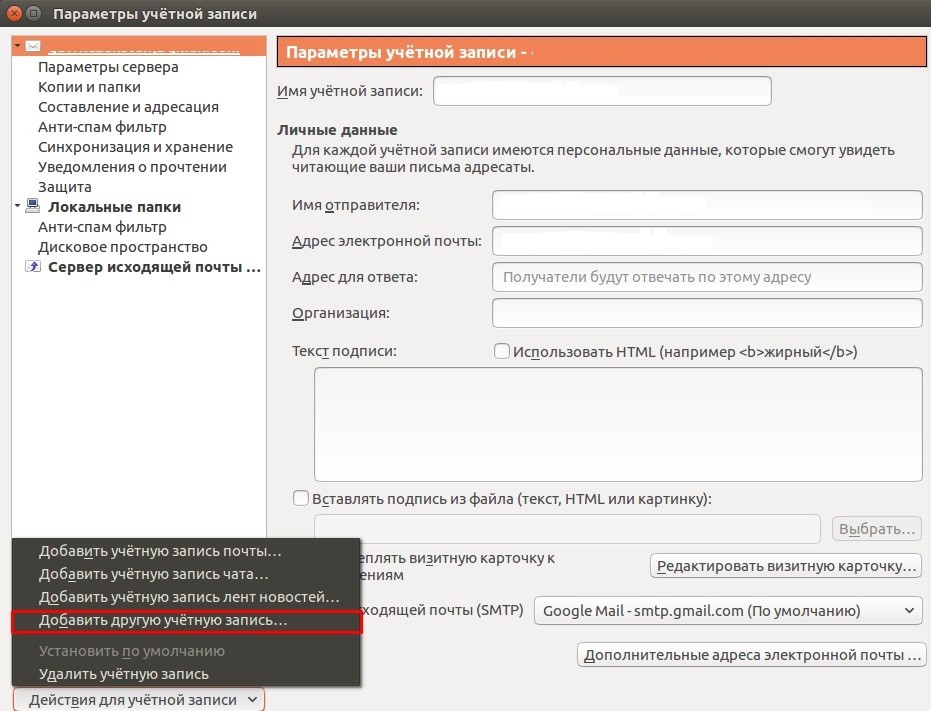
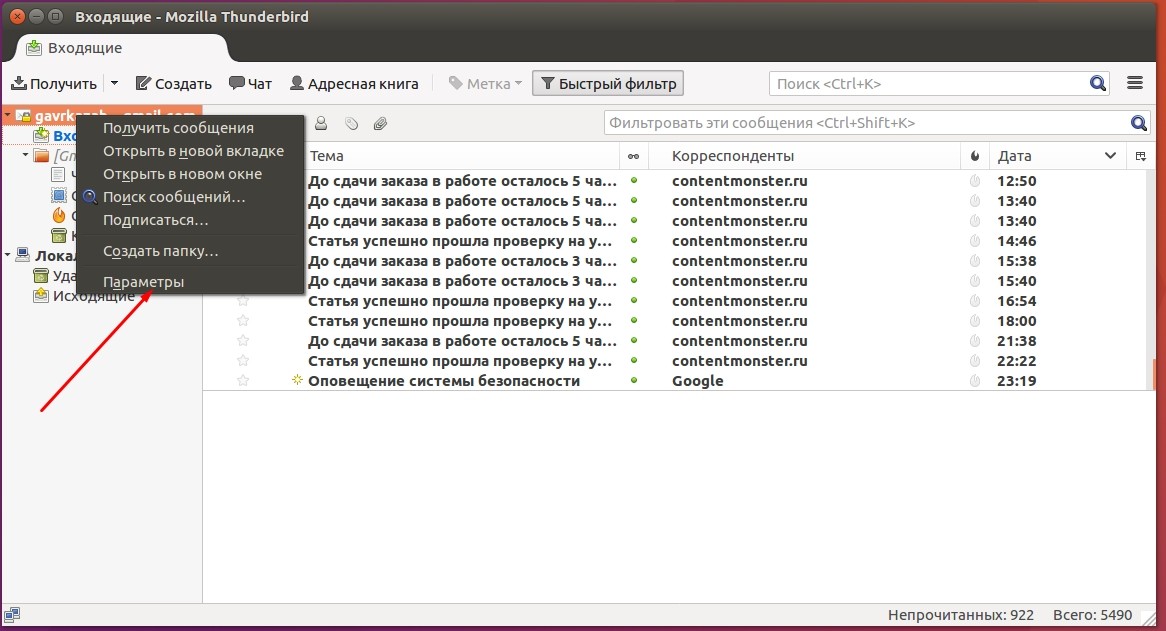
Если вы используете несколько аккаунтов, тогда нажмите в правой верхней части окна кнопку меню, перейдите к пункту «Настройки — Параметры учетной записи» и в левой нижней части окна выберите пункт «Добавить учетную запись»
После этого проведите настройку по той же схеме, что и ранее.
Синхронизация писем
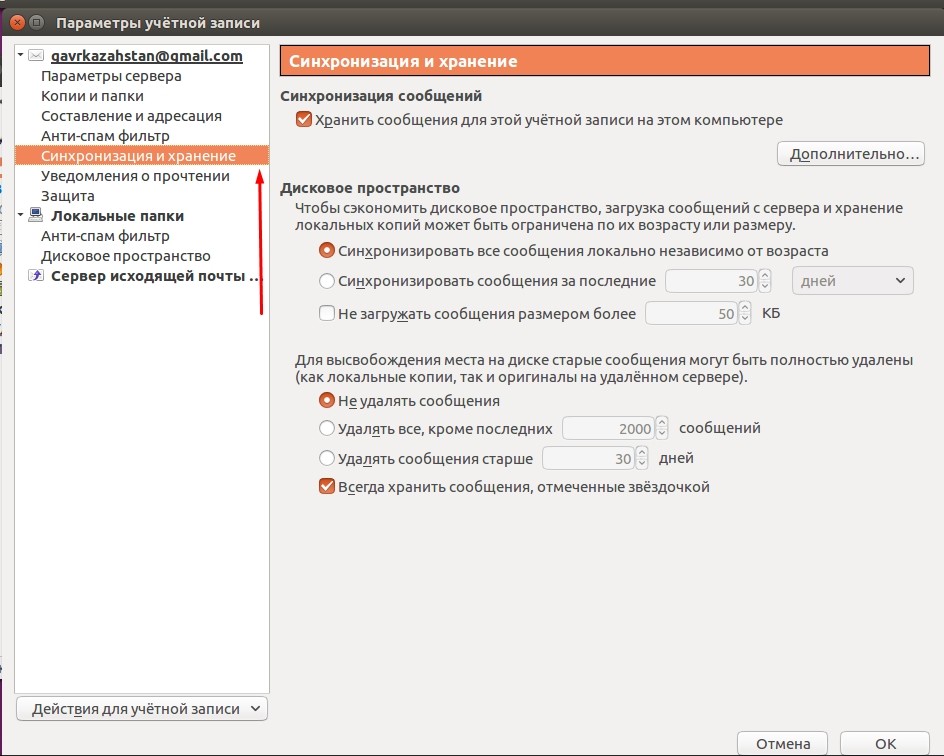
Изначально Thunderbird скачивает все письма и папки, которые находятся на вашем почтовом сервере, но в дальнейшем пользователь может самостоятельно выбрать, какие папки нужно синхронизировать. Для этого кликните на имя учетной записи в левой части окна и откройте ее параметры.
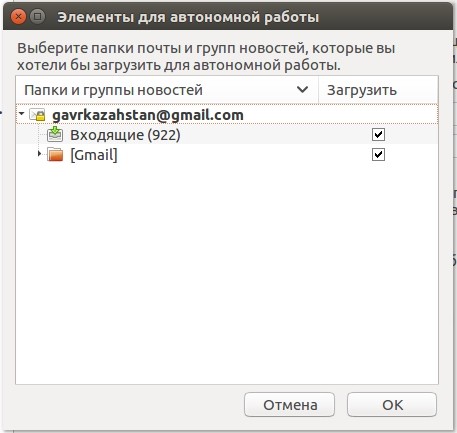
Перейдите к категории «Синхронизация и хранение», после чего выберите наиболее подходящие настройки для вас. В меню «Дополнительно» вы можете отметить конкретные папки для учетной записи, сообщения из которых будут попадать к вам на компьютер.
По окончании нажмите кнопку «Ок», а для правильности отображения всех подпапок — перезапустите клиент. Настройка почты Thunderbird на данном этапе может считаться завершенной.
Поиск сообщений в папках
Поиск в Thunderbird может осуществляться как при помощи строки быстрого ввода, так и быстрого фильтра. Чтобы найти нужный контакт или сообщение достаточно начать вводить слово в соответствующее поле.
Далее, перед вами появится окно со всеми совпавшими результатами. В левой части окна находится специальный фильтр, который облегчит вам поиск нужного сообщения.
Система поиска в Mozilla Thunderbird понятна и доступна даже пользователям, которые ранее не работали с программой.
Создание почтовых сообщений
Написать сообщение в Thunderbird можно несколькими способами:
нажать кнопку «Создать» в главном окне программы, после чего ввести все необходимые данные получателя;
кликнуть правой кнопкой на адрес нужного контакта и выбрать в контекстном меню пункт «Отправить».
Окно создания сообщения представляет собой простой редактор с базовыми возможностями. Пользователь может приложить к письму файлы, выбрать размер, цвет и тип шрифта, а также разбавить письмо смайлами.
Стоит обратить внимание на несколько полей ввода адресата — здесь можно выбрать сразу нескольких получателей, а также добавить скрытые копии, которые будут отправлены на отдельные почтовые ящики.
Работа с контактами
Использование Thunderbird упрощается обширной адресной книгой. Чтобы добавить новый контакт необходимо кликнуть на имя отправителя/получателя левой кнопкой мыши и выбрать соответствующий пункт.
Если вы ранее не отправляли или не получали сообщения тому или иному адресату, можно добавить его вручную через меню «Адресная книга — Создать». Карточка контакта содержит в себе всю необходимую информацию, а по необходимости ее можно дополнить даже фотографией.
Расширяем возможности Thunderbird дополнениями
Работа с Thunderbird облегчается возможностью доработки программы под собственные нужды. Для этого разработчики создали целый центр дополнений, где пользователи могут найти все самые полезные расширения, начиная от тем оформления, заканчивая практически отдельными программами.
Найти центр обновлений можно, кликнув на кнопку «Меню — Дополнения». Пред вами сразу появятся наиболее популярные плагины, а по необходимости вы можете открыть полную версию сайта, где все распределено по категориям.
Выводы
Mozilla Thunderird – это одновременно простой и функциональный почтовый клиент, с которым легко справится даже начинающий пользователь. Программа автоматически подтягивает настройки самых популярных почтовых сервисов и может справляться со своими задачами уже с самого старта. Если же стандартных возможностей вам покажется мало, всегда можно расширить функционал при помощи специальных расширений, которые находятся во встроенном центре дополнений. Теперь вы знаете не только то, как настроить почту Thunderbird, но и насколько простыми могут быть, казалось бы, сложные программы.
На завершение, видео о том, как заставить Thunderbird сворачиваться при запуске:
Одна из самых первых задач, которую надо сделать после установки нового жесткого диска или SSD накопителя в компьютер, это отформатировать его и создать на нём разделы, на которых будут размещены данные. Форматировать диск можно разными способами. Для этого существует несколько консольных утилит с разным уровнем сложности работы, такие как fdisk, cfdisk и parted, а также графические утилиты, например GParted и Gnome Диски.
Про каждую из консольных утилит на этом сайте уже есть отдельная статья. Поэтому в этой статье мы поговорим как выполняется форматирование диска в Linux с помощью графических инструментов. Читать далее Форматирование диска в Linux→
MySQL - это одна из самых популярных реляционных систем управления базами данных, которая используется для обеспечения большинства веб-сайтов в интернете. От скорости записи и получения данных из таблиц зависит скорость работы сайта, в целом, так как, если на один запрос будет уходить больше секунды, то это будет тормозить работу php, а в следствии скоро накопиться столько запросов, что сервер не сможет их обработать.
В сегодняшней статье мы поговорим о том, как выполняется оптимизация производительности mysql. Какие программы для этого лучше использовать и как это работает.
Скорость работы MySQL
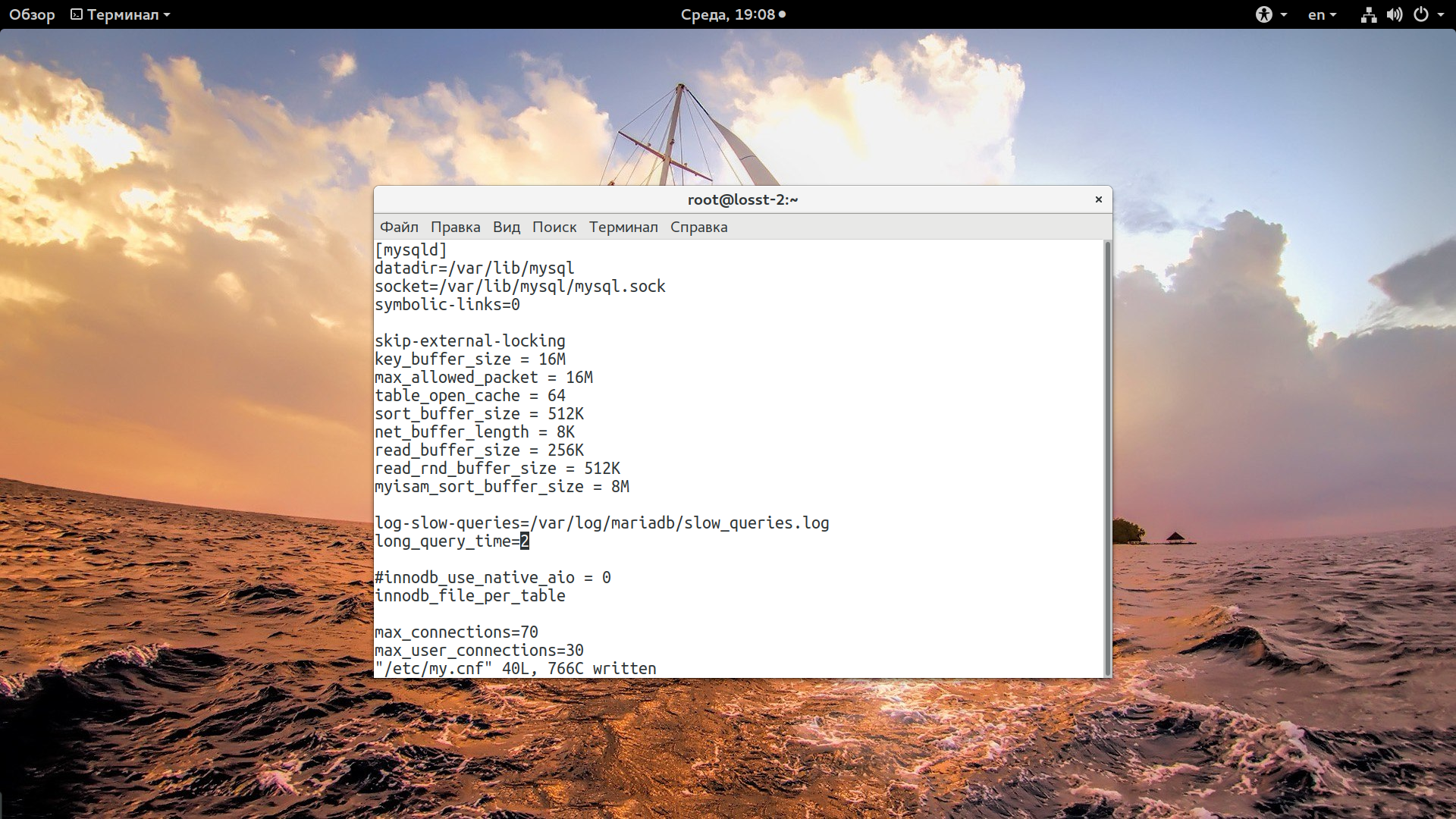
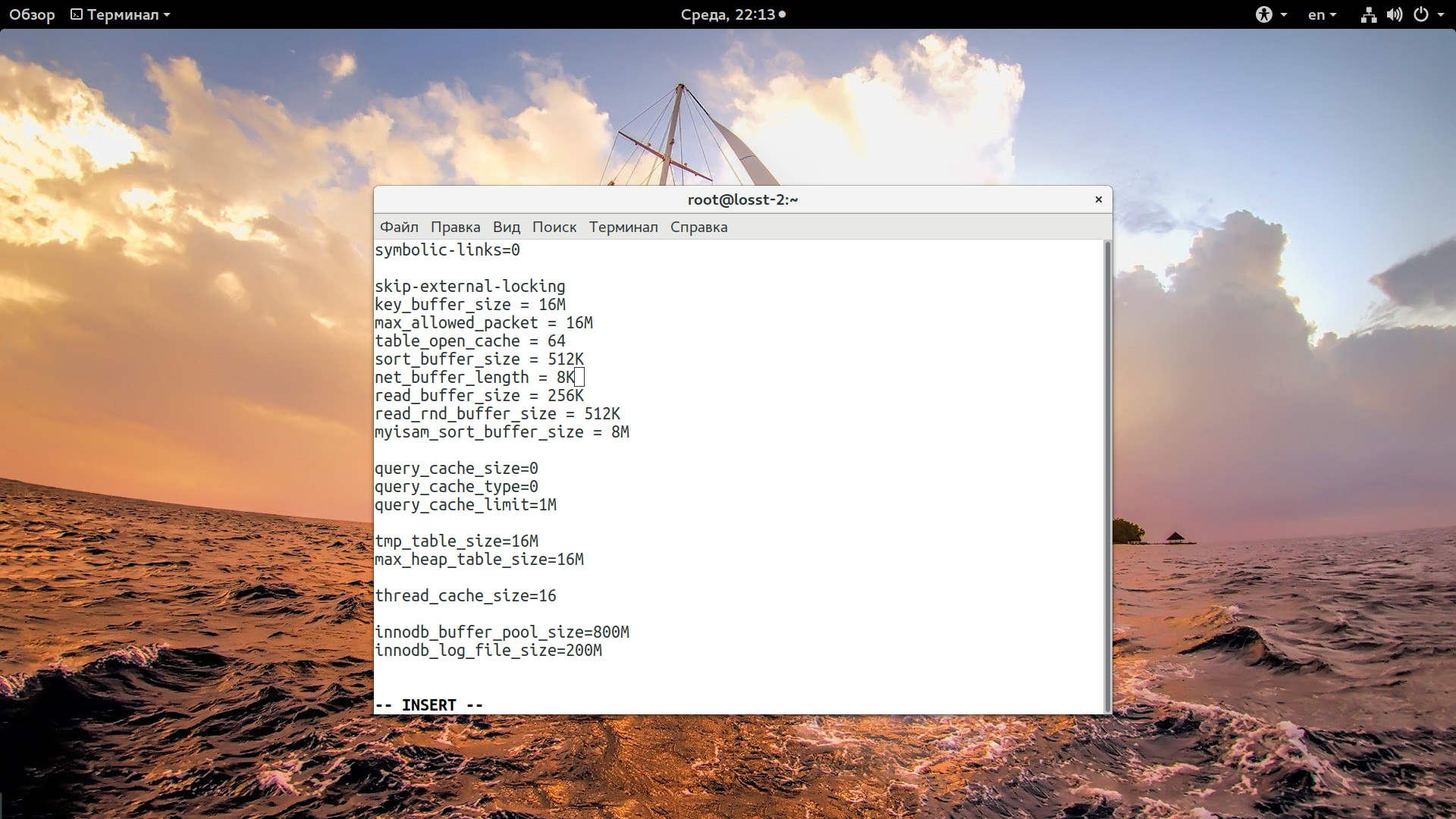
Оптимизация без аналитики бессмысленна. Перед тем как переходить к оптимизации давайте посмотрим как работает база данных сейчас, есть ли запросы, которые выполняются очень медленно. Все настройки вашего сервиса mysql находятся в файле /etc/my.cnf. Чтобы включить отображение медленных запросов добавьте такие строки в my.cnf, в секцию [mysqld]:
Здесь первая строка включает запись лога медленных запросов, вторая указывает, что минимальное время запроса для внесения его в этот лог - две секунды. Еще можно включить в лог запросы, которые не используют индексы:
log-queries-not-using-indexes=1
Но это уже необязательно для проверки скорости и используется больше для отладки кода и правильности создания таблиц. Дальше перезапустите сервер баз данных и посмотрите лог:
systemctl restart mariadb
tail -f /var/log/mariadb/slow-queries.log
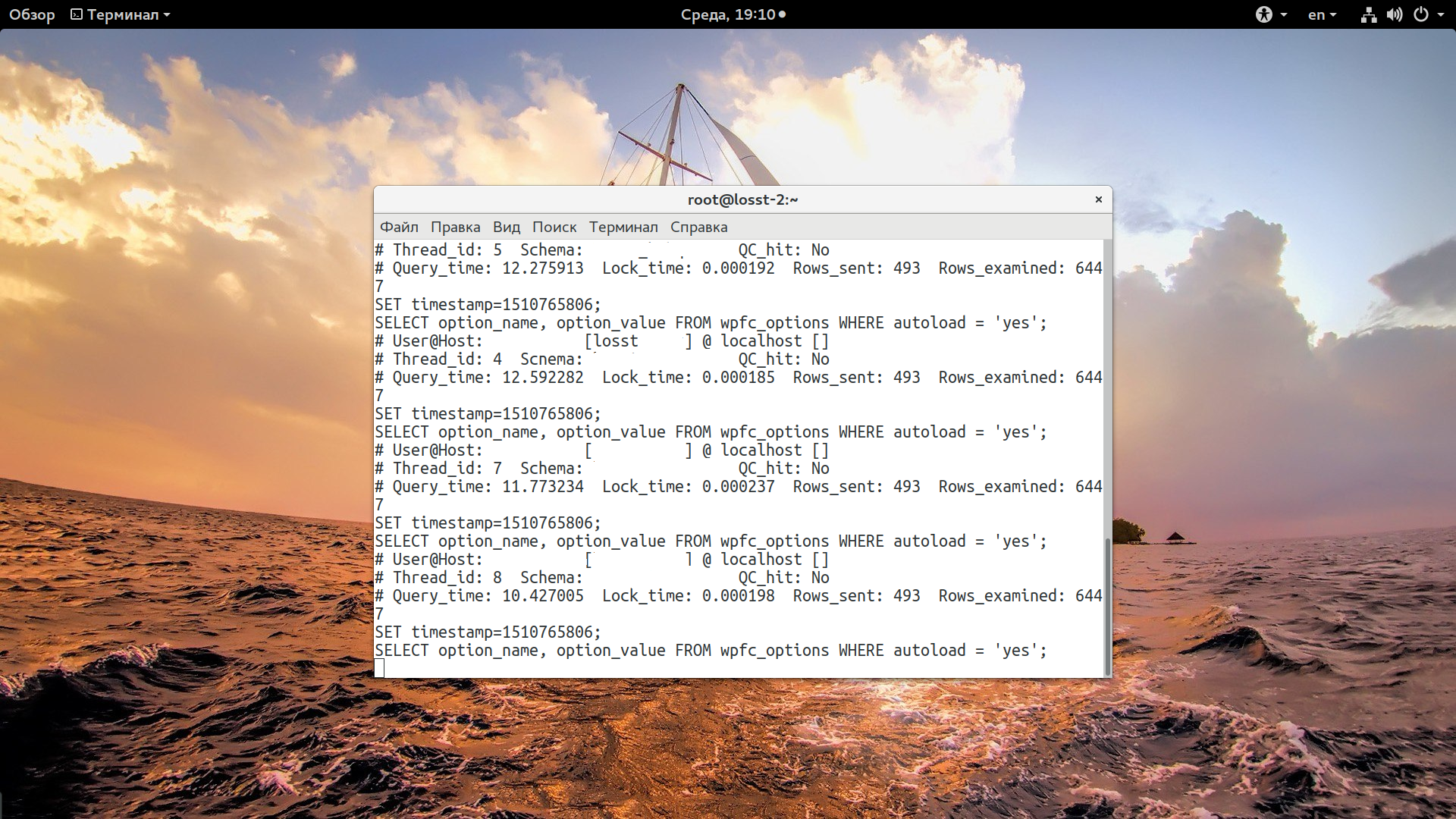
Мы можем видеть, что есть запросы, которые выполняются больше, чем 10 секунд. Это, например, запрос
SELECT option_name, option_value FROM wp_options WHERE autoload = 'yes';
Можно его выполнить отдельно, в консоли mysql:
Здесь тоже измеряется время, и мы видим результат - три секунды. Это очень много. И еще ничего, если такие запросы приходят редко, если ваш сайт постоянно под нагрузкой, то тремя секундами вы не отделаетесь, количество необработанных запросов будет расти, а скорость ответа увеличиваться до нескольких минут. Можно пойти двумя путями - оптимизировать код, убрать сложные запросы, или же нужна оптимизация mysql на сервере.
Оптимизация MySQL
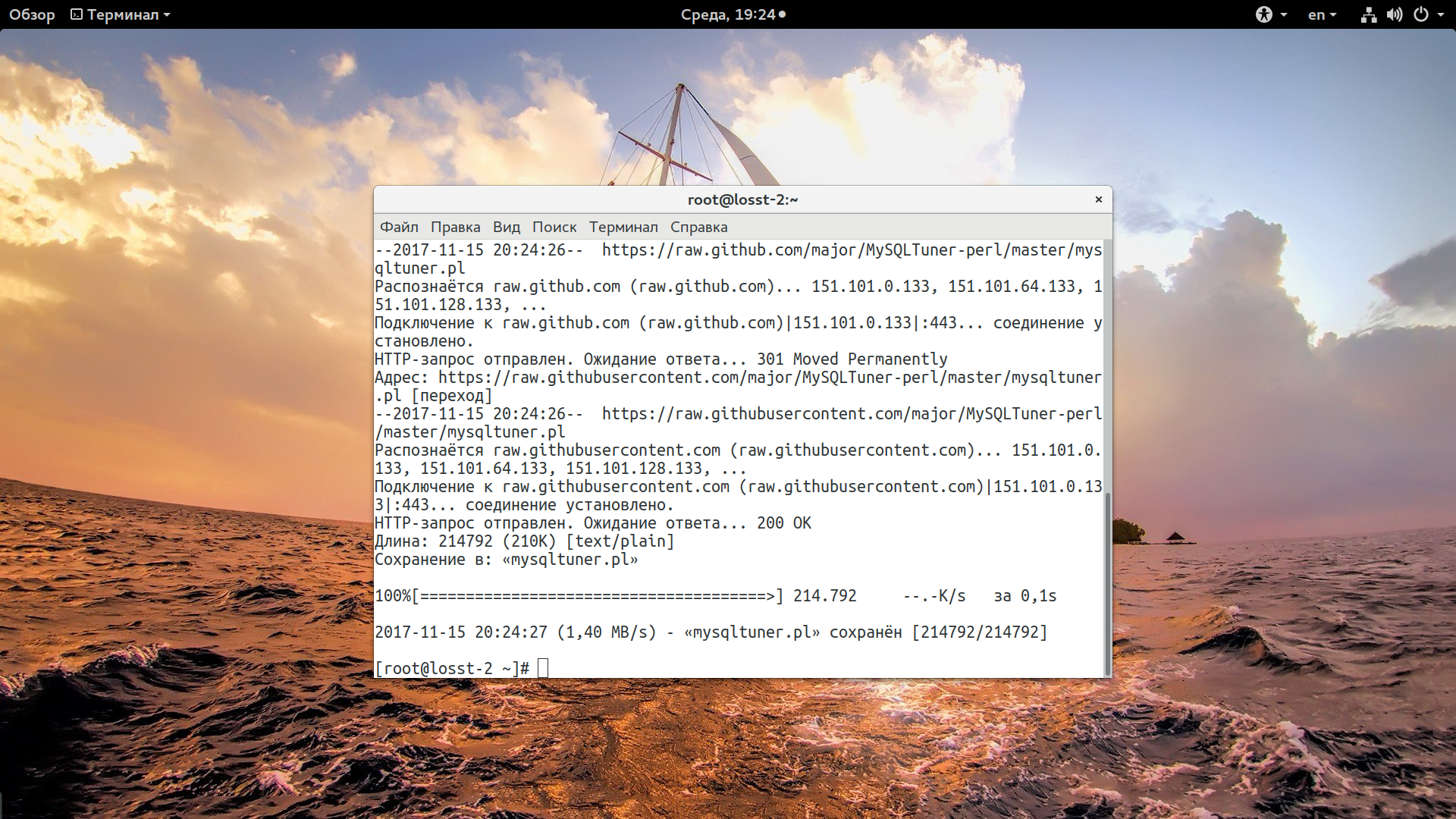
Конфигурация MySQL достаточно сложная, но, к счастью, вам не нужно в нее сильно углубляться. Есть специальный скрипт под названием MySQLTunner, который анализирует работу MySQL и дает советы какие параметры нужно изменить и какие значения для них установить. Скрипт поддерживает большинство версий MariaDB, MySQL и Percona XtraDB. Нам понадобится загрузить три файла с помощью wget:
Первый из них - это сам скрипт, написанный на Perl, второй и третий - база данных простых паролей и уязвимостей. Они позволяют обнаружить проблемы с безопасностью. Дальше можно переходить к тестированию. Я использую сервер с настройками mysql по умолчанию, установленными панелью управления VestaCP.
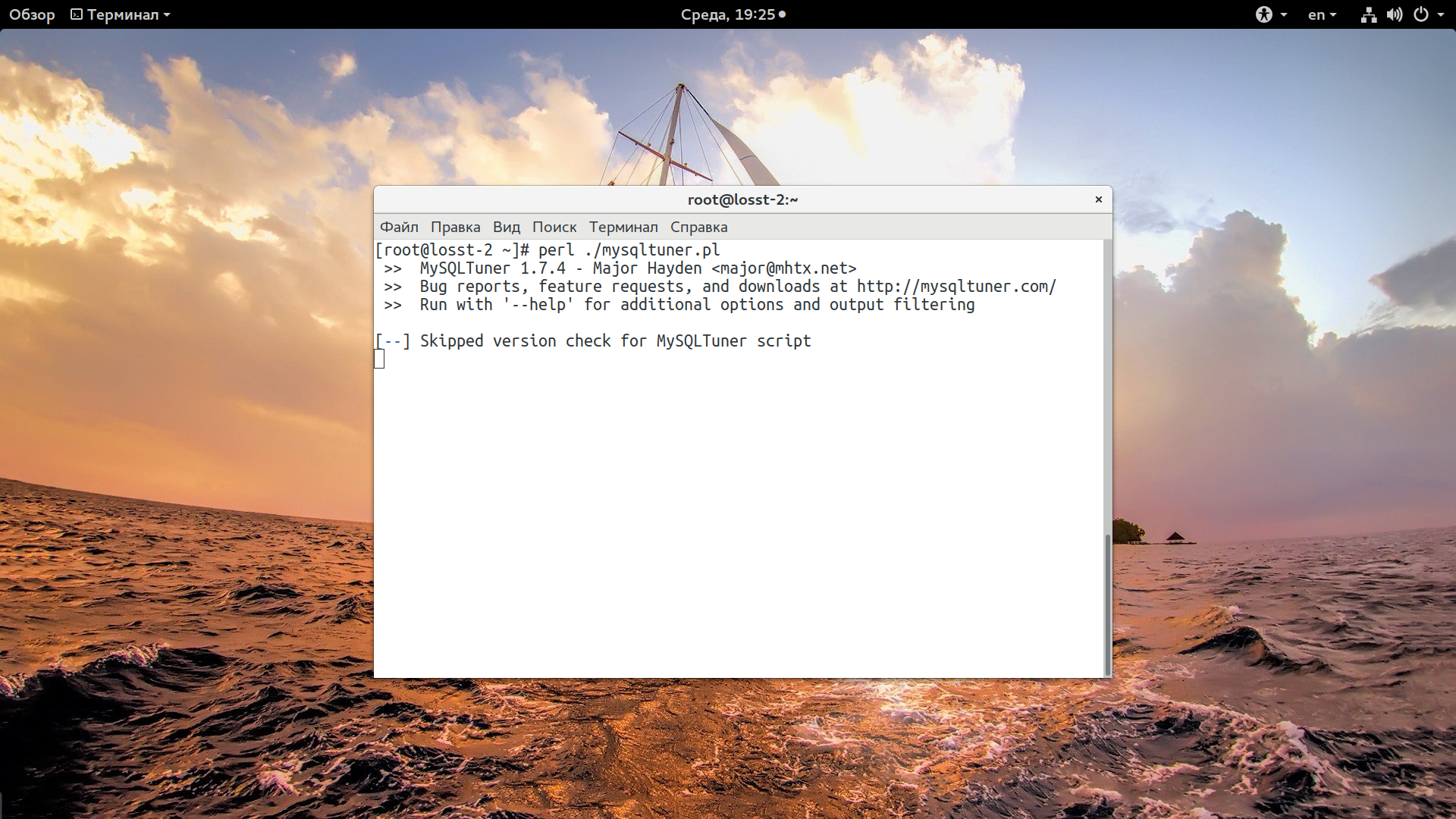
perl ./mysqltuner.pl
Буквально за несколько минут скрипт выдаст полную статистику по работе MySQL. Количеству запросов, занимаемому объему памяти и эффективности работы буферов. Вы можете ознакомиться со всем этим, чтобы лучше понять в чем причина проблем. Проблемные места обозначены красными восклицательными знаками. Например, здесь мы видим, что размер буфера движка таблиц InnoDB (InnoDB buffer pool) намного меньше, чем должен быть для оптимальной работы:
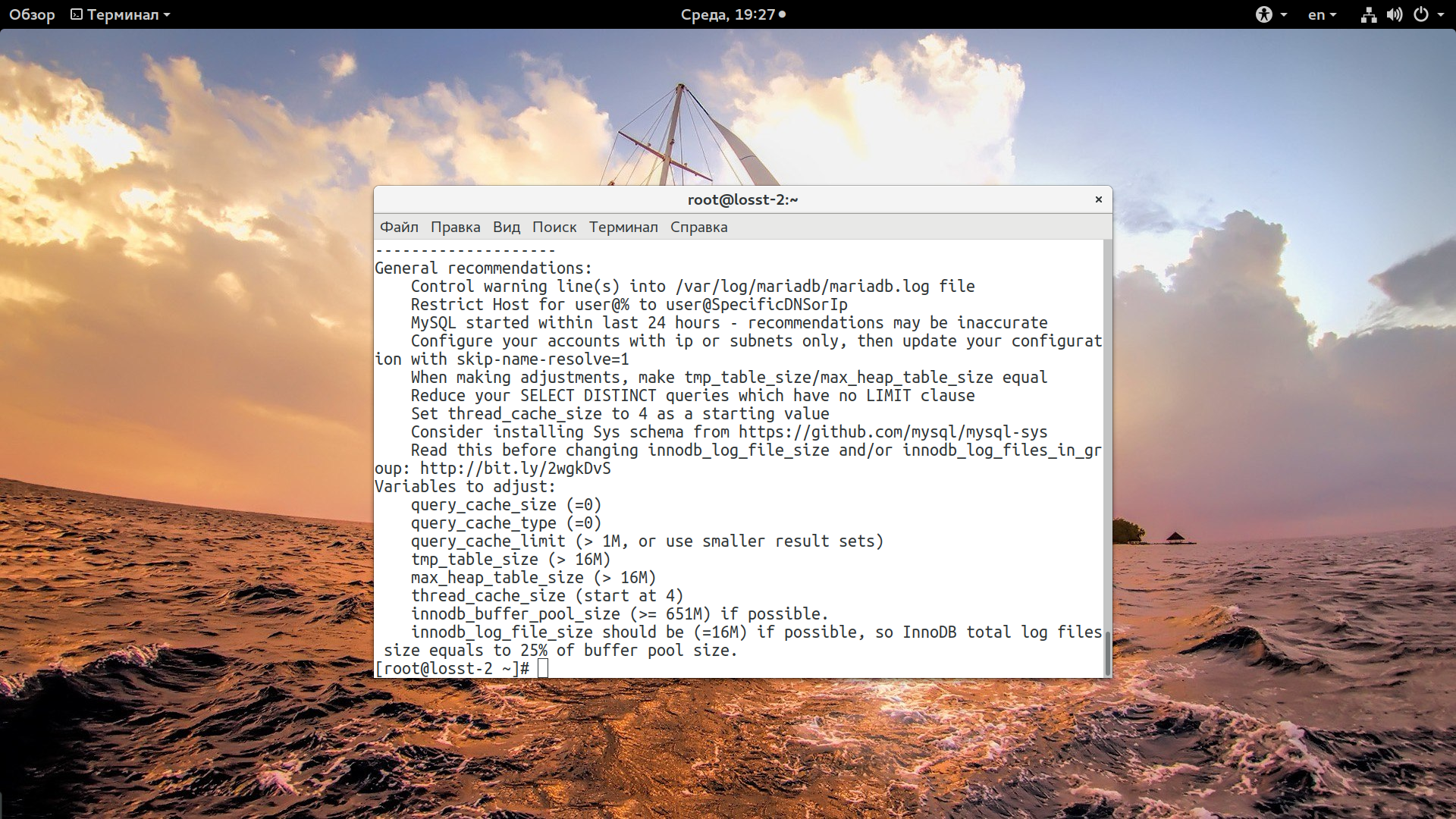
Кроме того, в самом конце вывода утилита предоставит список рекомендаций как исправить ситуацию. Мы рассмотрим все сообщения утилиты из этого примера и почему нужно использовать именно их, а не другие.
Все параметры нужно добавлять в /etc/my.cnf. Еще раз замечу, что вы не копируете статью, а смотрите что вам выдала утилита. Начнем с query-cache.
Скрипт рекомендует отключить кэш запросов. Query Cache - это кэш вызовов SELECT. Когда базе данных отправляется запрос, она выполняет его и сохраняет сам запрос и результат в этом кэше. И все бы ничего, но при использовании его вместе с InnoDB при любом изменении совпадающих данных кэш будет перестраиваться, что влечет за собой потерю производительности. И чем больше объем кэша, тем больше потери. Кроме того при обновлении кэша могут возникать блокировки запросов. Таким образом, если данные часто пишутся в базу данных - его надежнее отключить.
tmp_table_size=16M
max_heap_table_size=16M
Оба параметра устанавливают размер памяти, которая используется для внутренних временных таблиц MySQL. Утилита рекомендует использовать объем больше 16 мегабайт, просто установите это ваше значение для обоих переменных, если у вас достаточно памяти, то можно выделить 32 или даже 64. Но важно чтобы оба значения совпадали, иначе будет использоваться минимальное.
thread_cache_size=16
Этот параметр отвечает за количество потоков, которые будут закэшированны. После того, как работа с подключением будет завершена, база данных не разорвет его, а закэширует, если количество кэшированных потоков не превышает ограничение. Утилита рекомендует больше четырех, например, 16.
skip-name-resolve=1
Указывает, что не нужно пытаться определить доменное имя для подключений извне. Ускоряет работу, так как не тратится время на DNS запросы.
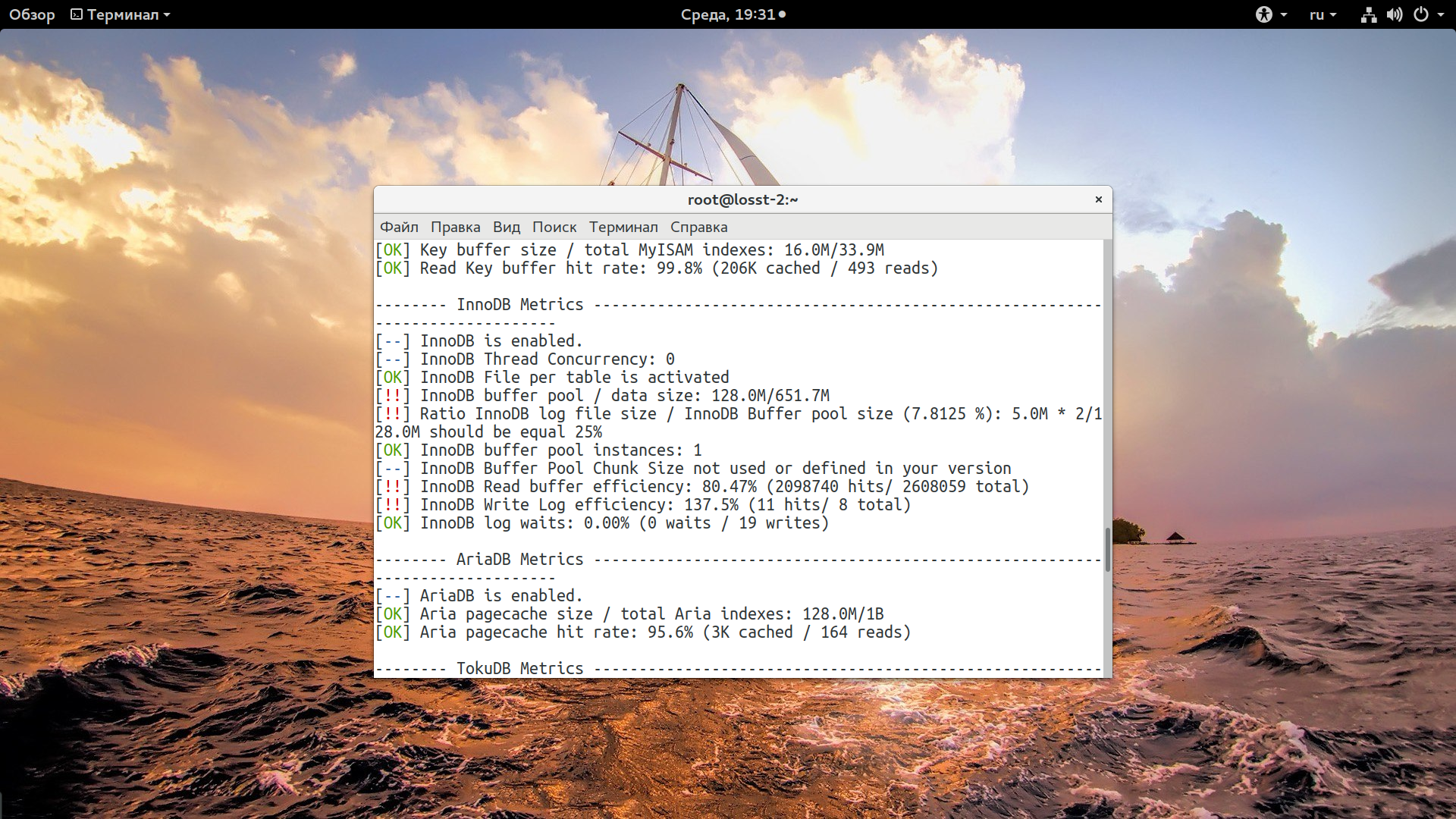
innodb_buffer_pool_size=800M
Этот параметр определяет размер буфера InnoDB в оперативной памяти, от этого размера очень сильно зависит скорость выполнения запросов. Значение зависит от размера ваших таблиц и количества данных в них. Если памяти недостаточно, запросы будут обрабатываться дольше. У меня используется стандартный объем 128, а нужно больше 652.
innodb_log_file_size=200M
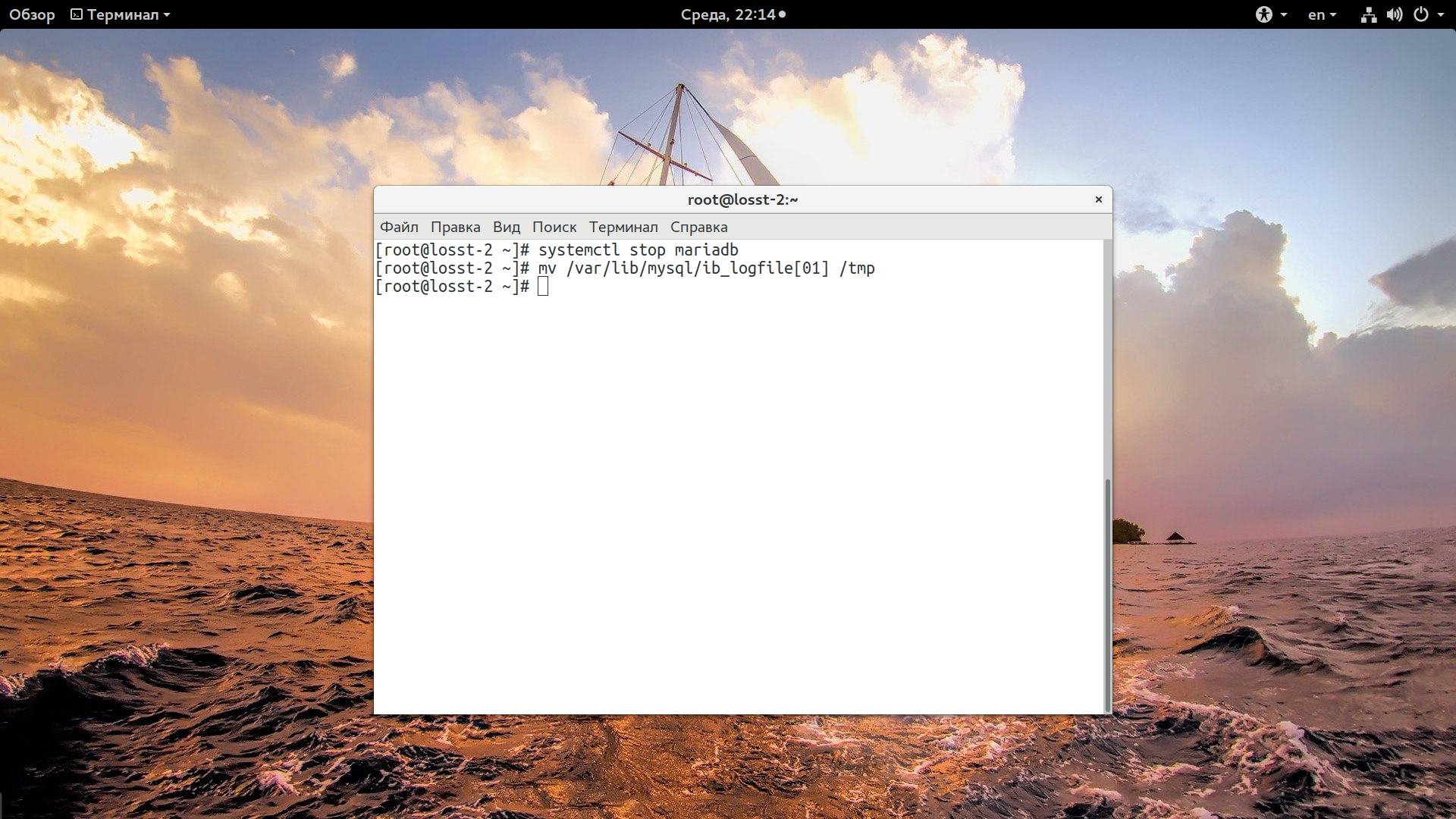
Размер файла лога innodb должен составлять 25% от размера буфера. В случае 800 мегабайт это будет 200М. Но тут есть одна проблема. Чтобы изменить размер лога нужно выполнить несколько действий. Поскольку мы изменили все нужные параметры перейдем к перезагрузке сервера. Для нашего лога нужно остановить сервис:
systemctl stop mariadb
Затем переместите файлы лога в /tmp:
mv /var/lib/mysql/ib_logfile[01] /tmp
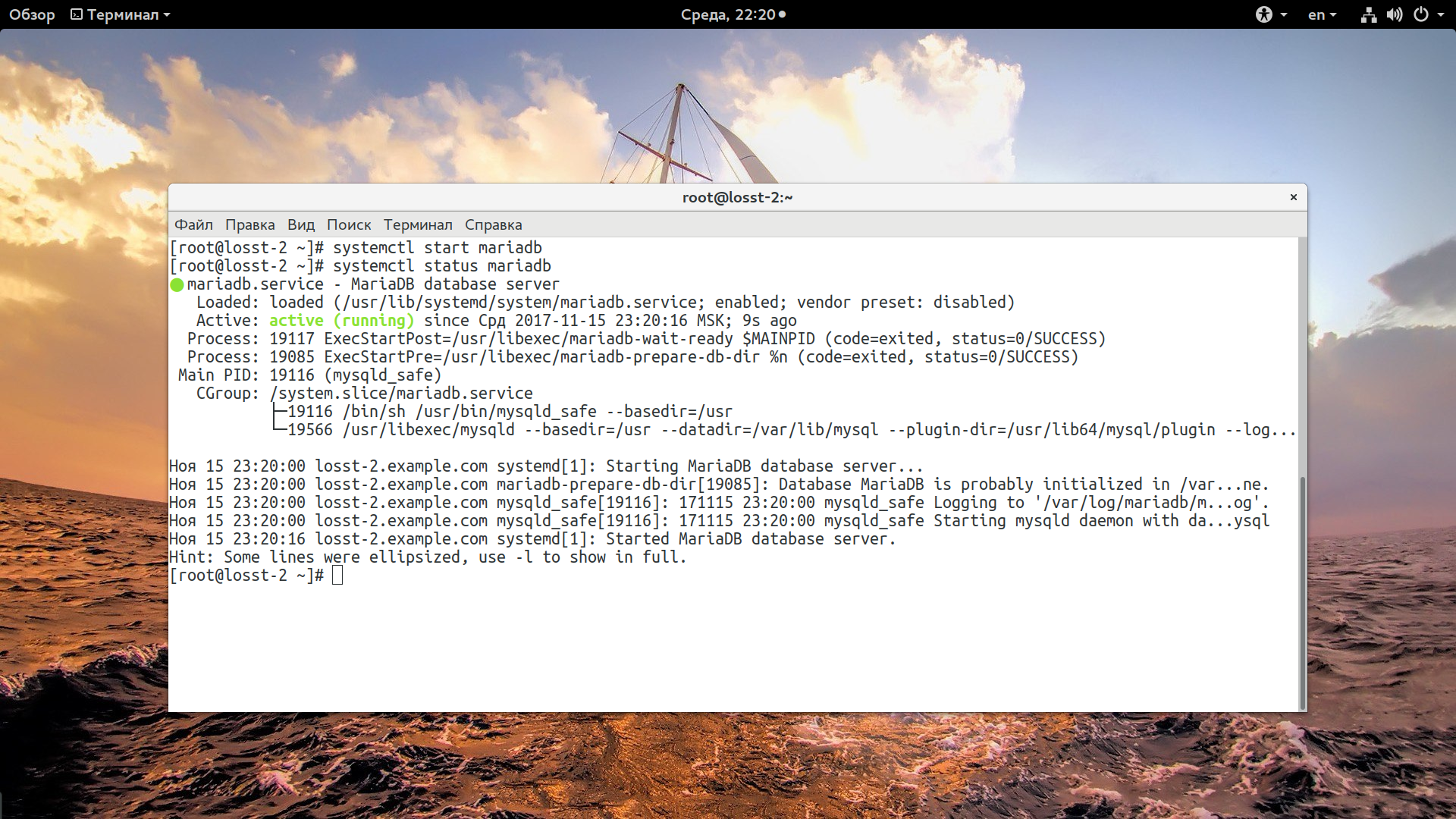
И запустите сервис:
systemctl start mariadb
Когда размер лога меняется сервис видит поврежденный лог, выдает ошибку и не запускается. Поэтому сначала нужно удалить старый. После этого смотрите есть ли сообщения об ошибках:
systemctl status mariadb
Тестирование результата
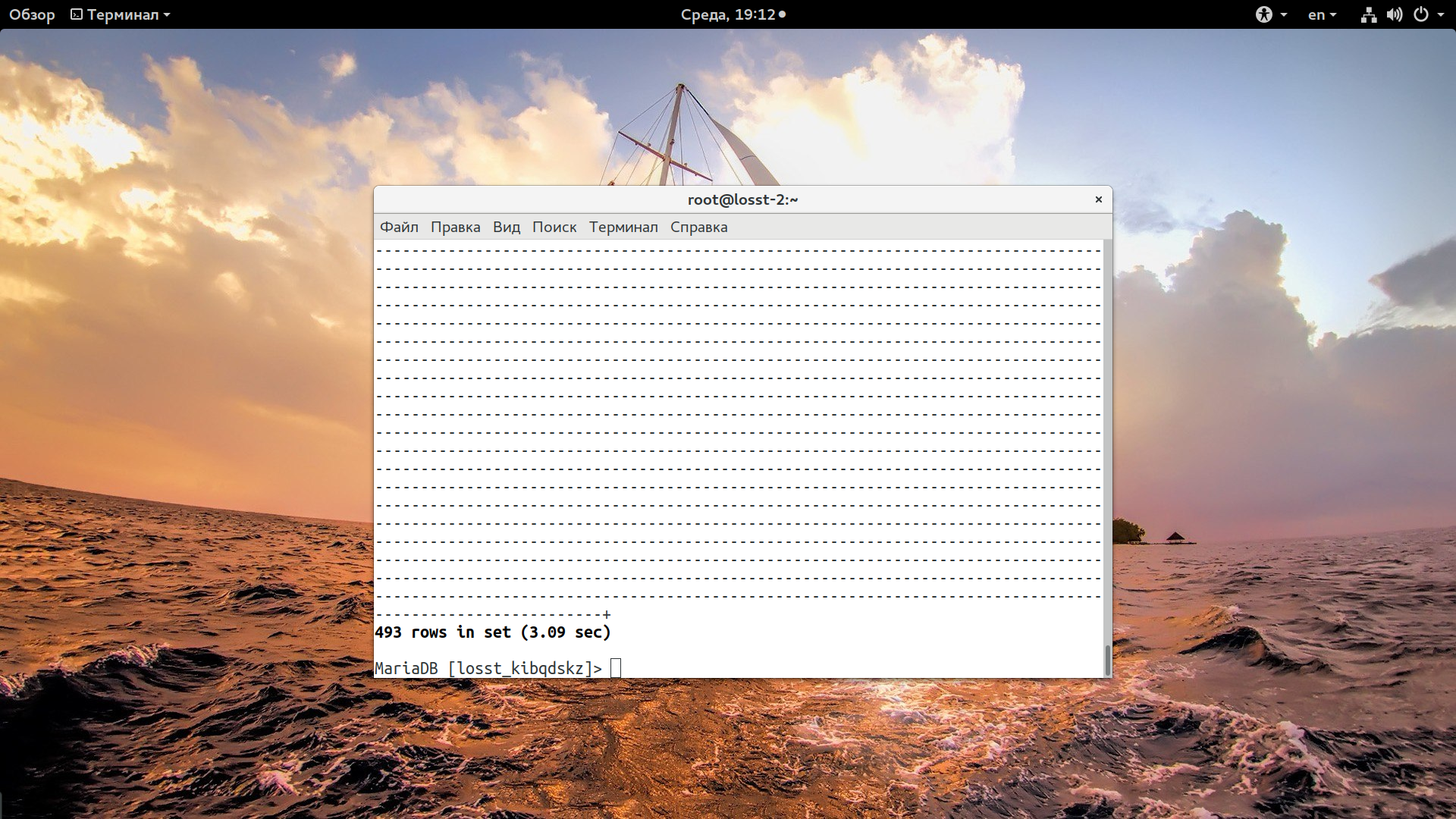
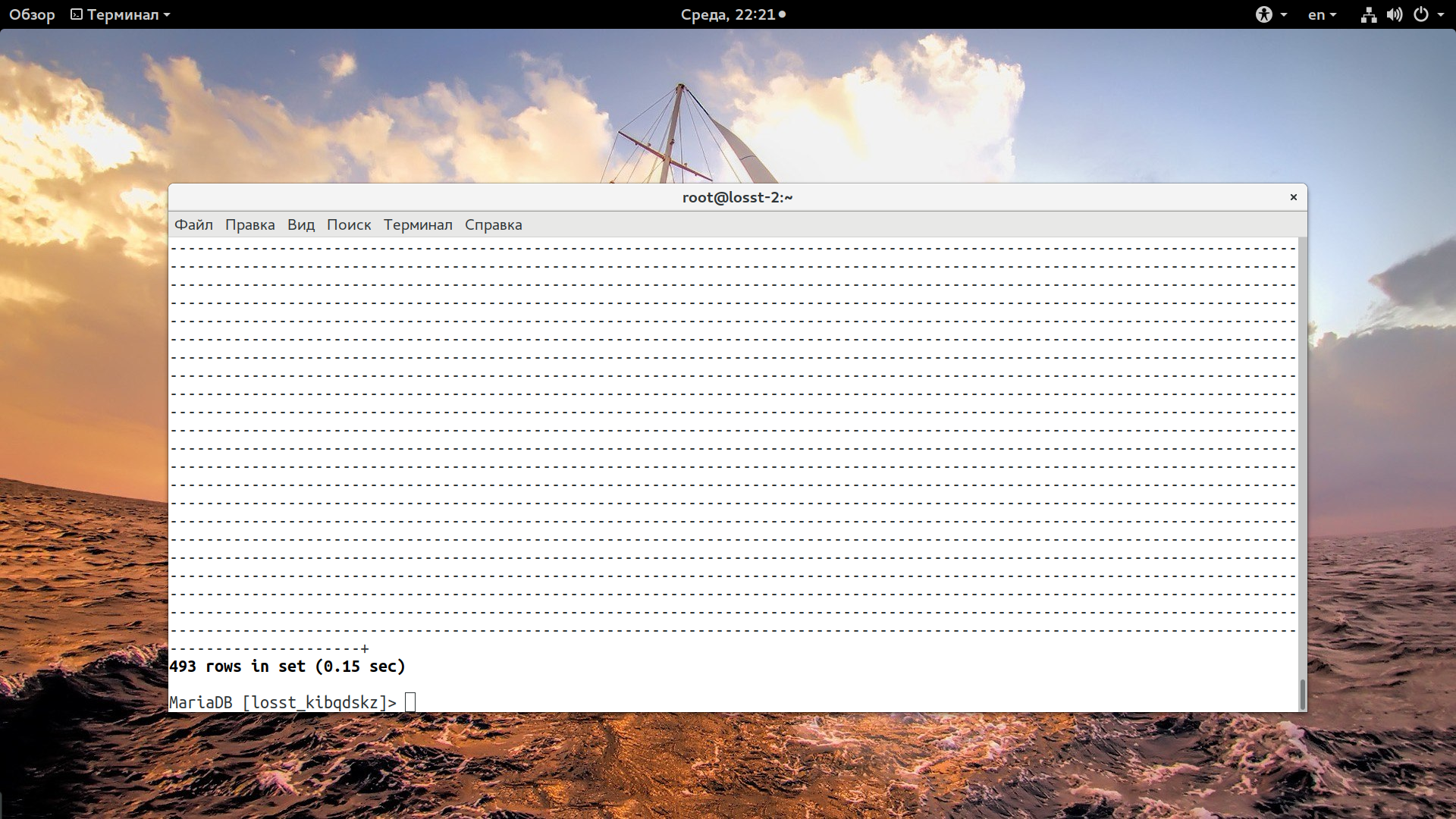
Готово оптимизация базы данных mysql завершена, теперь тестируем тот же запрос через клиент mysql:
mysql
> USE база_данных; > SELECT option_name, option_value FROM wpfc_options WHERE autoload = 'yes';
Первый раз он выполняется долго, может даже дольше чем обычно, но все последующие разы буквально мгновенно. Результат с более 3 секунд до 0,15. А если брать статистику из slow-log, то от более 12. Если в выводе утилиты для вас были предложены и другие оптимизации, то их тоже стоит применить.
Выводы
Как видите, оптимизация mysql это достаточно просто благодаря такому скрипту, но, в то же время, такая операция может очень сильно помочь, особенно высоконагруженным проектам. Еще лучше ускорить работу может только оптимизация запросов mysql. Не забывайте время от времени проверять параметры, чтобы быть уверенным что все в порядке. Если у вас остались вопросы, спрашивайте в комментариях!
На завершение лекция про производительность MySQL от Percona:
Apache - это один из самых популярных веб-серверов, которые используются для размещения сайтов. Наверное, он даже популярнее, чем Nginx, поскольку его намного проще настроить и есть поддержка изменения конфигурации для каждой отдельной папки с помощью файлов htaccess, причем сразу же, на лету. Но когда вы поменяли глобальные настройки Apache или изменили параметры PHP, Apache необходимо перезагрузить.
В этой небольшой статье мы рассмотрим какими способами выполняется перезапуск apache ubuntu и как это делать более правильно.
Если вы начинающий администратор или только перенесли свой проект на VPS и еще не со всем разобрались, то у вас может возникнуть вопрос как перезапустить Nginx. Это очень популярный веб-сервер, такой же популярный, как и Apache и достаточно часто используется для различных проектов.
Перезапуск веб-сервера может понадобиться после того, как вы изменили его настройки, добавили новый домен и так далее. В этой небольшой статье мы рассмотрим как выполняется перезагрузка Nginx на сервере.




 ;
;
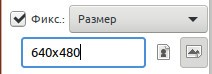 Четкое задание размеров области выделения. Нужно только кликнуть мышкой на изображении и сразу же выделится участок заданным размером (в данном случае 640x480).
Четкое задание размеров области выделения. Нужно только кликнуть мышкой на изображении и сразу же выделится участок заданным размером (в данном случае 640x480).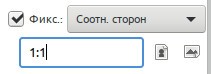 В этом случае соотношение сторон области выделения будет равно 1:1 (можно было использовать 5:5, 100:100, 99:99 было бы тоже самое).
В этом случае соотношение сторон области выделения будет равно 1:1 (можно было использовать 5:5, 100:100, 99:99 было бы тоже самое).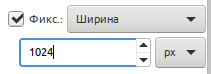 Ширина фиксирована, высота может быть любой.
Ширина фиксирована, высота может быть любой.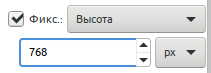 Высота фиксирована, ширина может быть любой.
Высота фиксирована, ширина может быть любой.