Ваш путеводитель по одной из самых популярных и влиятельных операционных систем в мире. От базовых команд и установки дистрибутивов до глубокого изучения ядра и сетевых технологий — здесь вы найдете статьи и руководства на самые разные темы, связанные с Linux. Независимо от вашего уровня подготовки, здесь найдется что-то интересное и полезное.
Новичков в мире Linux часто запутывает многообразие дистрибутивов Linux. Часто им сложно понять что это такое и они теряются в их огромном количестве. Но на самом деле здесь все можно сгруппировать и представить в виде целостной картины чтобы было легче все понять и ориентироваться.
Мы уже говорили о том, что такое дистрибутив в отдельной статье. Фактически - это ядро Linux и набор различного программного обеспечения, то же самое будем подразумевать под операционной системой Linux. Некоторые операционные системы Linux используют ядро Linux неизменным, другие изменяют его для получения большей безопасности или реализации необходимых функций. Преимущества той или иной операционной системы на Linux зависят от набора программного обеспечения, которое в ней используется. В этой статье мы рассмотрим основные виды операционных систем Linux, которые сейчас существуют.
Большинство домашних сетей получают доступ к интернету через маршрутизаторы или модемы. Нам не так часто нужно менять настройки маршрутизатора, но временами возникает такая необходимость. Обычно эти настройки можно открыть, набрав локальный ip адрес маршрутизатора в строке браузера. Также иногда может понадобится узнать ip адрес роутера для других действий или тестирования работы сети.
К сожалению, нет одного стандартного адреса, который бы использовали все маршрутизаторы, очень часто используется 192.168.1.1, но это не является правилом и можно встретить любые адреса из диапазона локальных сетей. На самом деле есть множество способов как узнать ip роутера wifi, так и в обычной сети.
КАК УЗНАТЬ IP РОУТЕРА В LINUX?
Первое место, где стоит посмотреть независимо от вашей операционной системы — это документация для вашего роутера. Там точно есть инструкция по настройке и в ней указан адрес, на котором можно открыть веб-интерфейс.
ЛОКАЛЬНЫЙ АДРЕС РОУТЕРА
Далее, вы можете использовать утилиты просмотра информации о сети. Компьютер активно взаимодействует с роутером для передачи данных в сеть и мы можем посмотреть адрес шлюза, который и будет адресом роутера. Команда ip:
ip route show
Здесь в первой же строке будет отображен адрес шлюза, через который передается весь трафик по умолчанию, в моем случае тот же самый 192.168.1.1. Если вы не хотите использовать команду ip, можно посмотреть таблицу маршрутизации пакетов командой route:
route -n
Тут тоже первая запись будет означать адрес маршрутизатора. Еще один путь узнать ip маршрутизатора — посмотреть таблицу записей ARP:
arp -a
Здесь все еще проще, если компьютер взаимодействует только с роутером, то будет выведена одна запись — адрес роутера. Подобную информацию может выдать и утилита netstat:
netstat -r -n
ВНЕШНИЙ АДРЕС РОУТЕРА
Если вы счастливый обладатель белого IP адреса или даже серого, который на спрятан за NAT и вас интересует как узнать внешний ip роутера, то для этого тоже есть простая команда:
curl http://ipecho.net/plain
Еще можно открыть эту же страницу в браузере:
Или ifconfig.me:
curl ifconfig.me
КАК УЗНАТЬ IP АДРЕС РОУТЕРА В WINDOWS?
Самый простой способ узнать ip адрес роутера в Windows — использовать утилиту командной строки ipconfig. Кликните правой кнопкой по значку пуск, затем выберите «Командная строка»
В открывшемся окне наберите:
ipconfig
Адрес роутера будет отображен напротив «Основной адрес шлюза». Еще один способ узнать IP адрес роутера — это использовать стандартную утилиту настроек. Кликните по значку сетевые подключения, выберите «Открыть центр управления сетями и общим доступом»:
Кликните по сети, к которой вы подключены:
Затем нажмите кнопку сведения:
Здесь и будет отображен адрес шлюза среди прочей другой информации. Если вам нужен внешний адрес, вы можете открыть в браузере те же сайты, что и для Linux.
ВЫВОДЫ
В этой статье мы рассмотрели как узнать ip роутера в сети. Как видите, это совсем не сложно, и существует множество методов, из которых вы можете выбрать тот, который будет более удобным для вас. Если у вас остались вопросы, спрашивайте в комментариях!
Многие программы мы используем постоянно и запускаем их каждый раз при старте системы, а некоторые, такие, как мессенджеры или различные утилиты должны постоянно работать в фоне чтобы правильно выполнять свою задачу. Для этого в операционных системах существует автозагрузка. Программы запускаются автоматически, после того, как запустилась ОС или графическая оболочка.
В этой статье мы поговорим о том, как работает автозагрузка в Ubuntu, какие существуют способы автозагрузки в этой системе и как добавить туда программы.
АВТОЗАГРУЗКА В UBUNTU
Первым делом нужно сказать, что в Ubuntu существует несколько уровней автозагрузки. Я не буду говорить здесь про systemd и автозагрузку сервисов, так как уже рассматривал это в одной из первых статей. Программу или скрипт можно добавить в автозагрузку такими путями:
Утилита «Автоматически запускаемые приложения»;
Папка «Автозапуск»;
Файл rc.local;
Файл Xinitrc;
Мы рассмотрим первые два способа, поскольку два последние более рассчитаны на скрипты, а не программы. Сначала автозагрузка в Ubuntu с помощью стандартной утилиты.
Откройте меню системы и наберите «Авто» и откройте программу, которая будет первой в списке, Автоматически запускаемые приложения:
Здесь будут перечислены все приложения, которые сейчас запускаются автоматически. Чтобы добавить в автозагрузку ubuntu еще одно приложение, нажмите кнопку «Добавить»:
Здесь нужно ввести имя нового пункта, а также команду запуска приложения. Вы можете выбрать приложение в файловой системе, если не помните путь, нажав кнопку «Обзор»:
В команде можно указывать параметры, если это нужно. Еще можно заполнить поле «Описание», но это уже необязательно. Если вам нужна определенная программа из главного меню, но вы не знаете где ее найти и как пишется ее команда, можно посмотреть ее в том же меню. Но для этого нам нужно сначала установить утилиту «Главное меню» из центра приложений:
Дальше запустите утилиту и найдите в ней нужное приложение. Затем нажмите «Свойства»:
Здесь вам нужно обратить внимание на строку «Команда», скопируйте ее и можете использовать для автозагрузки.
Следующий способ — это папка автозагрузки. Она находится по адресу ~/.config/autostart. По сути, это тот же самый способ, только он может выполняться без графического интерфейса. Когда вы настраиваете автозагрузку через приложение, то в этой папке создаются файлы настроек с именем desktop. Вот, например:
Напоминаю, что для того, чтобы посмотреть скрытые файлы нужно нажать сочетание клавиш Ctrl+H. Теперь попытаемся создать новый конфигурационный файл для еще одной программы. Вот таким будет его синтаксис:
Для примера, сделаем файл для запуска плеера VLC, он будет выглядеть вот так:
vi ~/.config/autostart/vlc.desktop
[Desktop Entry]
Type=Application
Name=VLC
Exec=vlc
Icon=/usr/share/icons/hicolor/16x16/apps/vlc.png
Comment=VLC Media Player
X-GNOME-Autostart-enabled=true
Готово, и самое интересное, что если вы откроете приложение автозагрузки. То там тоже появится этот пункт. Это такой способ настройки без графического интерфейса.
ВЫВОДЫ
В этой небольшой статье мы рассмотрели как настраивается автозагрузка программ ubuntu различными способами — через графический интерфейс и терминал. Вы можете использовать эти знания, чтобы сделать работу в вашей системе более удобной. Даже несмотря на то, что Ubuntu перешла на Gnome, автозагрузка в ubuntu 16.04 и сейчас выглядят практически одинаково. Если у вас остались, вопросы, спрашивайте в комментариях!
PostgreSQL или Postgres — это объектно-реляционная система управления базами данных с открытым исходным кодом, которая активно разрабатывается уже более чем 15 лет. Сервер баз данных может использоваться для работы высоко нагруженных систем и решения сложных промышленных задач. PostgreSQL может использоваться в Linux, Unix, BSD и Windows.
Репликация баз данных методом Master-Salve — это процесс копирования (синхронизации) данных из базы данных на одном сервере (Master), в базу данных на другом сервере (Salve). В этой статье мы рассмотрим как настраивается репликация PostgreSQL в Ubuntu.
ПРЕИМУЩЕСТВА РЕПЛИКАЦИИ
Основное преимущество — распределение базы данных между несколькими машинами. Если с основным сервером что-то происходит и он перестает работать, то данные все еще доступны на резервном сервере и могут быть без труда получены или восстановлены. Работа проекта продолжится без каких-либо трудностей.
В PostgreSQL доступно несколько способов репликации базы данных в зависимости от цели репликации. Можно настраивать репликацию только для резервного копирования или для организации отказоустойчивого сервера баз данных. Мы будем использовать репликацию типа Master-Salve. Она более подходит для резервного копирования. Для реализации будет использоваться модуль standby.
УСТАНОВКА И НАСТРОЙКА POSTGRESQL
Мы уже подробно рассматривали как установить Postgresql в Ubuntu в одной из предыдущих статей. Но в этой статье повторим эти команды более кратко. Установить и выполнить первоначальную настройку сервера нужно на обоих машинах. Если вы используете последние версии Ubuntu — 17.04 или 17.10, то версия PostgreSQL 9.6 уже есть в официальных репозиториях. Для более старых систем можно использовать PPA:
По умолчанию PostgreSQL запускается на порту 5432. Вы можете убедиться, что этот порт имеет состояние LISTEN выполнив команду netstat:
netstat -plntu
После того как Postgresql запущен, нам нужно настроить пароль для пользователя Postgres. Но для этого вам нужно авторизоваться под этим пользователем в системе:
sudo su - postgres
Затем, войдите в консоль управления:
psql
Осталось выполнить такую команду, чтобы задать пароль:
\password postgres
Осталось разрешить общение компьютеров между собой по сети на порту 5432 в брандмауэре:
Напоминаю, что эти действия нужно проделать на обоих машинах.
НАСТОЙКА РЕПЛИКАЦИИ POSTGRESQL
Сначала настроем мастер-сервер. Это основной сервер, который будет выполнять основные действия записи и рассылать данные на сервера Salve. Приложения могут не только читать, но и записывать данные взаимодействуя с этим сервером. Для его настройки нам нужно изменить содержимое файла postgresql.conf в папке /etc/postgresql/9.6/main/:
Сначала расскоментируйте строчку listen_address и пропишите в ней ip адрес вашего сервера. Порт должен быть 5433 иначе не заработает:
listen_address = '192.168.56.101' port=5433
Расскоментируйте строчку wal_level и установите значение standby, она отвечает за способ репликации:
wal_level = hot_standby
Мы будем использовать локальную синхронизацию:
synchronous_commit = local
Включите режим архивирования и укажите команду для создания архива:
archive_mode = on archive_command = 'cp %p /var/lib/postgresql/9.6/archive/%f'
Теперь настроем куда именно будет выполняться синхронизация. В нашей инструкции мы будем использовать только два сервера — Master и Salve. Поэтому в строке max_wal_senders поставьте значение 2:
max_wal_senders = 2 wal_keep_segments = 10
Установите имя нашего сервера синхронизации:
synchronous_standby_names = 'pgslave01'
Теперь конфигурационный файл можно закрыть. Поскольку мы включили режим архивирования, нужно создать папку для архивов и отдать ее пользователю postgres:
Дальше нам нужно отредактировать файл pg_hba.conf, он отвечает за аутентификацию пользователей. Здесь нужно прописать каждый сервер, базу данных, адрес и метод аутентификации. Синтаксис файла такой:
Дальше нам нужно создать нового пользователя, у которого будут права на репликацию. Назовите его replica:
su - postgres createuser --replication -P replica
После всех этих действий настройка репликации postgresql на сервере Master завершена и он готов к работе. Дальше настроем сервер Salve. Тут все проще. Мы собираемся заменить директорию data этого сервера, на эту же директорию из сервера master и поддерживать их синхронизацию. Сначала остановите службу:
systemctl stop postgresql-9.6
Затем сделайте резервную копию текущей директории, если там есть важные данные и вы боитесь их потерять. Удалите текущую папку с данными:
sudo rm /var/lib/postgresql/9.6/main
Затем авторизуйтесь от имени пользователя postgres и скопируйте все данные из сервера Master:
Эти настройки нужны для восстановления базы данных в случае возникновения проблем. Осталось запустить службу postgresql на другой машине:
systemctl start postgresql-9.6
Дальше осталось только протестировать как работает потоковая репликация postgresql.
ТЕСТИРОВАНИЕ РЕПЛИКАЦИИ
Чтобы посмотреть как работает репликация вы можете проверить состояния потока репликации, а также просто проверить передаются ли данные от Master на Salve. Сначала посмотрим параметры соединения:
su - postgres
psql -c "select application_name, state, sync_priority, sync_state from pg_stat_replication;" psql -x -c "select * from pg_stat_replication;"
Затем авторизуйтесь на сервере Master и войдите в консоль управления:
sudo su postgres psql
Создайте новую таблицу replica_test и вставьте в нее некоторые данные:
CREATE TABLE replica_test (test varchar(100)); INSERT INTO replica_test VALUES ('kovalets.net'); INSERT INTO replica_test VALUES ('This is from Master');
Затем перейдите на сервер Salve и проверьте действительно есть ли там эта табилца:
su - postgres
select * from replica_test;
Дальше вы можете попытаться выполнить запись на сервере Salve:
INSERT INTO replica_test VALUES ('this is SLAVE');
Но получите ошибку, так как из этого сервера можно только читать данные.
ВЫВОДЫ
В этой статье мы рассмотрели как работает репликация PostgreSQL типа Master — Salve. Как видите, все это немного сложнее, чем репликация MySQL, но тоже можно быстро разобраться и настроить. Если у вас остались вопросы, спрашивайте в комментариях!
Ошибка 400 Request Header Or Cookie Too Large в веб-сервере Nginx встречается достаточно редко. Данная ошибка означает, что отправленный запрос к веб-серверу слишком большой и был отклонен. Это может происходить по разным причинам.
Например, такое бывает, когда идет переход к веб-сайту из поисковой системы, и какой-то заголовок оказался слишком длинным. В этом случае Nginx «не ожидал» такого большого объёма в заголовке и сбросил соединение. В этой статье будет рассмотрено описание данной ошибки и как ее можно исправить. Читать далее Ошибка request header or cookie too large Nginx→
Grub - это универсальный загрузчик, который используется для загрузки операционной системы Linux и других ОС, в случае, если на компьютере установлен Linux. Но когда вы выполняете какие-либо действия с разделами на диске, например, восстанавливаете их с помощью Clonezilla, изменяете размер или что-то другое, что Grub может быть поврежден.
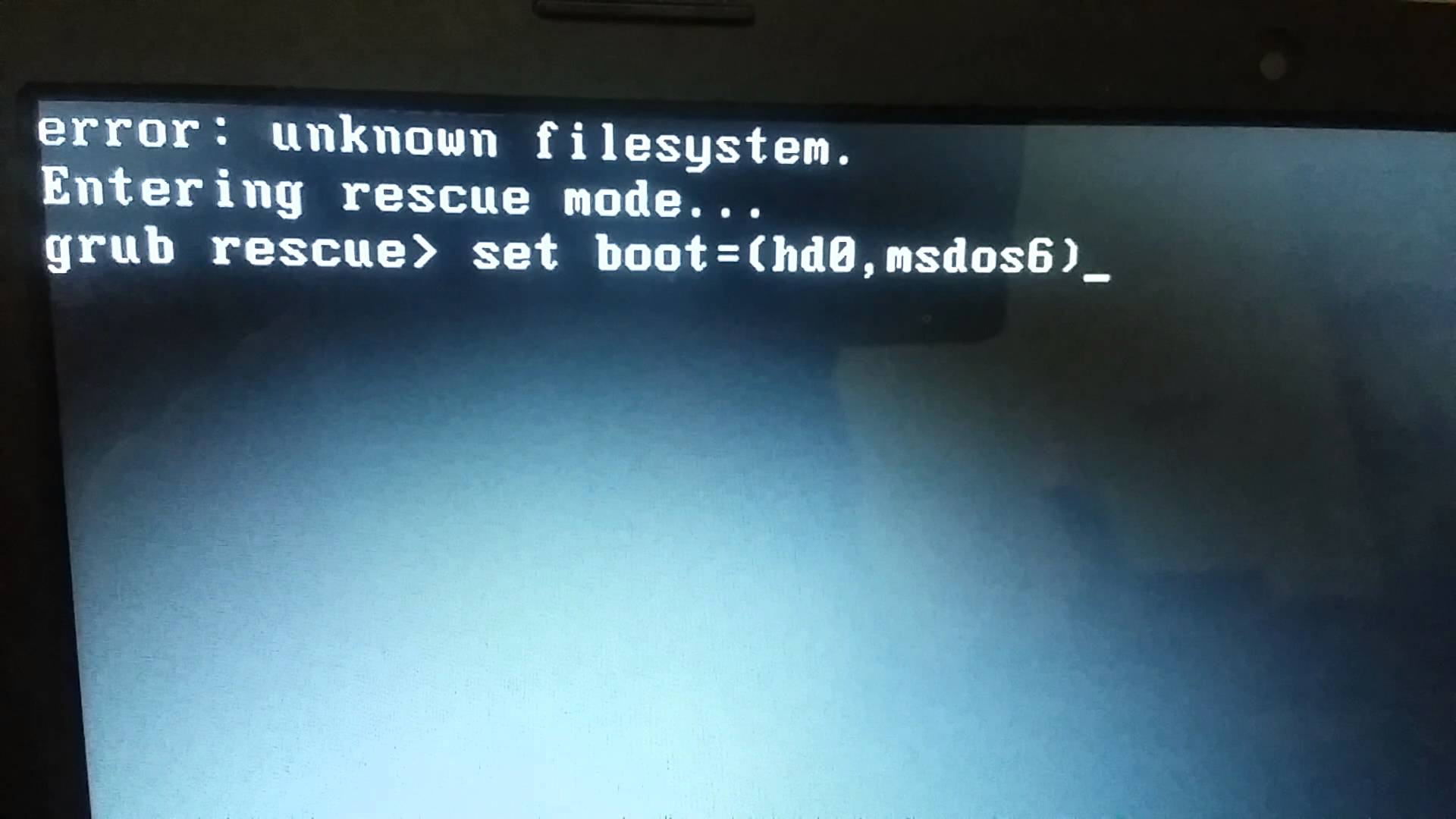
Часто такие повреждения приводят к ошибке grub rescue unknown filesystem. Тогда перед вами не появляется меню, а только сообщение про ошибку и консоль восстановления для ввода команд. В этой небольшой статье мы рассмотрим как исправить эту ошибку.
Ошибка grub rescue unknown filesystem
Ошибка grub rescue unknown filesystem может возникать по разным причинам вот самые распространенные причины:
Вы восстанавливали диск из Clonezilla и были изменены метрики раздела /boot;
Раздел /boot был отформатирован и больше не существует;
Дело в том, что Grub устанавливается в два места. Первое - место в таблице разделов MBR. Там очень мало места, около 512 байт, а следовательно, весь загрузчик туда поместиться не может. Поэтому Grub имеет модульную структуру и все основные модули, конфигурационные файлы и ресурсы располагаются на обычном разделе, который монтируется после загрузки в /boot. Причем программа в MBR помнит где находится раздел /boot, но если с этим разделом что-то произойдет и программа не сможет загрузить привычные модули, то выдаст ошибку unknown filesystem. Если раздела больше нет, то вам останется только брать LiveCD диск и переустанавливать загрузчик, если же раздел просто немного изменен, то еще можно все исправить.
Как исправить Grub unknown error
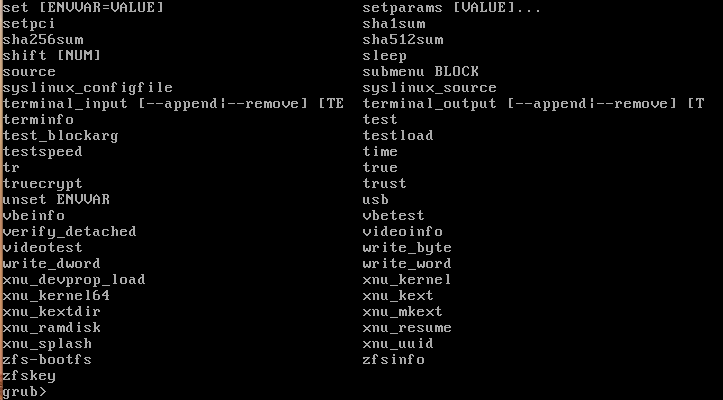
У вас есть простейший терминал с самой простой командной оболочкой. Чтобы знать какие команды можно там вводить наберите:
help
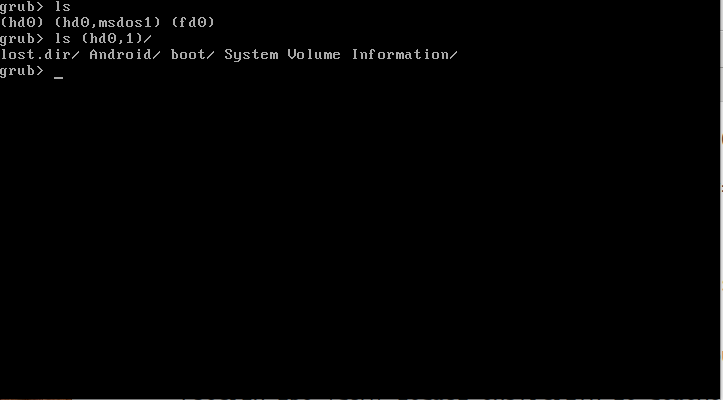
Дальше нам нужно посмотреть список доступных разделов, для этого используется команда ls, как в bash:
ls
Без модулей grub поддерживает только ту файловую систему, которая была на /boot. Вы можете попытаться просмотреть содержимое каждого раздела чтобы определить где находятся файлы модулей. Например:
ls (hd0,1)/
Если вы увидели папку boot, значит это наш раздел. Дальше устанавливаем этот раздел значением переменной root с помощью команды set:
set root=(hd0,1) set prefix=(hd0,1)/boot/grub
Загружаем и запускаем модуль normal, который должен загрузить все, что нам необходимо:
insmod normal normal
Если раздел /boot не был поврежден, то загрузчик нормально определит все файлы, а потом запустит привычное для вас меню. Конечно, после того, как система загрузится, вам будет необходимо восстановить загрузчик Grub чтобы не вводить эти команды при каждой загрузке системы.
Выводы
В этой статье мы рассмотрели почему возникает ошибка error unknown filesystem grub rescue и что делать grub rescue, когда вы видите это сообщение. Да, во многих случаях у вас уже не получится загрузить систему без LiveCD диска. Но иногда все можно спасти. Надеюсь, эта информация была полезной для вас.
В наши дни база данных MySQL используется уже практически везде, где только можно. Невозможно представить сайта, который бы работал без MySQL. Конечно, есть некоторые исключения, но основную часть рынка занимает именно эта система баз данных. И самая популярная из реализаций — MariaDB. Когда проект небольшой, для его работы достаточно одного сервера, на котором расположены все службы: веб-сервер, сервер баз данных и почтовый сервер. Но когда проект становится более большим может понадобится выделить для каждой службы отдельный сервер или даже разделить одну службу на несколько серверов, например, MySQL.
Для того чтобы поддерживать синхронное состояние баз данных на всех серверах одновременно нужно использовать репликацию. В этой статье мы рассмотрим как настраивается репликация MySQL с помощью MariaDB Galera Cluster. Читать далее Репликация MySQL→
По умолчанию в редакторе LibreOffice страница выглядит точно так же, как и обычный лист бумаги А4 и имеет портретную ориентацию. Это необходимо потому что для большинства офисных документов, рефератов, курсовых и дипломных работ по умолчанию принята такая ориентация.
Но есть ряд документов, которые нужно размещать в альбомном формате, например, широкие таблицы или какие-либо схемы. В Microsoft Office все это делается очень просто, но Libre немного отличается. В этой статье мы рассмотрим как в LibreOffice сделать альбомную страницу разными способами.
Установка загрузчика на флешку может понадобиться по нескольким причинам, например, вы хотите установить дистрибутив Linux на внешний носитель или же вам нужен еще один способ загрузить компьютер, когда основной загрузчик был затерт и система не загружается. Одним словом, может быть множество причин.
Мы уже рассматривали как установить Grub на флешку в статье про создание мультизагрузочной флешки из нескольких систем, а теперь поговорим об этом более детально. Читать далее Установка Grub на флешку→
Когда вы делаете различные рефераты, курсовые проекты, дипломные, статьи или просто большие документы на несколько страниц в текстовом процессоре LibreOffice, то вам нужно проставить нумерацию страниц чтобы после печати страницы не перепутались между собой. Для серьезных документов, нумерация страниц LibreOffice вообще является обязательным правилом.
В этой статье мы рассмотрим как пронумеровать страницы в LibreOffice, а также какое размещение номеров следует использовать в определенных ситуациях.