Существует достаточное количество оболочек, например - sh, zsh, ksh и другие. Но мы остановимся на Bash, ведь это самая популярная оболочка среди Linux. Теперь даже Microsoft добавила поддержку Bash.
Эта статья предназначена для тех кто хоть немного знаком с языком сценариев Bash. Давайте рассмотрим некоторые примеры Bash скриптов, которые могут быть полезными в вашей повседневной работе. Читать далее Примеры Bash скриптов→
Часто возникает необходимость, чтобы скрипт командного интерпретатора Bash выводил результат своей работы. По умолчанию он отображает стандартный поток данных — окно терминала. Это удобно для обработки результатов небольшого объёма или, чтобы сразу увидеть необходимые данные.
В интерпретаторе можно делать вывод в файл Bash. Применяется это для отложенного анализа или сохранения массивного результата работы сценария. Чтобы сделать это, используется перенаправление потока вывода с помощью дескрипторов.
Стандартные дескрипторы вывода
В системе GNU/Linux каждый объект является файлом. Это правило работает также для процессов ввода/вывода. Каждый файловый объект в системе обозначается дескриптором файла — неотрицательным числом, однозначно определяющим открытые в сеансе файлы. Один процесс может открыть до девяти дескрипторов.
В командном интерпретаторе Bash первые три дескриптора зарезервированы для специального назначения:
Дескриптор
Сокращение
Название
0
STDIN
Стандартный ввод
1
STDOUT
Стандартный вывод
2
STDERR
Стандартный вывод ошибок
Их предназначение — обработка ввода/вывода в сценариях. По умолчанию стандартным потоком ввода является клавиатура, а вывода — терминал. Рассмотрим подробно последний.
Вывод в файл Bash
1. Перенаправление стандартного потока вывода
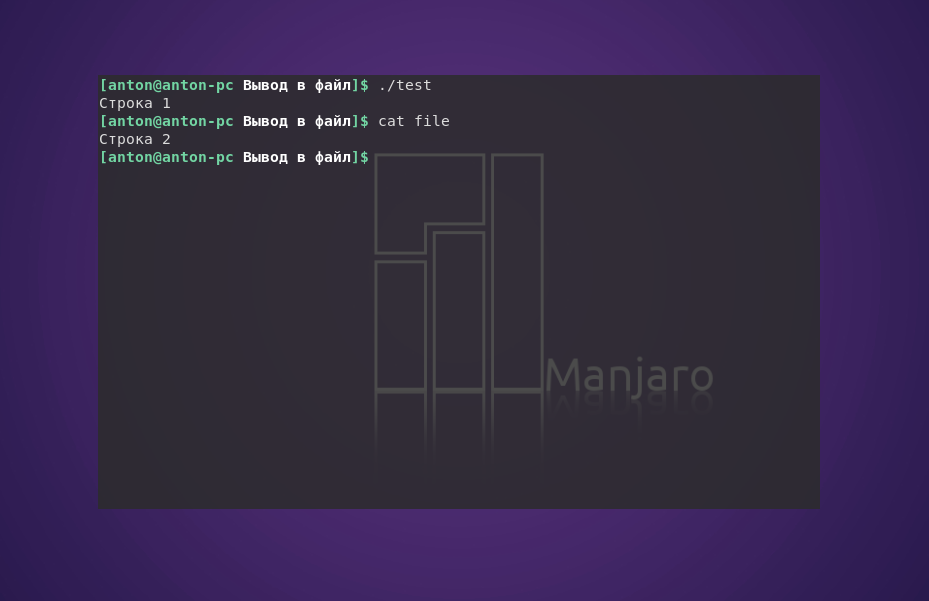
Для того, чтобы перенаправить поток вывода с терминала в файл, используется знак «больше» (>).
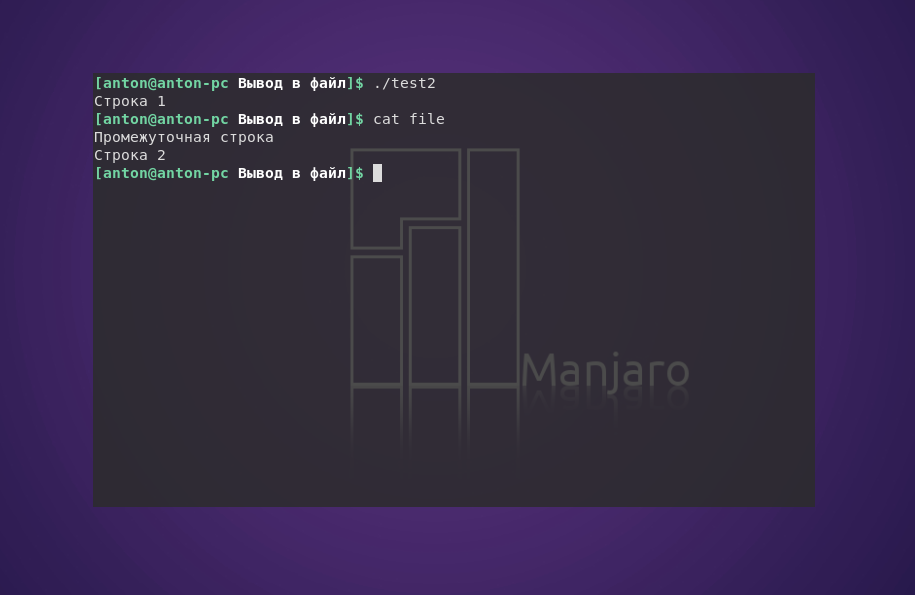
Здесь "Промежуточная строка" перезаписала предыдущее содержание file, а "Строка 2" дописалась в его конец.
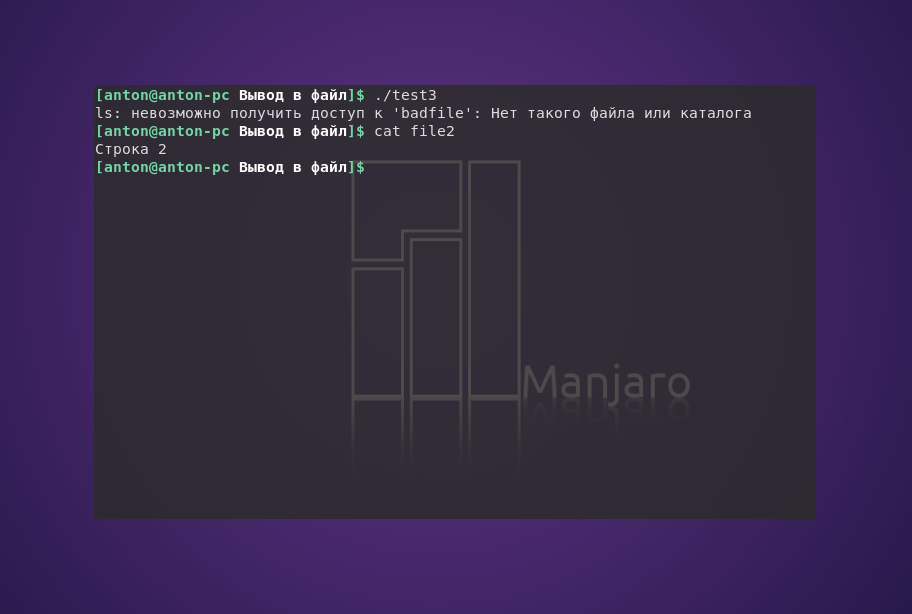
Если во время использования перенаправления вывода интерпретатор обнаружит ошибку, то он не запишет сообщение о ней в файл.
#!/bin/bash
ls badfile > file2
echo "Строка 2" >> file2
В данном случае ошибка была в том, что команда ls не смогла найти файл badfile, о чём Bash и сообщил. Но вывелось сообщение в терминал, а не записалось в файл. Всё потому, что использование перенаправления потоков указывает интерпретатору отделять мух от котлет ошибки от основной информации.
Это особенно полезно при выполнении сценариев в фоновом режиме, где приходится предусматривать вывод сообщений в журнал. Но так как ошибки в него писаться не будут, нужно отдельно перенаправлять поток ошибок для того, чтобы выполнить их вывод в файл Linux.
2. Перенаправление потока ошибок
В командном интерпретаторе для обработки сообщений об ошибках предназначен дескриптор STDERR, который работает с ошибками, сформированными как от работы интерпретатора, так и самим скриптом.
По умолчанию STDERR указывает в то же место, что и STDOUT, хотя для них и предназначены разные дескрипторы. Но, как было показано в примере, использование перенаправления заставляет Bash разделить эти потоки.
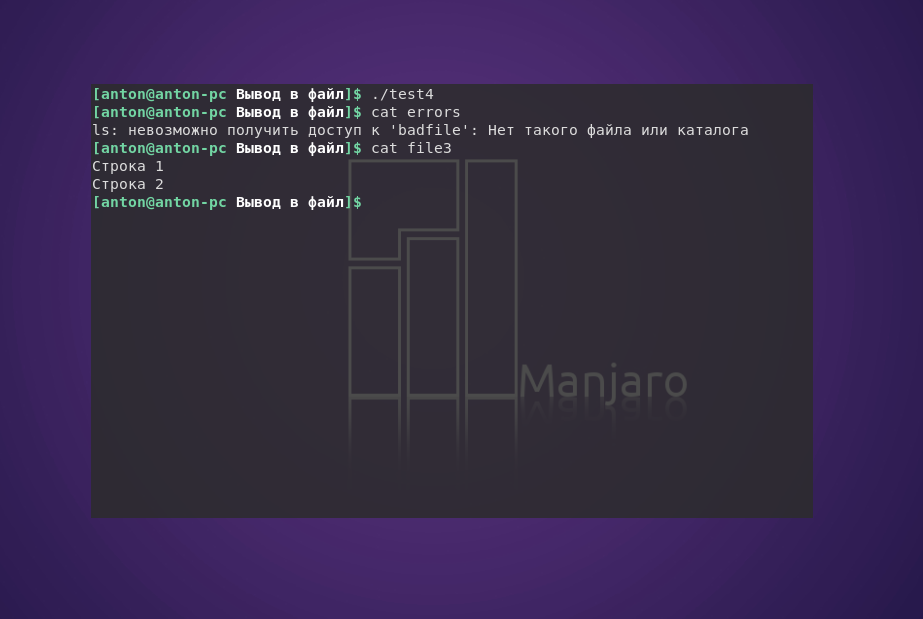
Чтобы выполнить перенаправление вывода в файл Linux для ошибок, следует перед знаком«больше» указать дескриптор 2.
В результате работы скрипта создан файл errors, в который записана ошибка выполнения команды ls, а в file3 записаны предназначенные строки. Таким образом, выполнение сценария не сопровождается выводом информации в терминал.
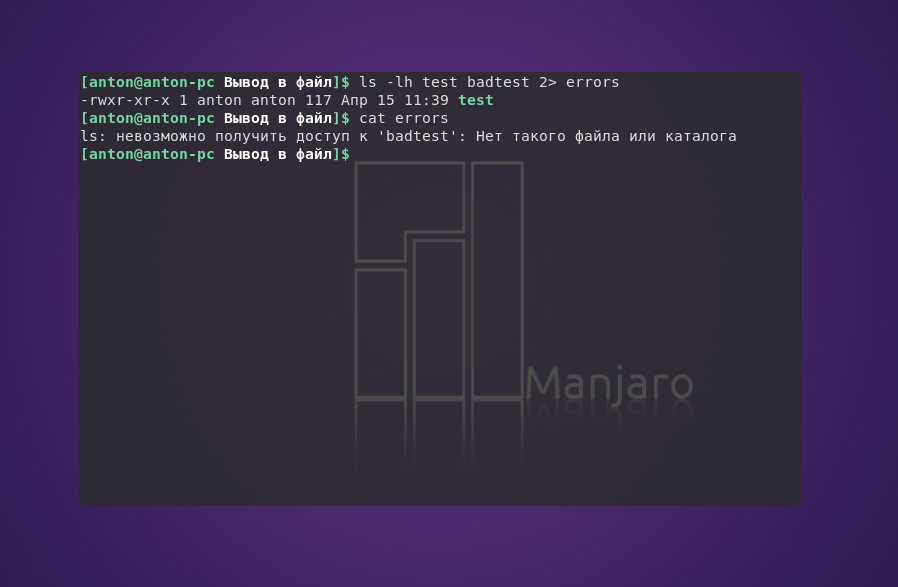
Пример того, как одна команда возвращает и положительный результат, и ошибку:
ls -lh test badtest 2> errors
Команда ls попыталась показать наличие файлов test и badtest. Первый присутствовал в текущем каталоге, а второй — нет. Но сообщение об ошибке было записано в отдельный файл.
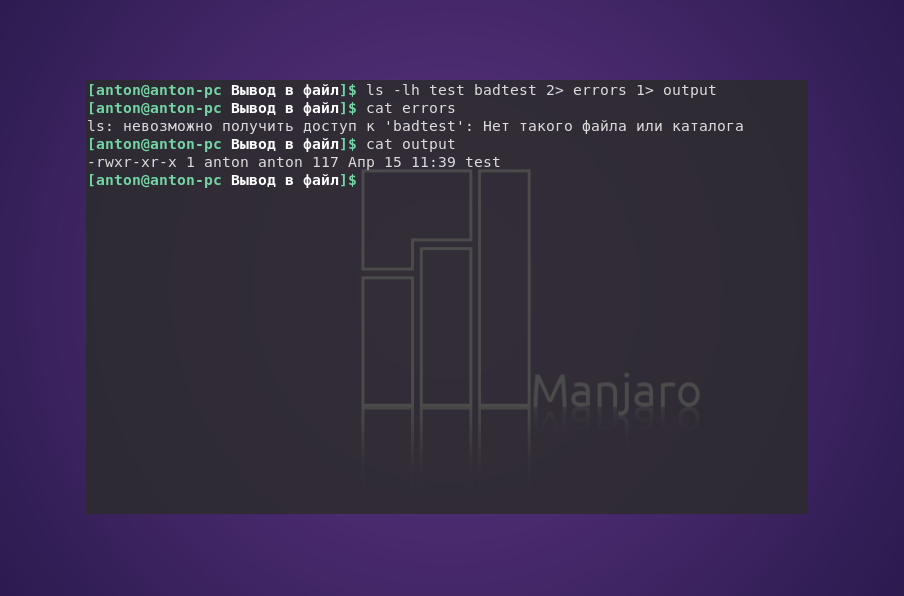
Если возникает необходимость выполнить вывод команды в файл Linux, включая её стандартный поток вывода и ошибки, стоит использовать два символа перенаправления, перед которыми стоит указывать необходимый дескриптор.
ls -lh test test2 badtest 2> errors 1> output
Результат успешного выполнения записан в файл output, а сообщение об ошибке — в errors.
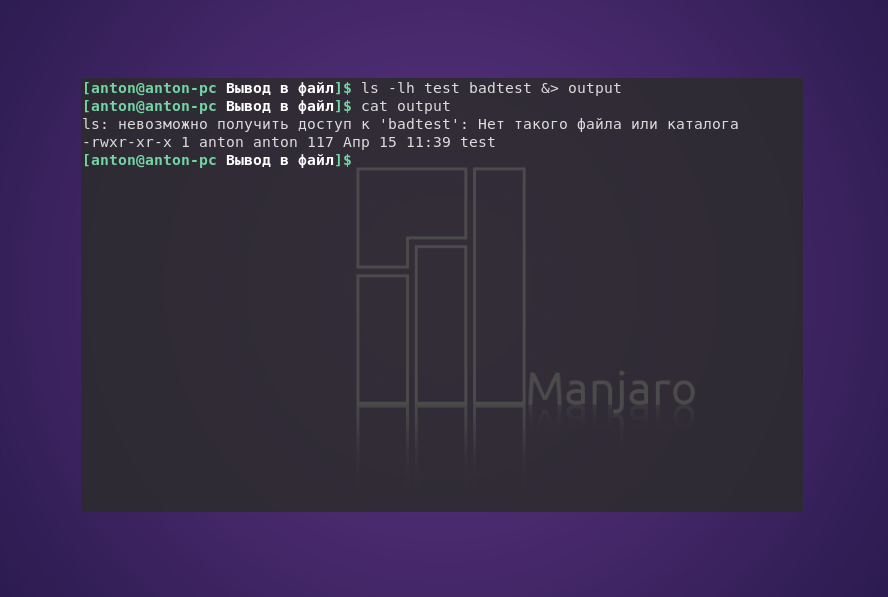
По желанию можно выводить и ошибки, и обычные данные в один файл, используя &>.
ls -lh test badtest &> output
Обратите внимание, что Bash присваивает сообщениям об ошибке более высокий приоритет по сравнению с данными, поэтому в случае общего перенаправления ошибки всегда будут располагаться в начале.
Временные перенаправления в скриптах
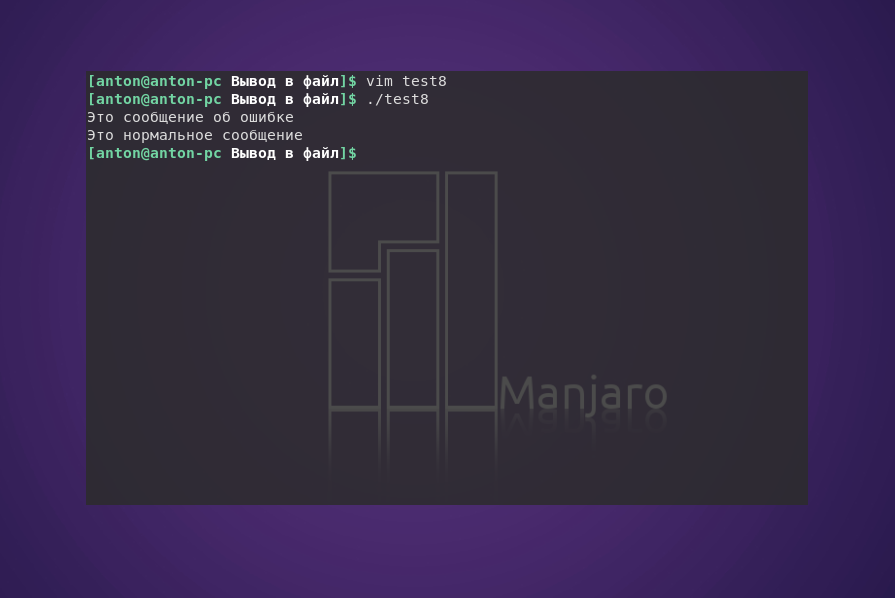
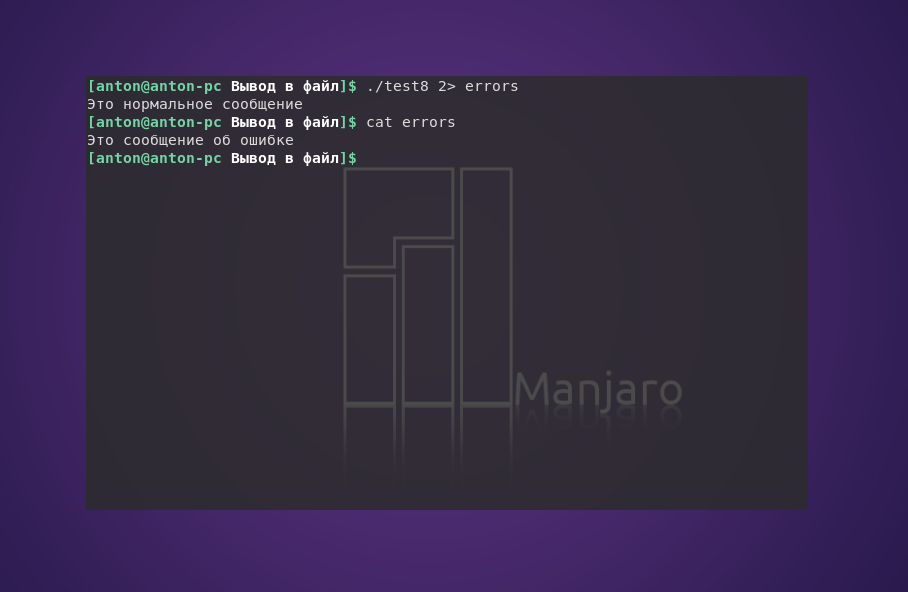
Если есть необходимость в преднамеренном формировании ошибок в сценарии, можно каждую отдельную строку вывода перенаправлять в STDERR. Для этого достаточно воспользоваться символом перенаправления вывода, после которого нужно использовать & и номер дескриптора, чтобы перенаправить вывод в STDERR.
#!/bin/bash
echo "Это сообщение об ошибке" >&2
echo "Это нормальное сообщение"
При выполнении программы обычно нельзя будет обнаружить отличия:
Вспомним, что GNU/Linux по умолчанию направляет вывод STDERR в STDOUT. Но если при выполнении скрипта будет перенаправлен поток ошибок, то Bash, как и полагается, разделит вывод.
Этот метод хорошо подходит для создания собственных сообщений об ошибках в сценариях.
Постоянные перенаправления в скриптах
Если в сценарии необходимо перенаправить вывод в файл Linux для большого объёма данных, то указание способа вывода в каждой инструкции echo будет неудобным и трудоёмким занятием. Вместо этого можно указать, что в ходе выполнения данного скрипта должно осуществляться перенаправление конкретного дескриптора с помощью команды exec:
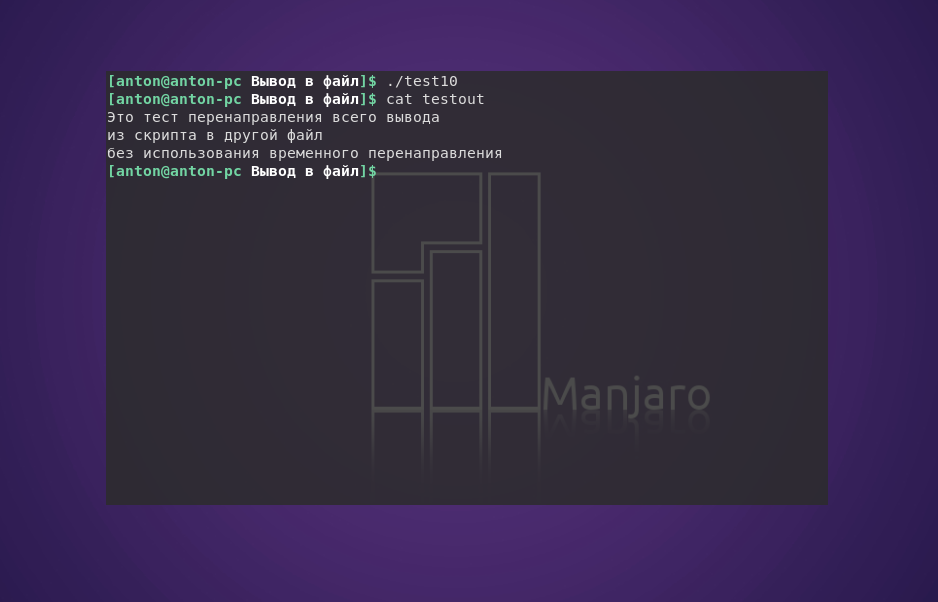
#!/bin/bash
exec 1> testout
echo "Это тест перенаправления всего вывода"
echo "из скрипта в другой файл"
echo "без использования временного перенаправления"
Вызов команды exec запускает новый командный интерпретатор и перенаправляет стандартный вывод в файл testout.
Также существует возможность перенаправлять вывод (в том числе и ошибок) в произвольном участке сценария:
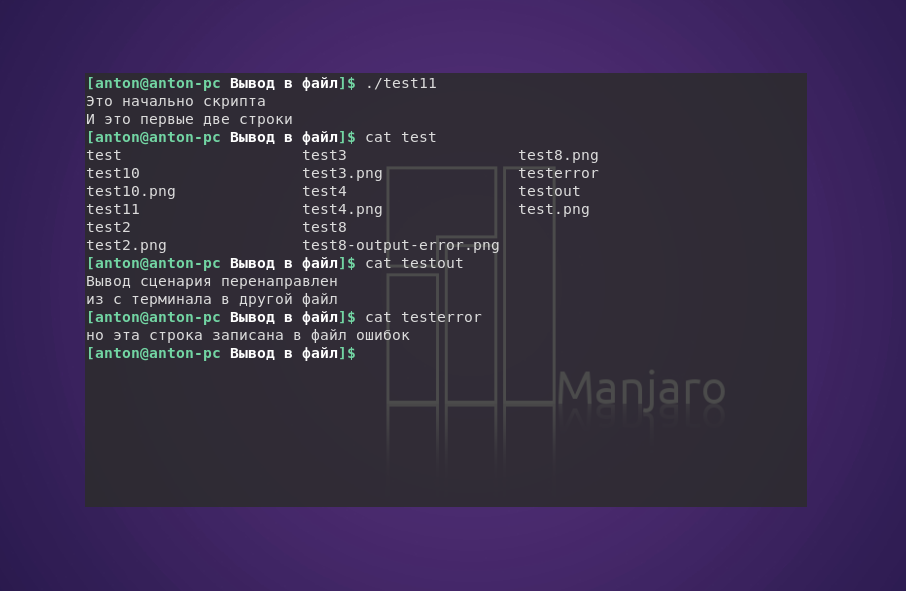
#!/bin/bash
exec 2> testerror
echo "Это начально скрипта"
echo "И это первые две строки"
exec 1> testout
echo "Вывод сценария перенаправлен"
echo "из с терминала в другой файл"
echo "но эта строка записана в файл ошибок" >&2
Такой метод часто применяется при необходимости перенаправить лишь часть вывода скрипта в другое место, например в журнал ошибок.
Выводы
Перенаправление в скриптах Bash, чтобы выполнить вывод в файл Bash, является хорошим средством ведения различных журналов, особенно в фоновом режиме.
Использование временного и постоянного перенаправлений в сценариях позволяет создавать собственные сообщения об ошибках для записи в отличное от STDOUT место.
В операционных системах GNU/Linux любые объекты системы являются файлами. И проверка существования файла bash - наиболее мощный и широко применяемый инструмент для определения и сравнения в командном интерпретаторе.
В рамках интерпретатора Bash, как и в повседневном понимании людей, все объекты файловой системы являются, тем, чем они есть, каталогами, текстовыми документами и т.д. В этой статье будет рассмотрена проверка наличия файла Bash, а также его проверка на пустоту, и для этого используется команда test.
Проверка существования файла Bash
Начать стоит с простого и более общего метода. Параметр -e позволяет определить, существует ли указанный объект. Не имеет значения, является объект каталогом или файлом.
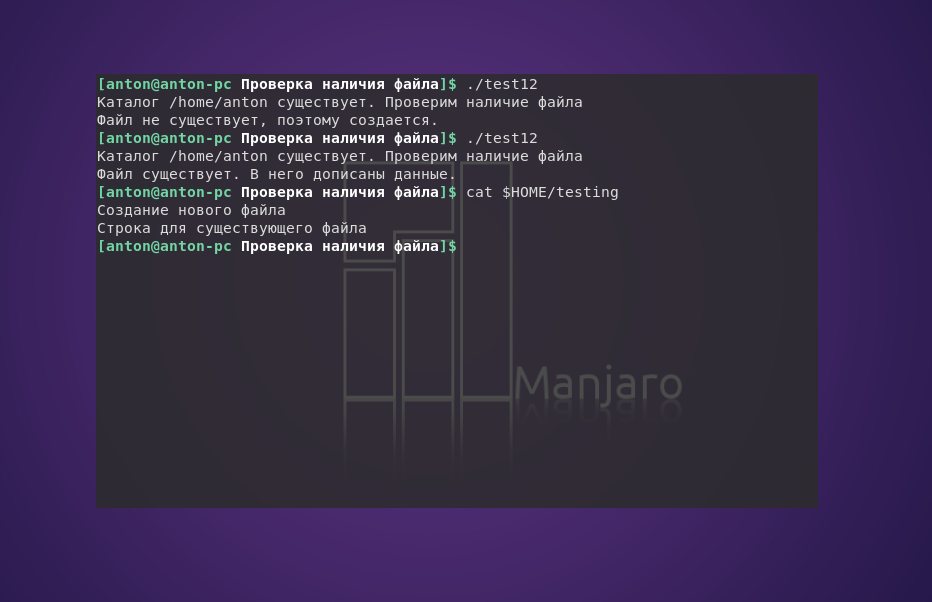
#!/bin/bash
# проверка существования каталога
if [ -e $HOME ]
then
echo "Каталог $HOME существует. Проверим наличие файла"
# проверка существования файла
if [ -e $HOME/testing ]
then
# если файл существует, добавить в него данные
echo "Строка для существующего файла" >> $HOME/testing
echo "Файл существует. В него дописаны данные."
else
# иначе — создать файл и сделать в нем новую запись
echo "Файл не существует, поэтому создается."
echo "Создание нового файла" > $HOME/testing
fi
else
echo "Простите, но у вас нет Домашнего каталога"
fi
Пример работы кода:
Вначале команда test проверяет параметром -e, существует ли Домашний каталог пользователя, название которого хранится системой в переменной $HOME. При отрицательном результате скрипт завершит работу с выводом сообщения об этом. Если такой каталог обнаружен, параметр -е продолжает проверку. На этот раз ищет в $HOME файл testing. И если он есть, то в него дописывается информация, иначе он создастся, и в него запишется новая строка данных.
Проверка наличия файла
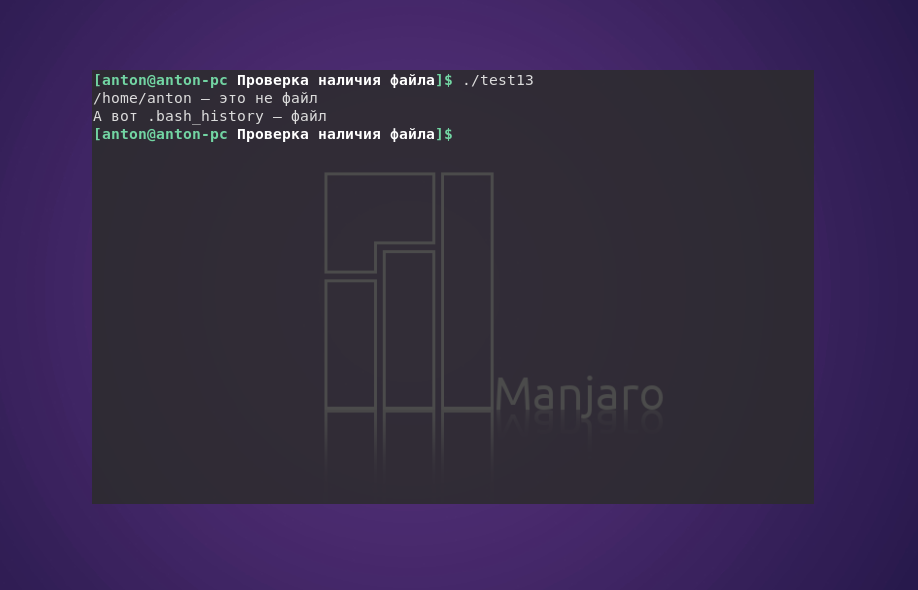
Проверка файла Bash на то, является ли данный объект файлом (то есть существует ли файл), выполняется с помощью параметра -f.
#!/bin/bash
if [ -f $HOME ]
then
echo "$HOME — это файл"
else
echo "$HOME — это не файл"
if [ -f $HOME/.bash_history ]
then
echo "А вот .bash_history — файл"
fi
fi
Пример работы кода:
В сценарии проверяется, является ли $HOME файлом. Результат проверки отрицательный, после чего проверяется настоящий файл .bash_history, что уже возвращает истину.
На заметку: на практике предпочтительнее использовать сначала проверку на наличие объекта как такового, а затем — на его конкретный тип. Так можно избежать различных ошибок или неожиданных результатов работы программы.
Проверка файла на пустоту
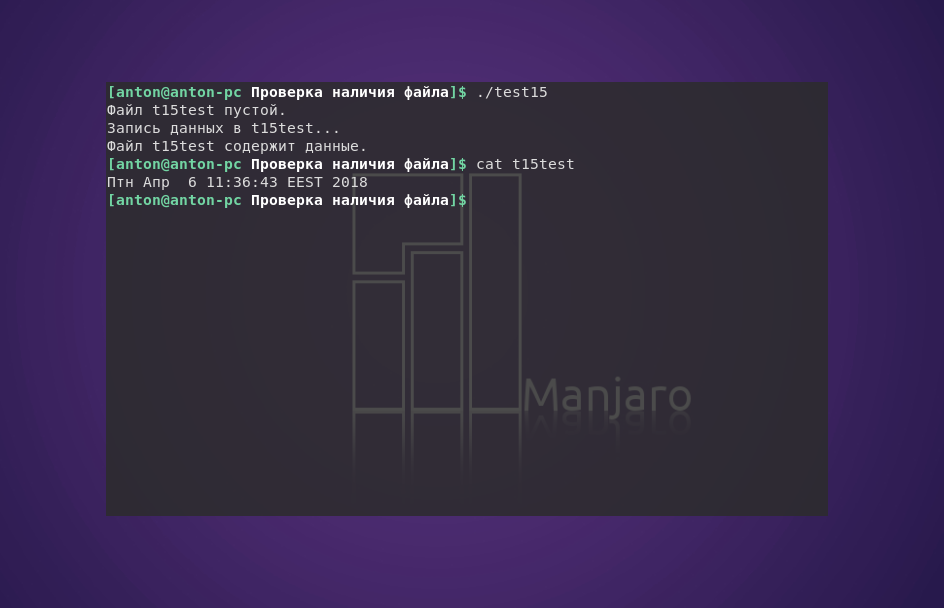
Чтобы определить, является ли файл пустым, нужно выполнить проверку с помощью параметра -s. Это особенно важно, когда файл намечен на удаление. Здесь нужно быть очень внимательным к результатам, так как успешное выполнение этого параметра указывает на наличие данных.
#!/bin/bash
file=t15test
touch $file
if [ -s $file ]
then
echo "Файл $file содержит данные."
else
echo "Файл $file пустой."
fi
echo "Запись данных в $file..."
date > $file
if [ -s $file ]
then
echo "Файл $file содержит данные."
else
echo "Файл $file все еще пустой."
fi
Результат работы программы:
В этом скрипте файл создаётся командой touch, и при первой проверке на пустоту возвращается отрицательный результат. Затем в него записываются данные в виде команды date, после чего повторная проверка файла возвращает истину.
Выводы
В статье была рассмотрена проверка существования файла bash, а также его пустоты. Обе функции дополняют друг друга, поэтому использовать их в связке - эффективный приём.
Хороший тон в написании сценариев командного интерпретатора - сначала определить тип файла и его дальнейшую роль в программе, а затем уже проверять объект на существование.
Существование сценариев, состоящих из отдельных команд, считается нормальным явлением. Но иногда возникают ситуации, когда этого становится недостаточно. Например, часто необходимо использовать данные от команды к команде, чтобы обработать информацию. С этой задачей помогают справиться переменные в скриптах.
В этой статье будут рассмотрены переменные в Bash скриптах с точки зрения области видимости, а также некоторые особенности при работе с ними.
Переменные среды Bash
Командный интерпретатор Bash поддерживает переменные среды, которые отслеживают различную системную информацию:
Имя системы;
Имя пользователя, зарегистрированного в системе;
Идентификатор пользователя (UID);
Исходный (домашний) каталог пользователя по умолчанию и т.п.
Для ознакомления с полным списком локальных переменных среды используется команда set.
set
Результат:
Значения этих переменных Bash можно использовать в сценариях, для чего необходимо указать имя переменной с предшествующим ей знаком доллара ($).
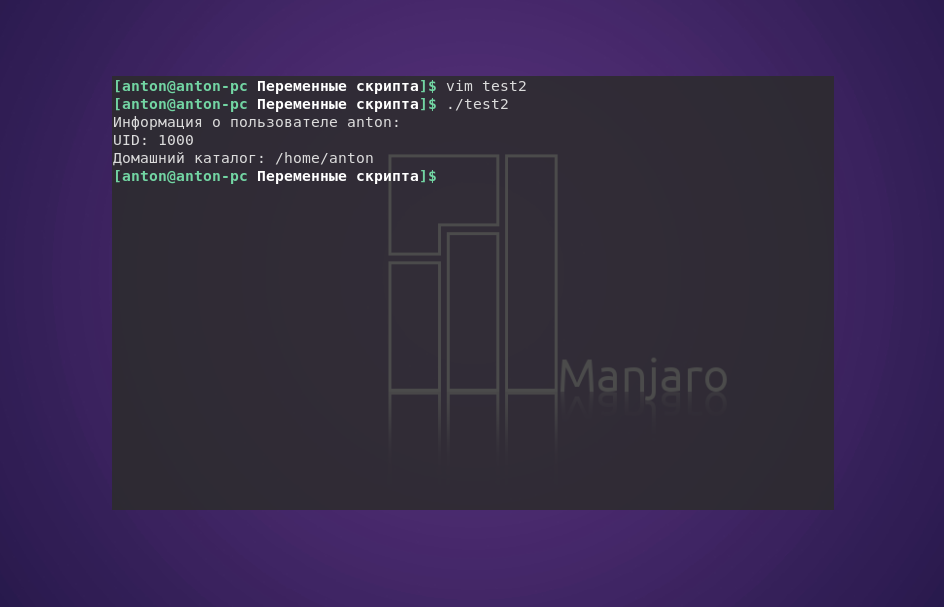
Переменные окружения Bash $USER, $UID и $HOME использовались для отображения запрашиваемой информации о текущем зарегистрированном пользователе.
Обратите внимание: переменные среды в командах echo заменяются их текущими значениями при выполнении программы. Кроме того, переменные, заключённые в кавычках, и вне их интерпретируются правильно.
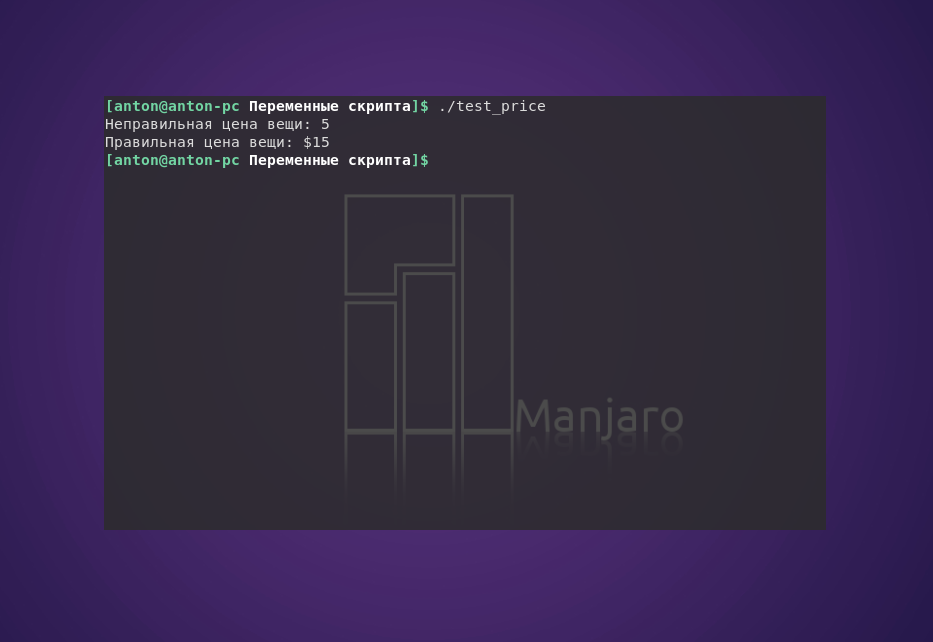
Однако в таком методе есть некоторый недостаток: при попытке отобразить какое-то денежное значение в долларовом эквиваленте необходимо добавить перед знаком доллара обратный слэш для его экранирования, чтобы интерпретатор не посчитал следующую за ним цифру именем переменной, принимающей параметр скрипта по указанному номеру.
В первой строке, где отображается неправильная цена, интерпретатор воспринял $ как знак начала переменной 1, которая считала первый параметр запущенной программы. Поскольку параметр ничего не содержал, то ничего и не было отображено вместо $1.
На заметку: частым случаем является использование фигурных скобок вокруг имени переменной после знака доллара (например ${variable}). Этот приём позволяет просто определить имя переменной, а на её функциональность это никак не влияет.
Пользовательские переменные Bash
В сценариях командного интерпретатора Bash можно не только использовать переменные среды, но также создавать и включать собственные. Задание переменных позволяет сохранять данные и использовать их во время работы скрипта, что делает его более интерактивным.
Пользовательские переменные Bash Linux могут быть названы любой текстовой строкой длиной до 20 символов, состоящей из букв, цифр и символа подчёркивания. В названии учитывается регистр букв, поэтому переменная Var1 не является переменной var1. Новички в области написания сценариев часто забывают об этой особенности, отчего и допускают трудно диагностируемые ошибки.
Присвоение значения переменной Bash выполняется с помощью знака равенства (=). Слева и справа от знака не должно быть разделяющих символов по типу пробела. Это правило также часто забывается неофитами. Вот пример присваивания значений переменным:
Ключевой особенностью интерпретатора Bash является автоматическое определение типа данных, используемого для представления значения переменных. После их определения сценарий сохраняет значения этих переменных на протяжении всего времени работы программы и уничтожает после её завершения.
На заметку: обращение к пользовательским переменным осуществляется так же, как и к системным, — с помощью знака доллара ($). Он не используется, когда переменной присваивается значение.
Выводы
Для обработки информации в сценариях командного интерпретатора используются переменные среды Bash и пользовательские переменные. Последние имеют жизнеспособность по умолчанию до тех пор, пока работает программа. При обращении к пользовательским переменным применяется знак доллара, а при записывании в них данных — нет.
Функциональность интерпретатора Bash позволяет работать не только со статистическими данными, записанными в скриптах. Иногда возникает необходимость добавить сценарию интерактивности, позволяя принимать внешние параметры скрипта для манипуляции ими в коде.
В этой статье будет рассмотрено, как принимать аргументы командной строки bash, способы его обработки, проверка опций, а также известные особенности при работе с ними.
Параметры скрипта Bash
Интерпретатор Bash присваивает специальным переменным все параметры, введённые в командной строке. В их состав включено название сценария, выполняемого интерпретатором. Такие переменные называются ещё числовыми переменными, так как в их названии содержится число:
$0 — название сценария;
$1 — первый параметр;
...
$9 — девятый параметр сценария.
Ниже приведён пример использования одного параметра скрипта Bash:
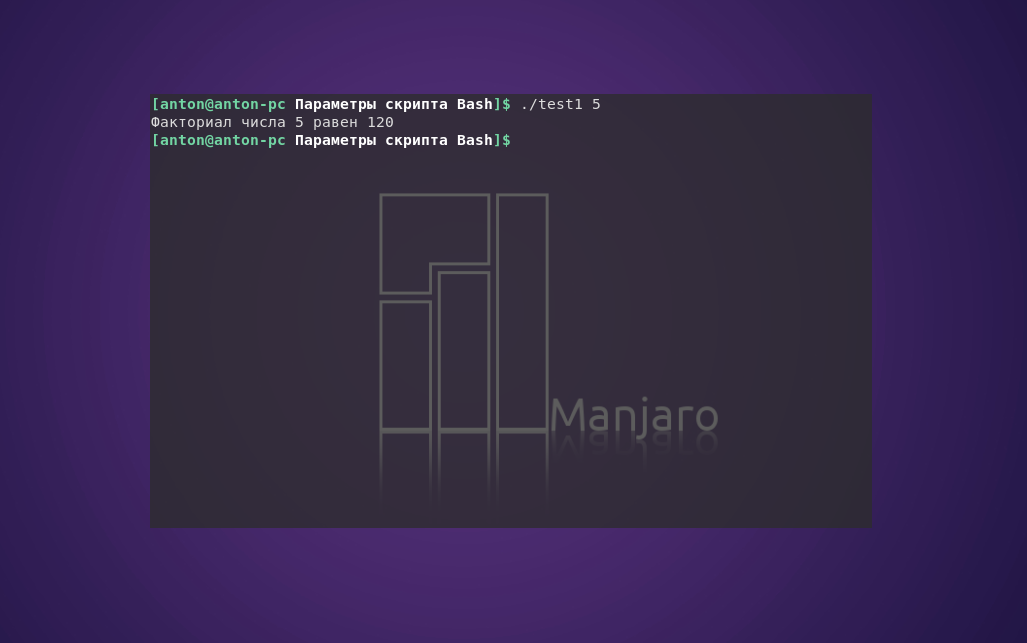
#!/bin/bash
factorial=1
for (( number = 1; number <= $1 ; number++ ))
do
factorial=$[ $factorial * $number ]
done
echo "Факториал числа $1 равен $factorial"
Результат работы кода:
Переменная $1 может использоваться в коде точно так же, как и любая другая. Скрипт автоматически присваивает ей значение из параметра командой строки — пользователю не нужно делать это вручную.
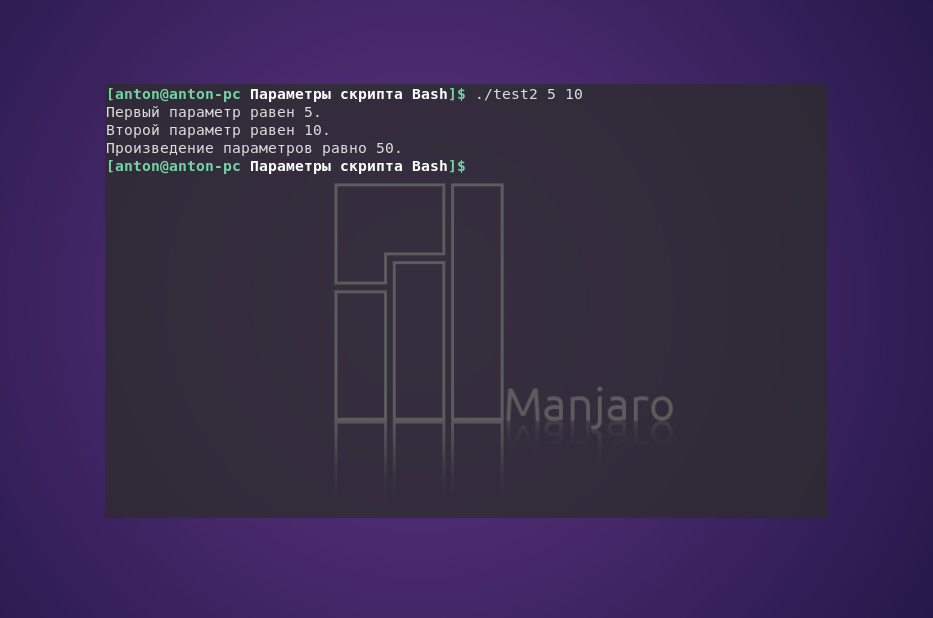
Если необходимо ввести дополнительные параметры, их следует разделить в командной строке пробелами.
Командный интерпретатор присвоил числа 5 и 10 соответствующим переменным — $1 и $2.
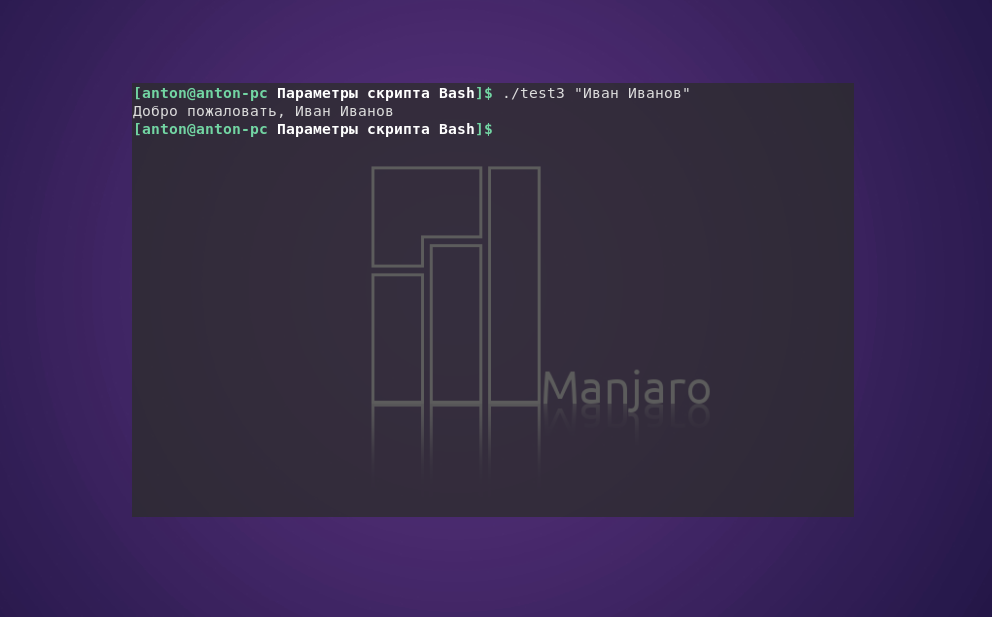
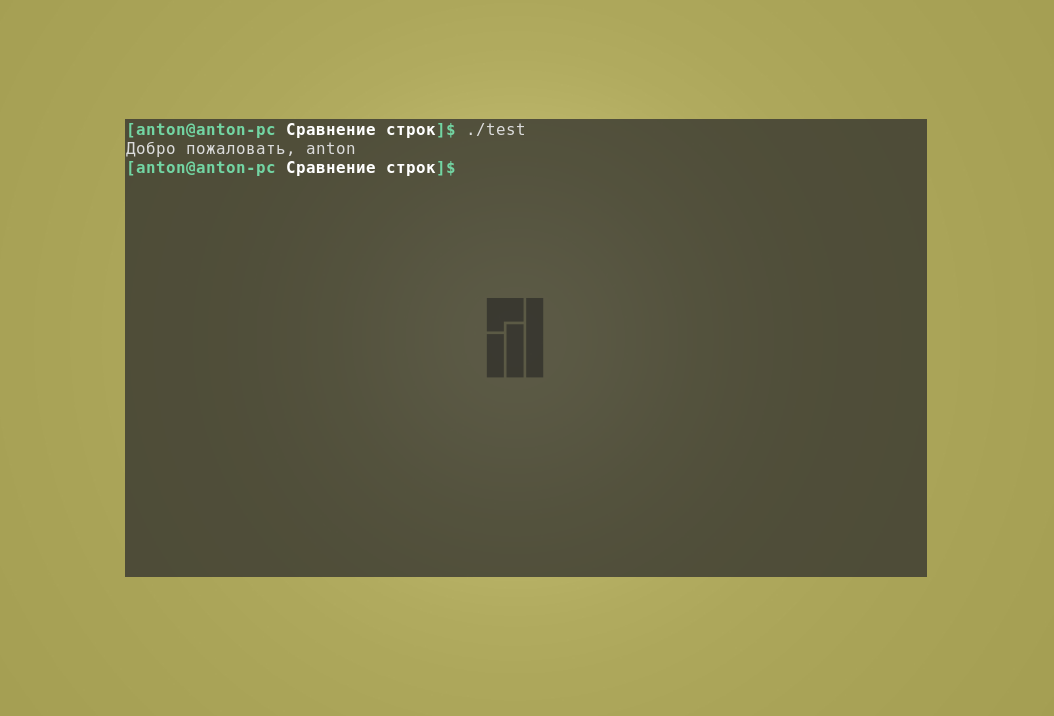
Также параметрами могут быть и текстовые строки. Однако, если есть необходимость передать параметр, содержащий пробел (например имя и фамилию), его нужно заключить в одинарные или двойные кавычки, так как по умолчанию пробел служит разделителем параметров командной строки:
#!/bin/bash
echo "Добро пожаловать, $1"
Пример работы кода:
На заметку: кавычки, которые используются при передаче параметров, обозначают начало и конец данных и не являются их частью.
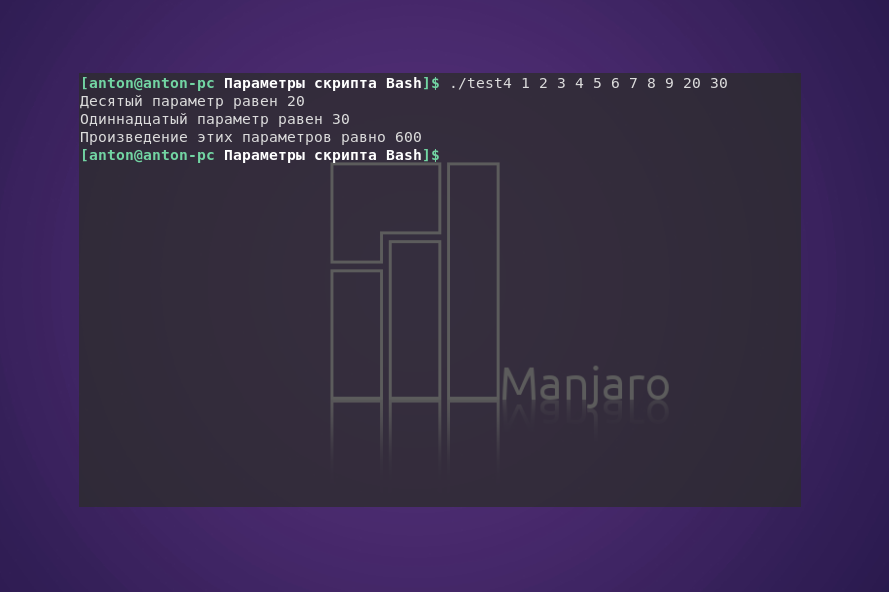
Если необходимо использовать больше 9 параметров для скрипта, то названия переменных немного изменятся. Начиная с десятой переменной, число, стоящее после знака $, необходимо заключать в квадратные скобки (без внутренних пробелов):
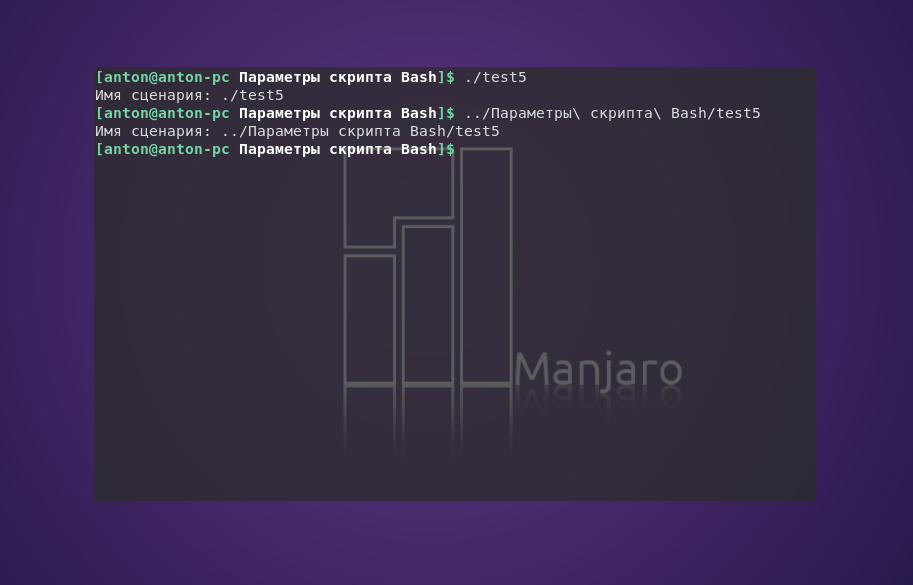
Как уже упоминалось, имя сценария является самым первым параметром скрипта. Чтобы определить название программы, используется переменная $0. Такая необходимость возникает, например, при написании скрипта, который может выполнять несколько функций. Однако при этом возникает одна особенность, которую нужно учитывать на практике:
#!/bin/bash
echo "Имя сценария: $0"
Пример работы кода:
Как видно, если строкой, фактически переданной в переменную $0, является весь путь к сценарию, то на вывод будет идти весь путь, а не только название программы.
Если нужен скрипт, выполняющий различные функции с учётом того, под каким именем он был вызван из командной строки, придётся проделать дополнительную работу: удалить сведения о пути, который использовался для его вызова.
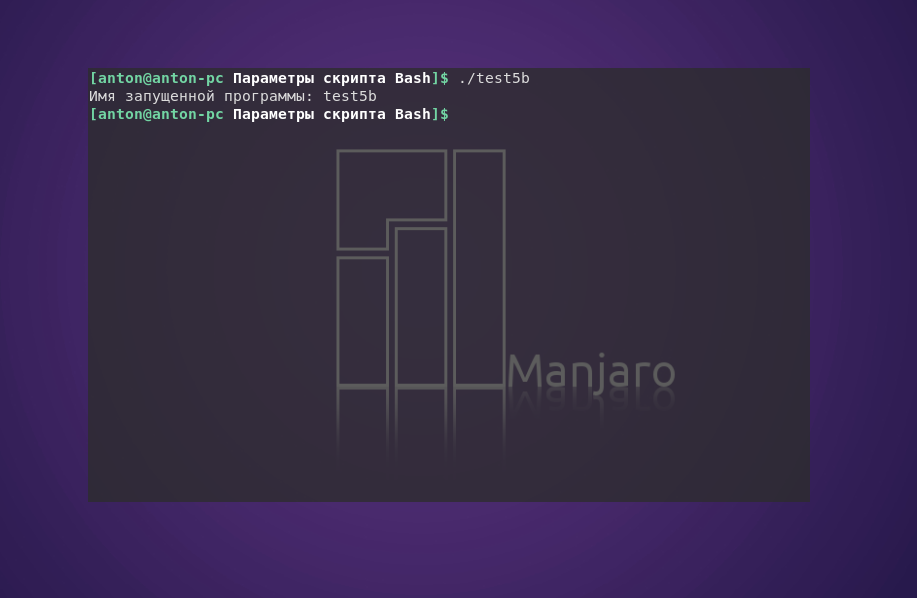
Для этого специально предусмотрена небольшая команда. Команда basename возвращает только название скрипта без абсолютного или относительного пути к нему:
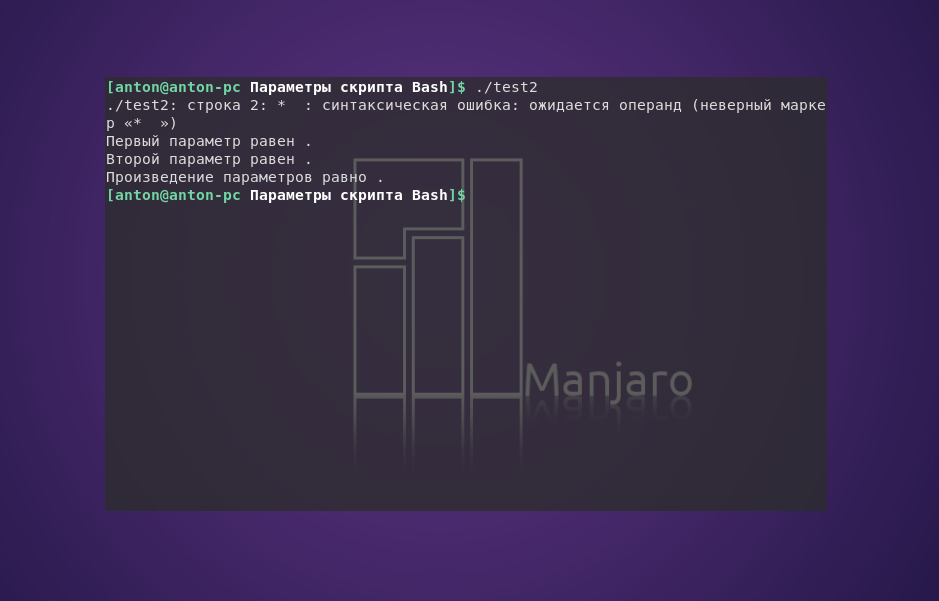
Передача параметров Bash вынуждает соблюдать осторожность. Если сценарий написан с применением параметров, но запускается без них, то возникнут проблемы в работе программы.
Если попробовать запустить написанный ранее скрипт test2 без аргументов, то перед выводом команд echo будет отображена ошибка:
Чтобы предотвращать подобные ситуации, необходимо действовать на упреждение — проверять аргументы скрипта на наличие значений. Это настоятельная рекомендация при использовании параметров в командной строке, и только после ревизии стоит пускать их в дело:
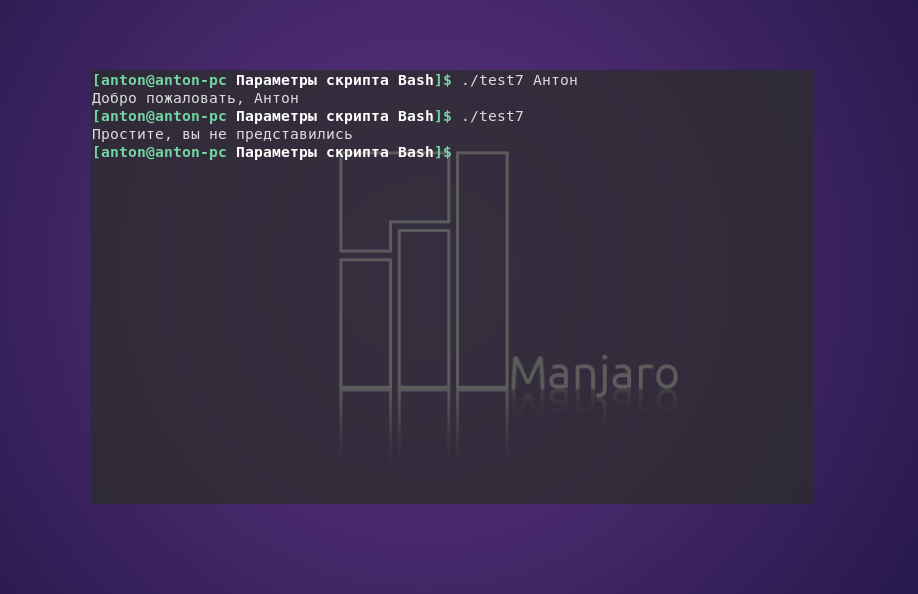
#!/bin/bash
if [ -n "$1" ]
then
echo "Добро пожаловать, $1"
else
echo "Простите, вы не представились"
fi
Пример работы кода:
В данном случае использовалась опция -n из предыдущей статьи о сравнении строк в Bashдля проверки на наличие значения в переменной, которая считала параметр.
Обработка неизветсного числа параметров
Для начала рассмотрим один из часто используемых инструментов при работе с параметрами Bash — команду shift. Её прямое назначение заключается в сдвиге параметров на одну позицию влево. Таким образом, значение из переменной $3 переместится в $2, а из $2 — в $1. Но из $1 значение просто отбросится и не сместится в $0, так как там неизменно хранится название запущенной программы.
Эта команда является эффективным способом обработки всех параметров, переданных сценарию, особенно, когда нельзя заранее узнать их количество. Достаточно лишь обработать $1, сделать сдвиг и повторить процедуру.
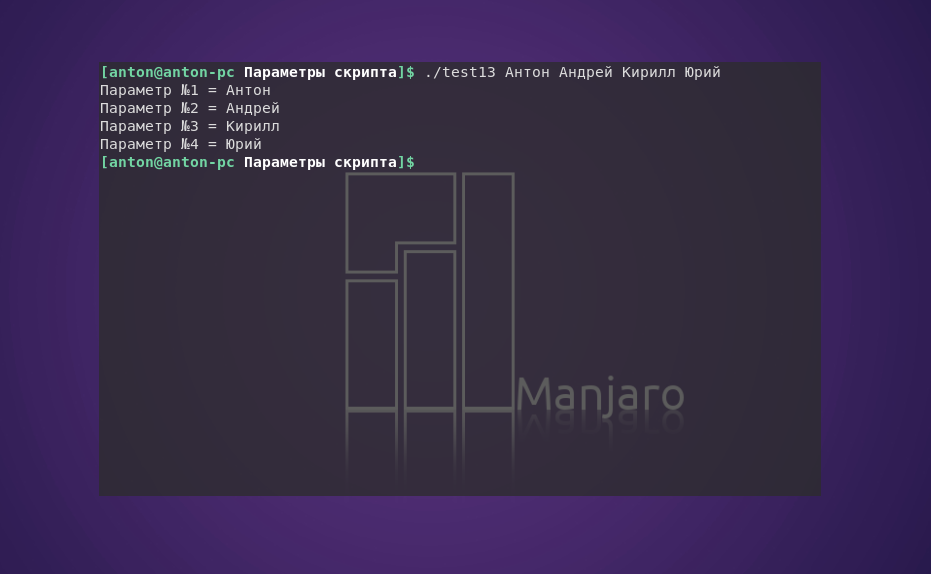
#!/bin/bash
count=1
while [ -n "$1" ]
do
echo "Параметр №$count = $1"
count=$[ $count + 1 ]
shift
done
Пример работы кода:
Этот скрипт выполняет цикл while, в условии которого указана проверка первого параметра на длину. И если она равна нулю, цикл прерывает свою работу. При положительном результате проверки команда shift сдвигает все параметры влево на одну позицию.
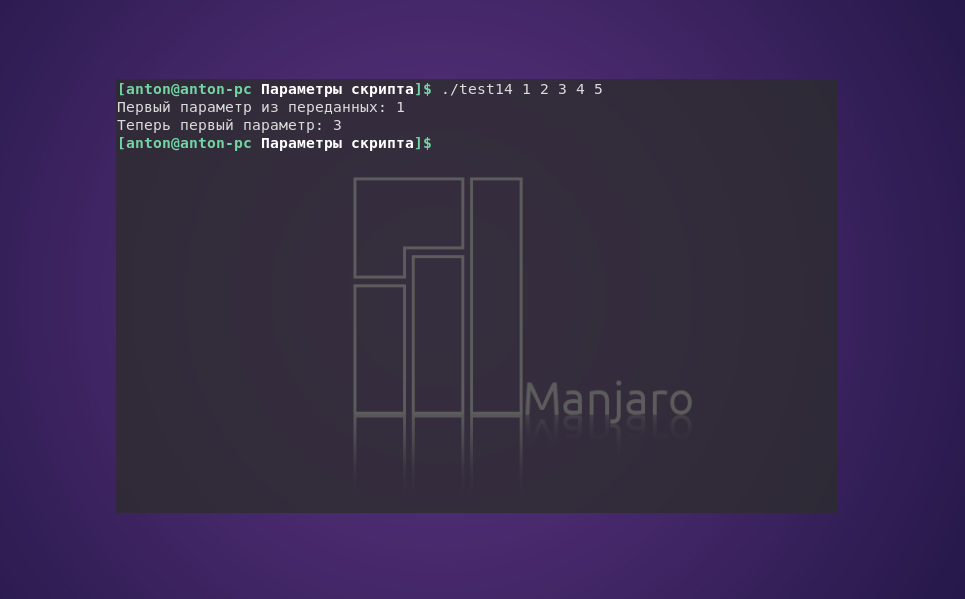
Ещё один вариант использование shift — смещать на несколько позиций. Для этого достаточно через пробел указать количество, на которое будет смещён ряд параметров скрипта.
#!/bin/bash
echo "Первый параметр из переданных: $1"
shift 2
echo "Теперь первый параметр: $1"
Пример работы скрипта:
На заметку: при использовании shift нужно быть осторожным, ведь сдвинутые за пределы $1 параметры не восстанавливаются в период работы программы.
Обработка опций в Bash
Помимо параметров скрипт может принимать опции — значения, состоящие из одной буквы, перед которыми пишется дефис. Рассмотрим 3 метода работы с ними в скриптах. Сперва кажется, что при работе с опциями не должно возникать каких-либо сложностей. Они должны быть заданы после имени запускаемой программы, как и параметры. При необходимости можно сделать обработку опций командной строки по такому же принципу, как это делается с параметрами.
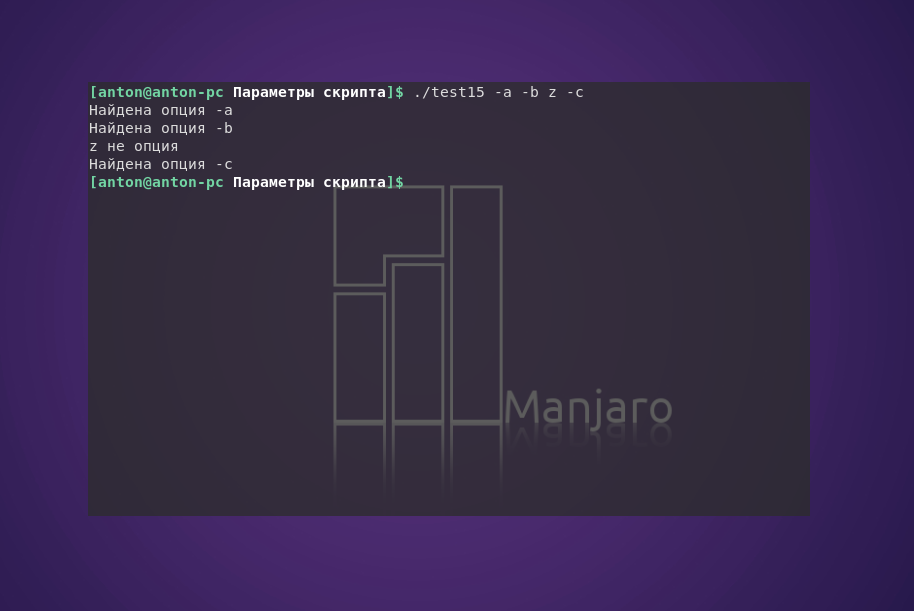
По примеру выше можно применять shift для обработки простых опций. С помощью инструкции case можно определять, являются ли аргументы Bash опциями:
#!/bin/bash
while [ -n "$1" ]
do
case "$1" in
-a | -b | -c) echo "Найдена опция $1" ;;
*) echo "$1 не опция" ;;
esac
shift
done
Пример работы программы:
Блок case работает правильно вне зависимости от того, как расположены аргументы командной строки bash.
Выводы
Для того, чтобы сделать свою программу более интерактивной, можно использовать параметры Bash. Встроенные переменные, в названиях которых фигурирует число, обозначают порядок указанных для программы параметров.
Команда basename используется для обрезания пути запущенного сценария, что часто необходимо для создания гибких программ. Использование команды shift позволяет эффективно проходить по переданным скрипту параметрам, особенно когда их количество неизвестно.
При написании сценариев на Bash не только опытные программисты, но и новички в области командного интерпретатора Bash сталкиваются с работой со строками. Наиболее часто это необходимо при считывании команд, вводимых пользователем в качестве аргументов для исполняемого сценария, а также при обработке текстовых файлов. И один из необходимых приёмов в таком случае — это сравнение строк.
В данной статье будет рассмотрено сравнение строк Bash, а также некоторые нюансы по использованию операций сравнения и решению часто встречающихся ошибок.
Сравнение строк Bash
Данные операции позволяют определить, являются ли сравниваемые строки одинаковыми:
= - равно, например if [ "$x" = "$y" ]
== - синоним оператора "=", например if [ "$x" == "$y" ]
!= - не равно, например if [ "$x" != "$y" ]
Пример:
#!/bin/bash
testuser=anton
if [ $USER = $testuser ]
then
echo "Добро пожаловать, $testuser"
fi
Результат работы сценария:
При проверке на равенство с помощью команды test (синоним квадратным скобкам [ ]) учитываются все пунктуационные знаки и различия в регистре букв сравниваемых строк.
Некоторые особенности сравнения строк с шаблонами:
# возвращает истину, если строка, содержащаяся в $x, начинается с символа "y"
[[ $x == y* ]]
# возвращает истину, если строка из $x равна конкретно двум символам "y*"
[[ $x == "y*" ]]
# возвращает истину, если $x содержит название файла, содержащегося в текущем каталоге, которое начинается с "y"
[ $x == y* ]
# возвращает истину, если строка $x равна двум символам "y*"
[ "$x" == "y*" ]
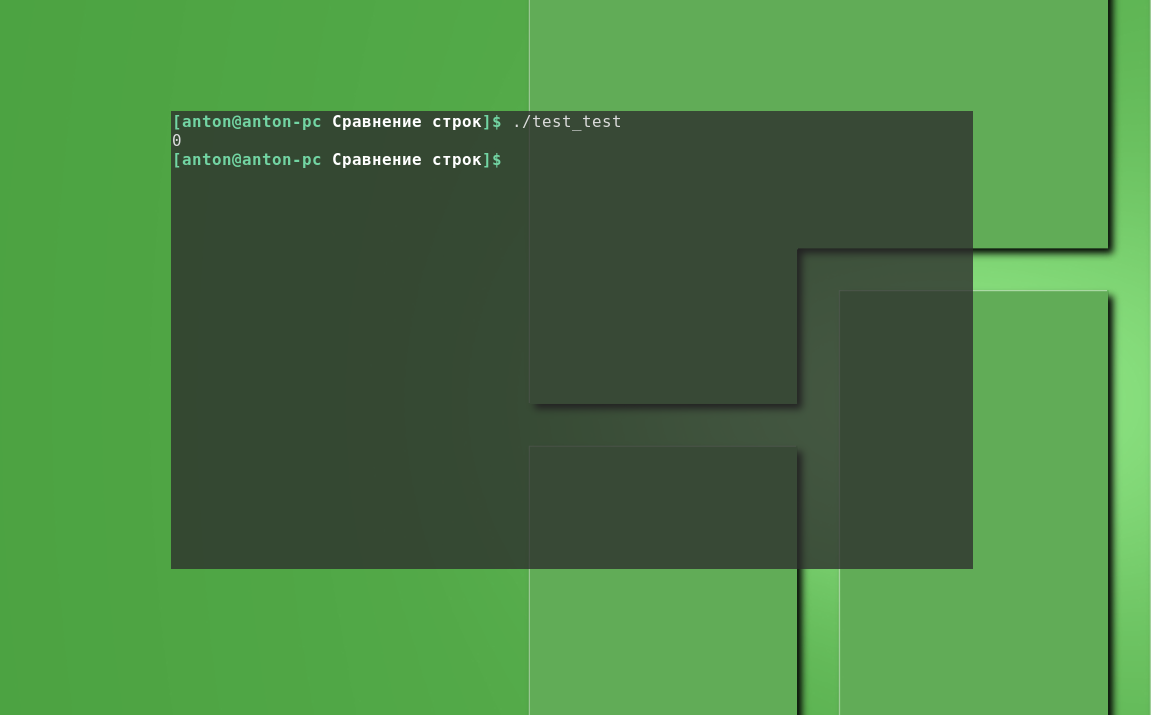
Например проверка строки bash на то, начинается ли она с символа y:
#!/bin/bash
x=yandex
[[ $x == y* ]]
echo $?
Результат выполнения кода:
Сценарий вывел 0 (ноль), так как мы потребовали вывести код ошибки последней выполненной инструкции. А код 0 означает, что сценарий выполнился без ошибок. И действительно — переменная $x содержит строку yandex, которая начинается с символа "y". В противном случае может писаться "1". Это довольно удобный способ отладки сценариев.
Сравнение строк по алфавиту на Bash
Задача усложняется при попытке определить, является ли строка предшественницей другой строки в последовательности сортировки по возрастанию. Люди, пишущие сценарии на языке командного интерпретатора bash, нередко сталкиваются с двумя проблемами, касающимися операций "больше" и "меньше" относительно сравнения строк Linux, у которых достаточно простые решения:
Во-первых, символы "больше" и "меньше" нужно экранировать, добавив перед ними обратный слэш (\), потому что в противном случае в командном интерпретаторе они будут расцениваться как символы перенаправления, а строки — как имена файлов. Это один из тех случаев, когда отследить ошибку достаточно сложно.
Пример:
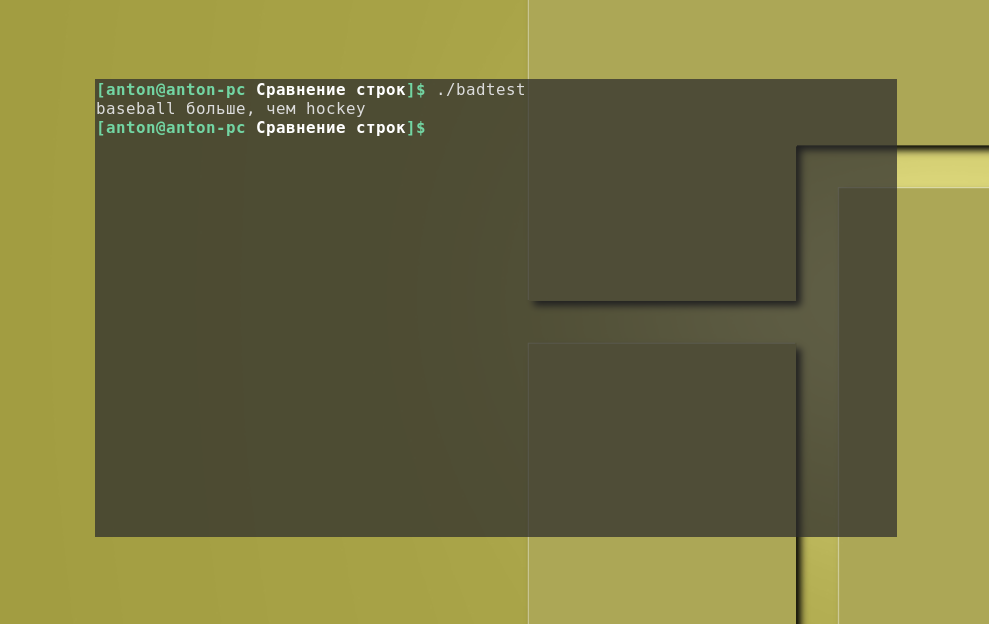
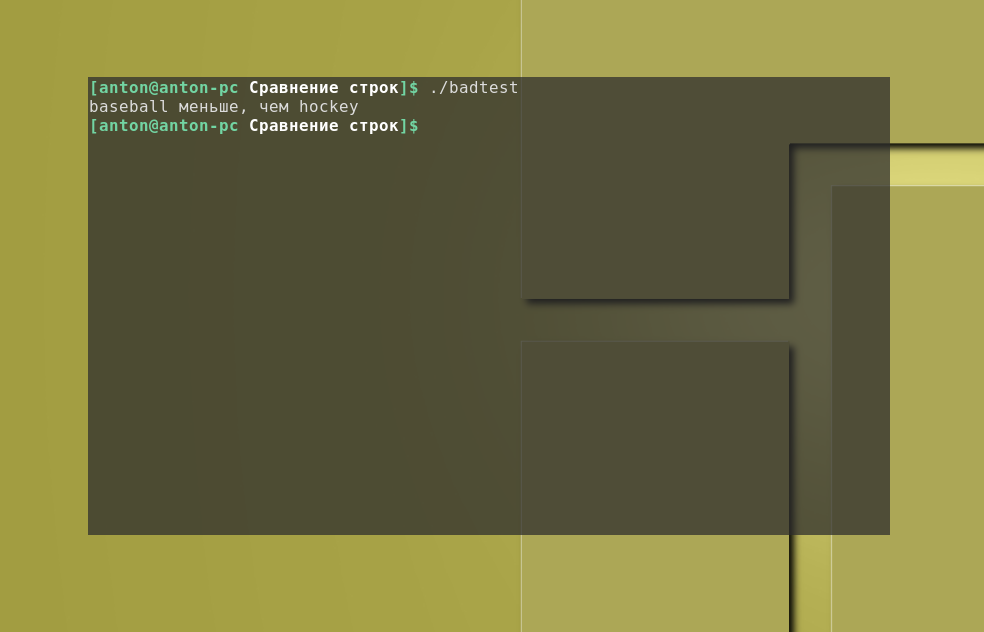
#!/bin/bash
# неправильное использование операторов сравнения строк
val1=baseball
val2=hockey
if [ $val1 > $val2 ]
then
echo "$val1 больше, чем $val2"
else
echo "$val1 меньше, чем $val2"
fi
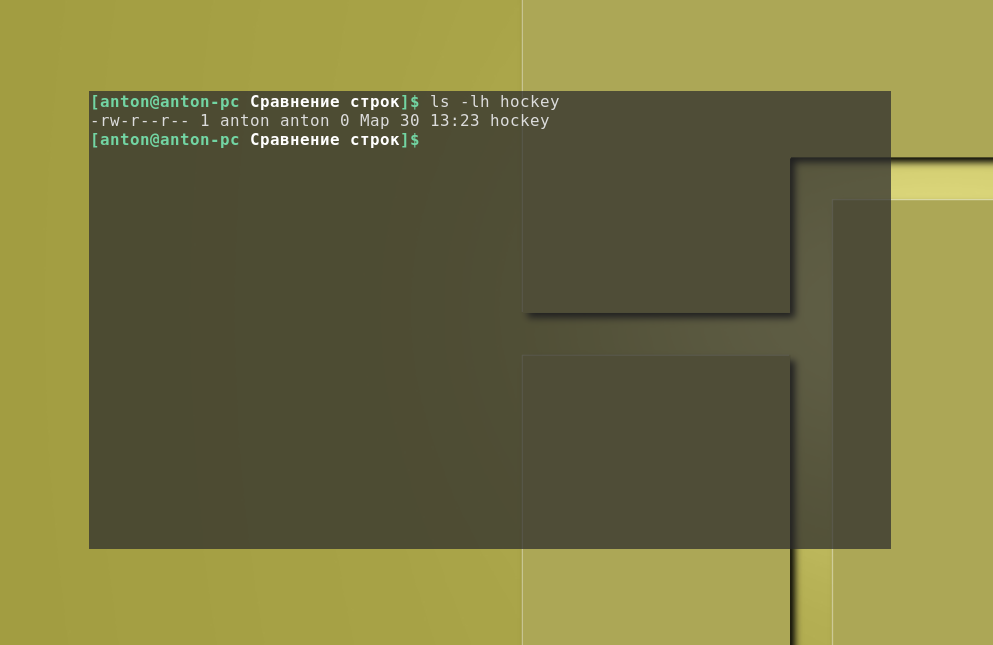
Что получится, если сравнить строки bash:
Как видно, один лишь символ "больше" в своём непосредственном виде привёл к неправильным результатам, хотя и не было сформировано никаких ошибок. В данном случае этот символ привёл к перенаправлению потока вывода, поэтому никаких синтаксических ошибок не было обнаружено и, как результат, был создан файл с именем hockey:
Для устранения этой ошибки нужно экранировать символ ">", чтобы условие выглядело следующим образом:
...
if [ $val1 \> $val2 ]
...
Тогда результат работы программы будет правильным:
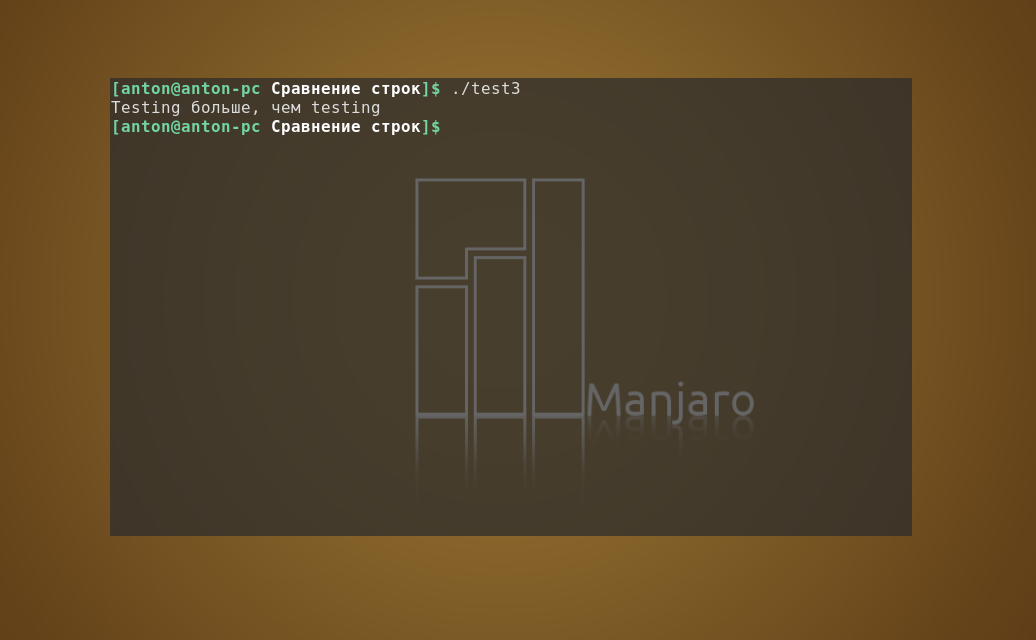
Во-вторых, упорядочиваемые с помощью операторов "больше" и "меньше" строки располагаются иначе, чем это происходит с командой sort. Здесь проблемы сложнее поддаются распознаванию, и с ними вообще можно не столкнуться, если при сравнении не будет учитываться регистр букв. В команде sort и test сравнение происходит по разному:
#!/bin/bash
val1=Testing
val2=testing
if [ $val1 \> $val2 ]
then
echo "$val1 больше, чем $val2"
else
echo "$val1 меньше, чем $val2"
fi
Результат работы кода:
В команде test строки с прописными буквами вначале будут предшествовать строкам со строчными буквами. Но если эти же данные записать в файл, к которому потом применить команду sort, то строки со строчными буквами будут идти раньше:
Разница их работы заключается в том, что в test для определения порядка сортировки за основу взято расположение символов по таблице ASCII. В sort же используется порядок сортировки, указанный для параметров языка региональных установок.
Проверка строки на пустое значение
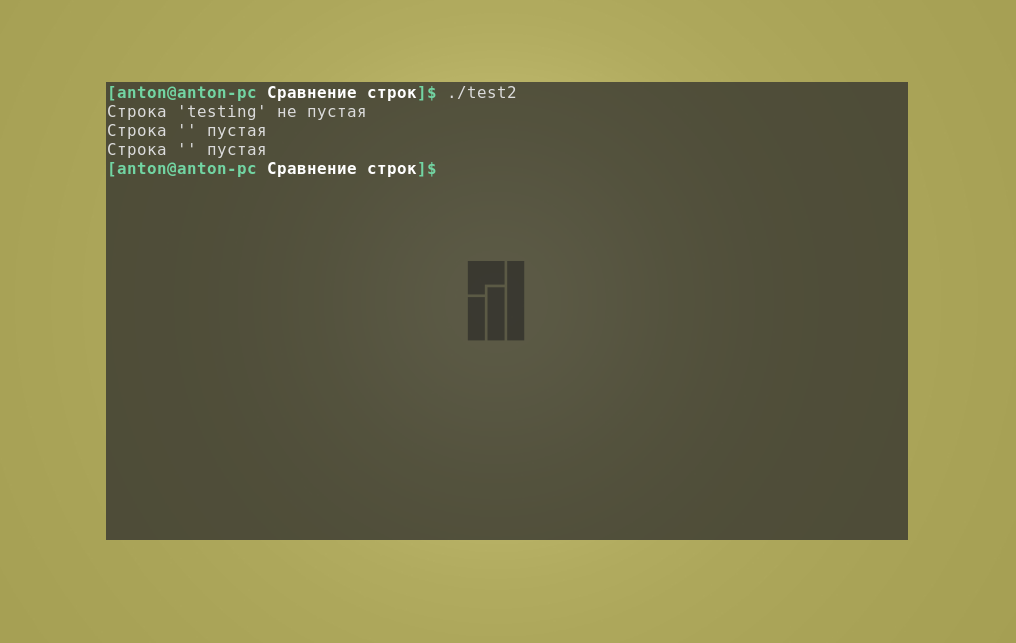
Сравнение с помощью операторов -z и -n применяется для определения наличия содержимого в переменной. Таким образом, вы можете найти пустые строки bash. Пример:
#!/bin/bash
val1=testing
val2=''
# проверяет, не пустая ли строка
if [ -n $val1 ]
then
echo "Строка '$val1' не пустая"
else
echo "Строка '$val1' пустая"
fi
# проверяет, пустая ли строка
if [ -z $val2 ]
then
echo "Строка '$val2' пустая"
else
echo "Строка '$val2' не пустая"
fi
if [ -z $val3 ]
then
echo "Строка '$val3' пустая"
else
echo "Строка '$val3' не пустая"
fi
Результат работы кода:
В этом примере создаются две строковые переменные — val1 и val2. Операция -n определяет, имеет ли переменная val1 ненулевую длину, а -z проверяет val2 и val3 на нулевую. Примечательно то, что последняя не была определена до момента сравнения, но интерпретатор считает, что её длина всё же равна нулю. Такой нюанс следует учитывать при различных проверках сценариев. И, если нет уверенности в том, какое значение содержится в переменной и задано ли оно вообще, стоит проверить её с помощью оператора -n или -z и лишь затем использовать по назначению.
Стоит обратить внимание и на функцию -n. Если ей для проверки будет передана необъявленная или пустая переменная, будет возвращена истина, а не ложь. Для таких случаев следует заключать проверяемую строку (переменную) в двойные кавычки, чтобы выглядело это так:
...
if [ -n "$val1" ]
...
Выводы
В представленных операциях сравнения строк Bash есть определённые нюансы, которые стоит понять для предотвращения ошибок работы сценариев. Но таких ситуаций на практике встречает много, поэтому запомнить все (и тем более, описать) не получится.
При сравнении строк в виде переменных их можно заключать в кавычки практически всегда, так как это считается правилом хорошего тона, а заодно и страхует от семантических ошибок.
Когда-то, уже достаточно давно мне понадобился будильник, достаточно громкий, чтобы поднять мертвого, достаточно разнообразный, чтобы не надоедать и при этом достаточно тяжело выключаемый, чтобы не делать этого "на автомате". Всем этим требованиям отлично соответствовал персональный компьютер и решение этой несложной задачи было найдено при помощи интернет-радио и двух консольных утилит: cron и rtcwake.
Время шло, импровизированный “будильник” великолепно справлялся с задачей, хотя и оставался при этом не самым удобным в плане эксплуатации, все-таки для изменения его приходилось править конфиги, а команду на засыпание вводить в терминал напрямую. Так продолжалось почти год, но совсем недавно один знакомый, недавно перешедший на Ubuntu Linux, попросил рассказать ему о таком чудесном явлении, как командная строка и ее интерпретаторе bash. Поскольку обучение даже самым азам программирование в отрыве от практики по моему глубокому убеждению бесполезно, была написана написана статья, которую я представляю вашему вниманию.
Несмотря на то, что основной целью является все-таки обучение азам работы с bash, скрипт, получающийся в итоге вполне можно использовать и по прямому назначению: то есть в качестве будильника.
Что такое Bash
Одной из самых интересных особенностей операционных систем на базе GNU/Linux является bash. Bash это интерпретатор командной строки, по сути, скриптовый язык программирования, на котором вполне возможно писать достаточно сложные программы, так называемы shell-скрипты или сценарии. Естественно, что на фоне более “серьезных” собратьев по семейству интерпретируемых языков, подобных java или python, функциональность bash смотрится куда более бедно, но зато он плотно интегрирован в саму систему, а это означает, что значительно проще наладить взаимодействие между ним и многими системными утилитами.
Что нам необходимо
С тех заданием все просто: нам необходим простой, надежный, громкий и разнообразный будильник, который сможет поднять мертвеца. И написан он должен быть исключительно на Bash, то есть системными средствами Linux.
Инструменты:
Bash - это, я думаю, понятно любому, интерпретатор командной строки, часть любого Linux - дистрибутива.
rtcwake - встроенный в ядро инструмент, позволяющий использовать драйвер для RTC (Real Time Clock), поддерживающий стандартные флаги для просыпания.
cron - планировщик задач. Уже установлен в большинстве дистрибутивов.
Создание будильника на Bash
Для начала изготовим скрипт, представляющий собой сигнал будильника. Создаем папку wakeupdude (название строго индивидуально и отражает ваше чувство юмора (да, у меня все с ним плоховато) и серьезность отношения к поставленной задаче), в этой папке создаем файл alarm.sh.
Содержимое файла может быть различным, но я решил, что моим будильником будет любимая интернет-радиостанция, поэтому в моем случае все выглядит так:
Сохраняем. Открываем терминал в этой же папке и прописываем:
sudo chmod +x alarm.sh
Вообще, советую запомнить эту команду, поскольку она позволяет, используя терминал присвоить любому файлу любые права доступа ( “+x” означает, что файл отныне будет исполняемым).
В принципе, здесь можно использовать не только интернет-радио, но и запуск музыкальным плеером определенного файла или плей-листа.
Сигнал готов, теперь приступаем к написанию основного скрипта, который будет отвечать за “завод” нашего будильника. Сперва создаем в нашей папке файл wake.sh , в котором записываем следущее:
#! /bin/bash
#Задаем имя первой переменной, отвечающей за дату пробуждения
d=''
#просим ввести эту переменную ( текст внутри кавычек можно изменять по собственному желанию, однако, советую оставить подсказку в скобках, поскольку именно в таком формате необходимо вводить дату, почему объясню чуть ниже)
echo -n "В какой день вас разбудить? (гггг-мм-дд)"
#Просим компьютер считать введенную выше переменную
read d
#вводим следующую переменную,которая будет отвечать за час пробуждения согласно той же схеме
h=''
echo -n "В какой час вас разбудить? (чч)"
read h
# С третьей переменной, отвечающей за минуты пробуждения, будет немного сложнее, поскольку установить одновременно время пробуждения и время срабатывания нашего будильника мы не сможет (не сработает), нам нужно выполнить с ней простое арифметическое действие, поэтому наша следующая переменная должна быть целым числом, а не строкой, как остальные. В этом нам поможет команда declare -i. В остальном, действует точно так же, ка ки с предыдущими переменными.
declare -i m=''
echo -n "Во сколько минут избранного часа вас разбудить? (мм)"
read m
# как я писал выше, просто так взять и назначить время пробуждение и срабатывание будильника на одну и ту же минуту нельзя, поэтому мы укажем компьютеру, что срабатывание будильника должно быть через одну минуту после пробуждения.
declare -i z=0
z=$m+1
#По причине того, что я стремился упростить всю имеющуюся структуру и не усложнять ее лишними конструкциями, в ней имеется один довольно существенный баг: при установке переменной “m”, то есть минутпробуждения на 59, наш будильник не сработает.
#В следующих двух строках выводится отладочная информация, позволяющая еще раз взглянуть на данные, которые мы ввели и еще раз проверить их.
echo "$d $h:$m"
echo "$z"
#даем себе время проверить данные ( в примере 20 секунд)
sleep 20
#теперь преобразовываем понятный нам формат даты в формат, который поймет rtcwake (помните, я говорил, что важно вводить данные именно так, как указано в шаблоне? Так вот, это именно потому, что следующая утилита по-другому их просто не воспримет)
u=$(date +%s -d "$d $h:$m")
#снова отладочная информация, нужная только для того, чтобы понять, что введенные нами данные распознаны успешно.
echo "$u"
#следующая команда вписываетв ремя пробуждение в cron. ВАЖНО!!! ПОМНИТЕ, ПРЕДАСТАВЛЕННАЯ НИЖЕ КОМАНДА СОСТАВЛЕНА ИМЕННО ТАК, ЧТОБЫ ПОЛНОСТЬЮ ПЕРЕПИСАТЬ СОДЕРЖИМОЕ CRONTAB.Это сделано для того, чтобы в нем не скапливалось огромное количество конфликтующих задач. Однако, если вы используете его для других задач, выполняемых, по расписанию, они будут затерты.
echo "DISPLAY=:0
$m $h * * * /home/USERNAME/wakeupdude/alarm.sh" |crontab -
# естественно, что /home/USERNAME/wakeupdude/alarm.sh это путь к вашему файлу, в котором записан ваш сигнал.
#Ну и последняя часть - приказ компьютеру на засыпание.
sudo rtcwake -m mem -t $u
#При исполнении команды компьютер затребует пароль администратора, в принципе, это можно отключить через файл sudoers, но я не советую, поскольку дает нам возможность отказаться от выключения компьютера, если обстоятельства изменились.
Теперь сохраняем файл и с помощью команды chmod +x даем ему права исполняемого. В принципе, наш будильник готов, но, поскольку мы живем в благословенном 2018 году, то каждому уважающему себя приложению нужен ярлык на рабочий стол, то мы его и изготовим:
В нужной папке создадим файл с расширением .desktop, откроем этот файл в редакторе, где и пропишем следующее:
Sublime Text 3 - один из самых распространенных текстовых редакторов для программистов. Он предоставляет своим пользователям уникальные возможности, которых нет больше нигде. Одни из самых главных достоинств - кроссплатформенность и расширяемость.
Здесь можно настроить все - от внешнего вида до компонентов программы (плагинов). Но и уровень настройки у Sublime Text соответствующий - как редактор для программистов, он настраивается через исходный код, что под силу не каждому. В этой статье мы рассмотрим как выполняется настройка Sublime Text 3.
Что такое Sublime Text
Для Sublime Text с первых же версий возможности были гораздо выше, чем у других редакторов. Шутка ли - полностью настраиваемый интерфейс, возможность настроить поведение программы, а не просто вводить текст? Что уж говорить о плагинах - код, написанный на Python, позволяет пользователю управлять редактором так, как укротитель змей, играя на магической дудочке, заставляет гигантского удава трепетать перед ним. Однако, как бы нам ни было жаль, именно это и отпугивает новичков - будучи не в состоянии настроить редактор, они перестают им пользоваться.
Настройка Sublime Text 3
Сначала поговорим про внешний вид, а затем перейдем к настройке горячих клавиш и плагинов.
1. Внешний вид Sublime Text
Итак, пора запустить Sublime Text (статья про установку - тут). Многим дизайн программы нравится, другим же - нет. И сейчас перед вами встает уникальная возможность поменять интерфейс до неузнаваемости!
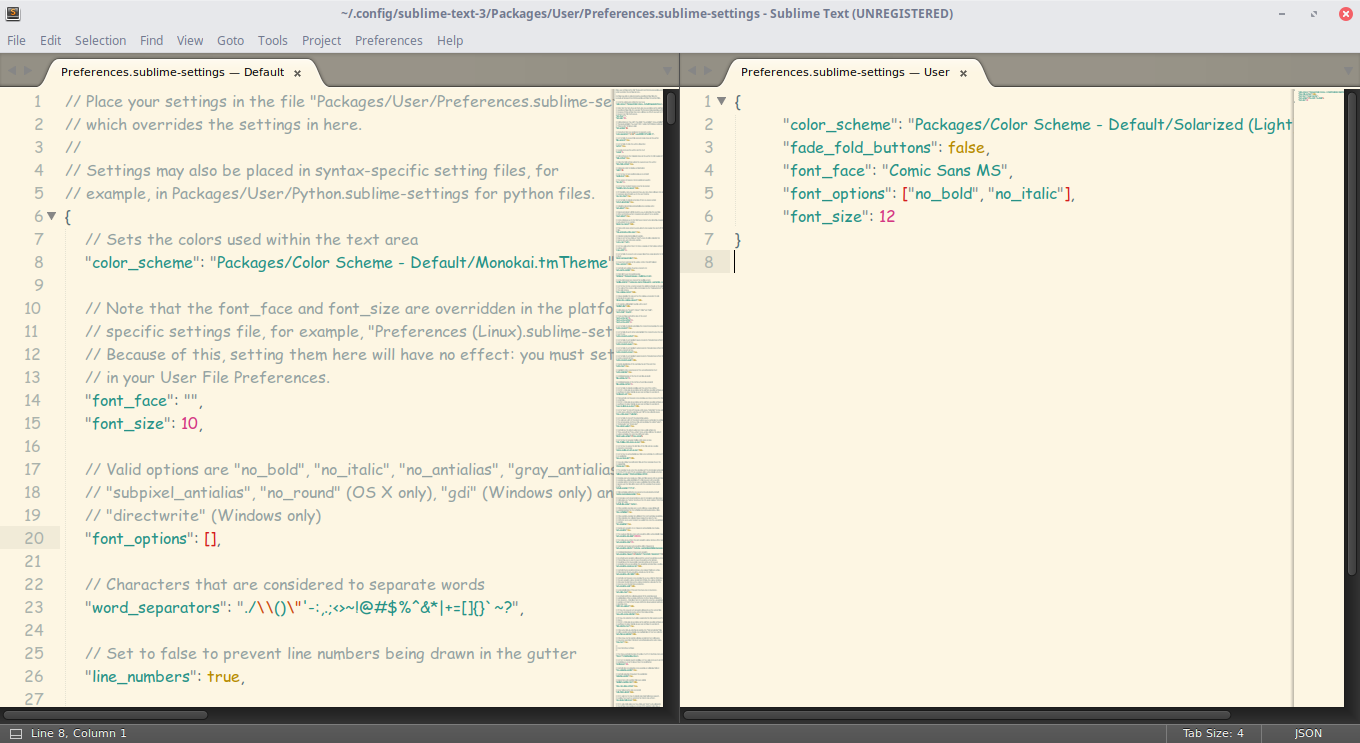
Самый простой с виду способ - выбрать тему через настройки. Для этого идем в меню "Preferences" -> "Color Scheme" и выбираем нужную вам тему. Но это способ лишь поменяет расцветку редактора, и ничего более.
Другой, более сложный, но верный вариант - разобраться с файлом настроек. Чтобы открыть его, перейдите в меню "Preferences" -> "Settings". И вот, перед вами не что иное, как громада текста. Но не все так сложно, как кажется! Слева - настройки по умолчанию, их трогать не надо. Их можно взять за пример. А вот справа нужно разместить свои настройки - взять, скопировать нужную строку и поменять ее значение. Основные настройки:
"color_scheme" - цветовая тема. Можно выбрать из существующих, а можно скачать в папку Packages/Color Scheme - Default/.
"font_face" - шрифт текста. Важно, чтобы он был в системе. Чтобы посмотреть список доступных шрифтов, откройте любой текстовый редактор, к примеру, Lible Office Writer.
"font_size" - размер шрифта, устанавливающийся дробным или целочисленным значением.
"font_options" - дополнительные опции шрифта типа "no_bold", "no_italic".
"word_separators" - разделители слов.
"line_numbers" - настройка нумерации строк.
"gutter" - отображать ли "канавку" (в ней располагаются номера строк и закладки).
"margin" - длина отступа от "канавки".
"fold_buttons" - если навести курсор на "канавку", то будут видны треугольные стрелки, позволяющие скрыть или показать фрагмент кода между фигурными скобками. Их тут можно отключить или включить.
"fade_fold_buttons" - если поставить значение false, то треугольные кнопки не будут скрываться.
Вот пример действия настроек (не забудьте сохранить файл):
Вы можете поэкспериментировать здесь сами. А мы идем дальше.
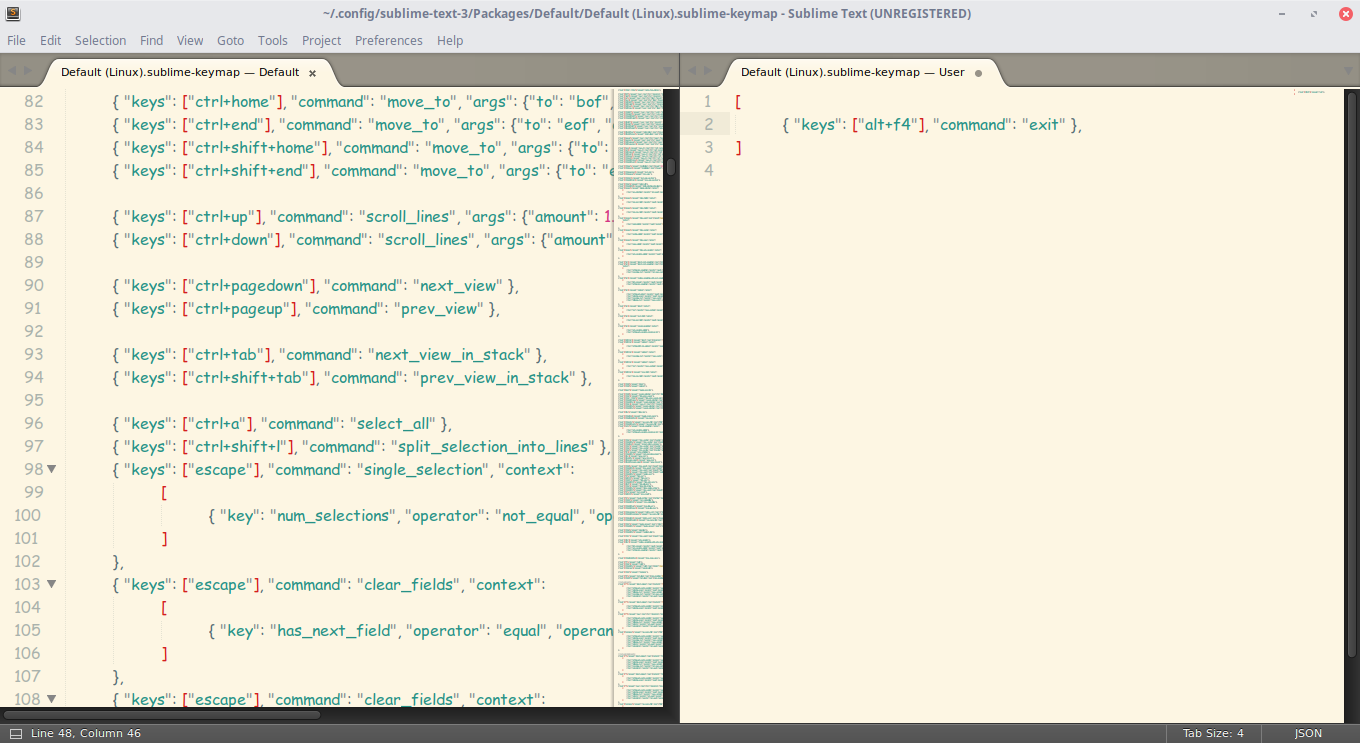
2. Настройка сочетаний клавиш
Да-да, вы не ослышались! Любой может настроить сочетания по-своему, присвоив им другие значения. Чтобы открыть файл, перейдите в "Preferences" -> "Key Bindings".
Перед нами снова два файла, один из которых - настройки по умолчанию, а другой - ваши персональные настройки. Чтобы поменять сочетание, необходимо скопировать одну или несколько строк, заключенных между фигурными скобками. Вот пример моего файла:
Конечно, это ничего не меняет (это сочетание клавиш для закрытия любого приложения), однако данный файл является лишь примером.
Ну вот и все, Sublime Text стал таким, каким он вам нужен и вы знаете как настроить Sublime Text 3. А сейчас пора двигаться дальше - к установке плагинов.
3. Установка Package Control
Как уже говорилось ранее, редактор имеет возможность добавления плагинов, будь то собственные или скачанные с сайта разработчика. Однако, несмотря ни на что, установка плагинов вручную не очень удобна, и поэтому нужно скачать и установить дополнительный компонент.
Package Control - предназначен для более быстрой и удобной установки плагинов. Он позволяет устанавливать их через визуализированный интерфейс, а не через код.
Для начала установим Package Control с официального сайта. Это не значит, что мы его будем скачивать!
Скопируем текст из соответствующего текстового поля (в зависимости от версии Sublime Text).
С помощью сочетания клавиш "Ctrl + ~" вызываем встроенную в редактор консоль (да-да, есть и такое!).
Вставляем скопированный код в текстовое поле и ждем успешной установки.
Перезапускаем редактор.
Package Control установлен! Теперь пора разобраться с тем, как им пользоваться.
4. Работа с плагинами в Package Control
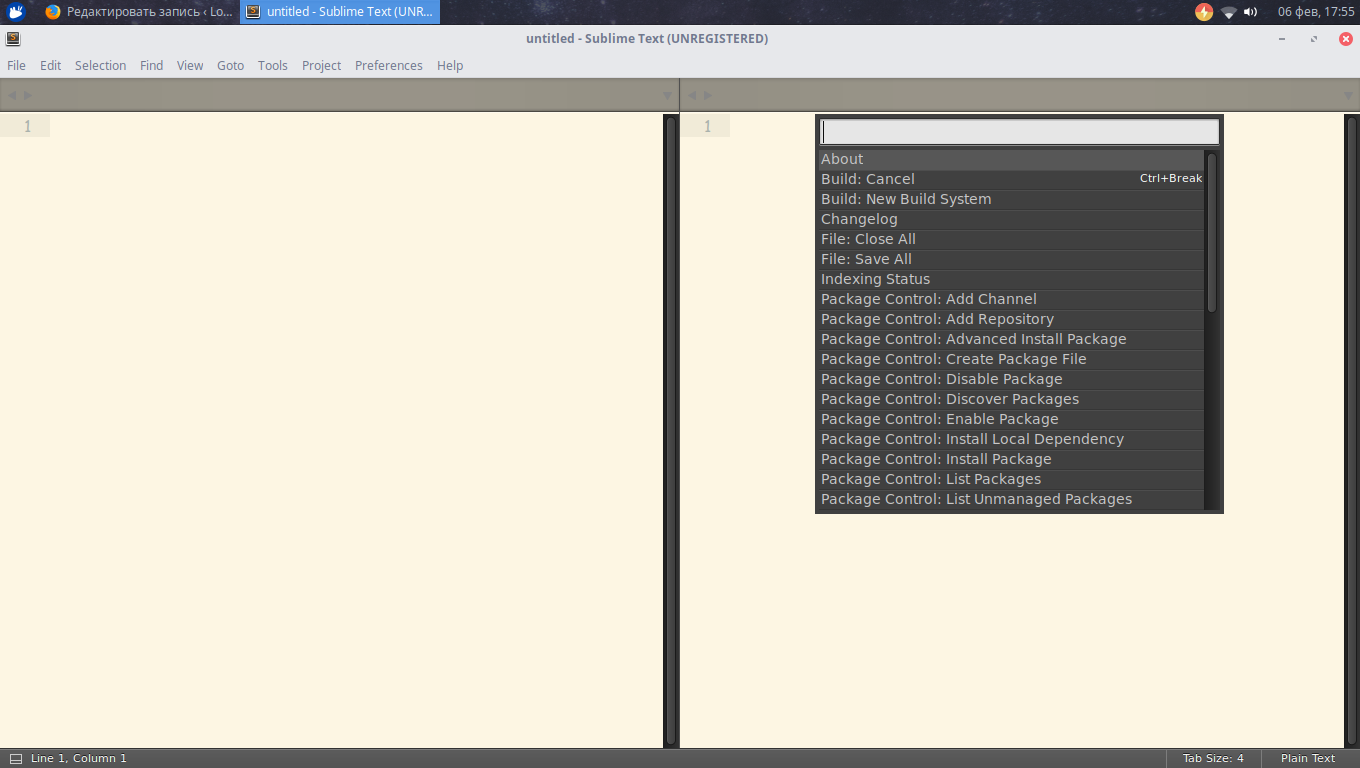
Чтобы запустить Package Control, необходимо набрать сочетание клавиш "Ctrl + Shift + P" и из списка выбрать элемент Package Control: Install Package.
И перед нами долгожданная установка плагинов! Теперь есть возможность быстрого их поиска и выбора, а если выбрать другие команды для Package Control, то можно и удалять, и изменять элементы редактора. Теперь надо потренироваться на установке. Уставноим Material Theme и выполним настройки темы sublime text 3.
Запускаем установщик плагинов.
Набираем в поле поиска Material Theme.
Нажимаем и ждем, внизу должна появиться надпись "Installing package Material Theme". В процессе установки будет запрошено добавление еще одного плагина, разрешаем.
Чтобы применить тему, необходимо перейти в меню "Preferences" -> "Color Scheme" -> "Material Theme" -> "schemes", а далее - тема, которая вам больше всего понравится.
Однако это еще не все. Несмотря на установку темы в качестве плагина, она активируется не до конца. Чтобы исправить это, зайдите в файл настроек и допишите следующий текст:
Неплохо, да? Настройка Sublime Text 3 почти завершена. А сейчас пора установить что-нибудь более существенное. Давайте ознакомимся с самыми популярными плагинами для Sublime Text.
Топ 5 плагинов для Sublime Text 3
1. Emmet
Emmet - плагин, позволяющий сделать отображение кода более удобным. Здесь используются сочетания клавиш. К примеру, "html + tab" создает каркас документа, а "div.wrapper + tab" превратится в полноценный код:
<div class="wrapper"></div>
2. JavaScript & NodeJS Snippets
Этот плагин представляет собой коллекцию сокращений снипсетов для JavaScript. Длина набираемого текста с помощью подсказок правда уменьшается! К примеру, вместо набора "document.querySelector('selector’);" можно просто набрать "qs + Tab".
3. Advanced New File
Зачем искать место для нового файла в неудобном дереве каталога? Данный плагин позволит быстро и эффекстивно ввести нужные данные, и файл будет создан буквально за пару нажатий клавиш!
4. Git
Название этого плагина говорит само за себя: вы сможете выполнять все необходимые действия в рамках Git'а, не выходя из редактора!
5. GitGutter
Этот плагин позволит пользователю не только обращаться с обычными командами Git, но и работать с изменением версий: отлавливать их, просматривать, сравнивать - и все в режиме реального времени.
Выводы
Как писать код - дело каждого. Но есть удобные вещи, которые доступны всем, и нет смысла от них отказываться! Такие редакторы, как Sublime Text, особенно важны веб-разработчикам. А пока вы можете настроить редактор под себя сами - пусть это станет ВАШ собственный Sublime Text, в который вы вложили частичку собственной души. Удачи!
С каждым годом становится все больше операционных систем, и потому разработчикам все труднее удовлетворять потребности пользователей. Три самые популярные компьютерные платформы - Windows, Linux и Mac OS, а также три мобильные - Android, iOS и Windows Mobile - продолжают активно бороться между собой. А это значит, что качественное приложение должно работать на всех основных платформах.
Справиться с этой проблемой помогает кроссплатформенная разработка. Об одной из самых популярных кроссплатформенных сред разработки - Qt Creator - и пойдёт речь в этой статье. Мы рассмотрим как выполняется установка и настройка Qt Creator, а также как работать в Qt Creator.
Что такое Qt Creator
Qt Creator (не так давно имевший название Greenhouse) - это одна из самых распространенных кроссплатформенных IDE. Ее плюсы - удобство, быстрота работы, а также - свободность, так как это ПО с открытым исходным кодом. Поддерживаются такие языки, как C, С++, QML.
Программа была написана компанией под названием Trolltech, которая в полной мере выполнила цель создания среды - работу с графическим фреймворком Qt. Удобный графический интерфейс с поддержкой Qt Widgets и QML, а также большое число поддерживаемых компиляторов позволяют быстро и удобно создать свое кроссплатформенное приложение.
Главная задача этой IDE - обеспечить наиболее быструю кроссплатформенную разработку, используя собственный фреймворк. Благодаря этому разработчики получают прекрасную возможность не писать приложения нативно (т. е. отдельно под каждую платформу), а создать общий код, и, возможно, подогнать его под особенности используемых ОС.
Qt Creator также включает в себя утилиту Qt Designer, что позволяет обработать внешний вид окна приложения, добавляя и перетаскивая элементы (аналогично Windows Forms в Visual Studio). В качестве систем сборки используются qmake, cmake и autotools.
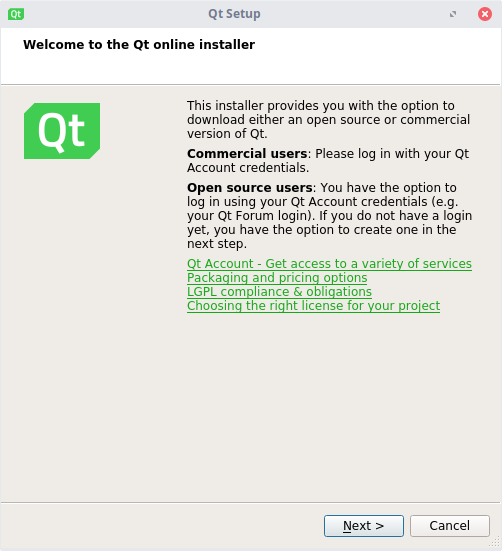
Установка Qt Creator
Итак, пора рассмотреть как установить Qt Creator. Если для Windows разработчики позаботились и сделали оффлайн-установщик, то в Linux 32-bit этой возможности не предусмотрено. Поэтому во время установки вам может потребоваться стабильное интернет-соединение (~20-30 минут). Для начала скачаем установщик:
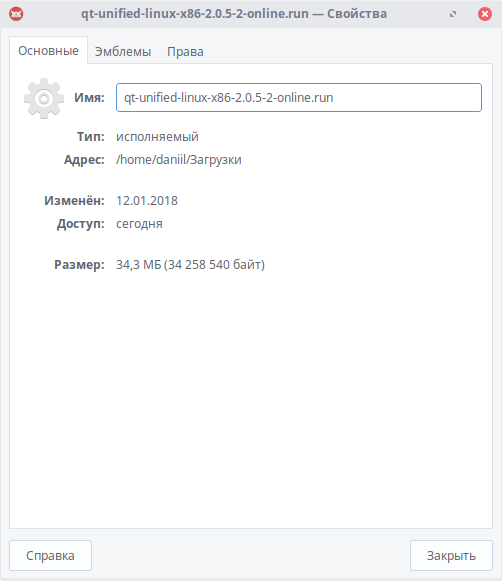
После окончания загрузки переходим в папку с файлом, нажимаем правой кнопкой мыши и выбираем пункт "Свойства".
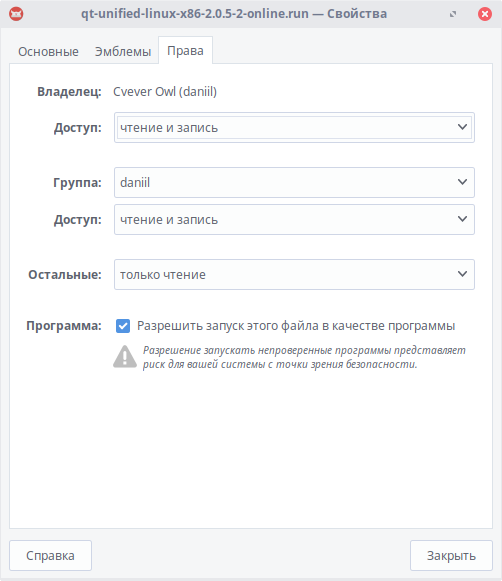
Теперь перейдем на вкладку "Права" и поставим галочку "Разрешить запуск этого файла в качестве программы".
Запускаем программу.
Теперь нажимаем "Next".
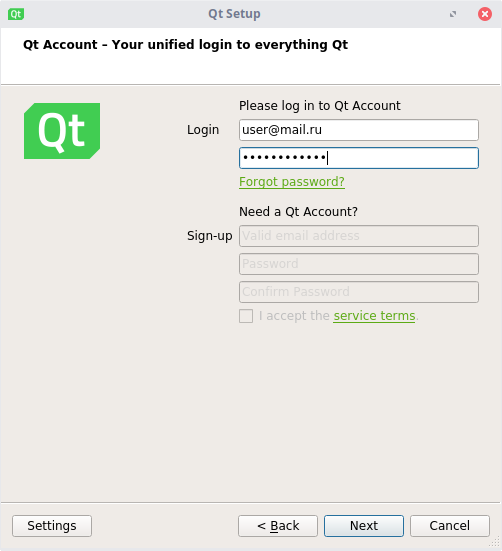
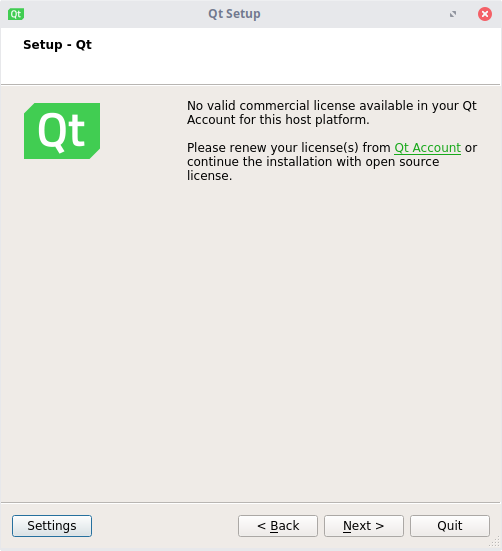
Здесь необходимо выбрать существующий аккаунт или создать его. Данное действие необходимо для проверки лицензии (коммерческой или некоммерческой).
Нажимаем "Next".
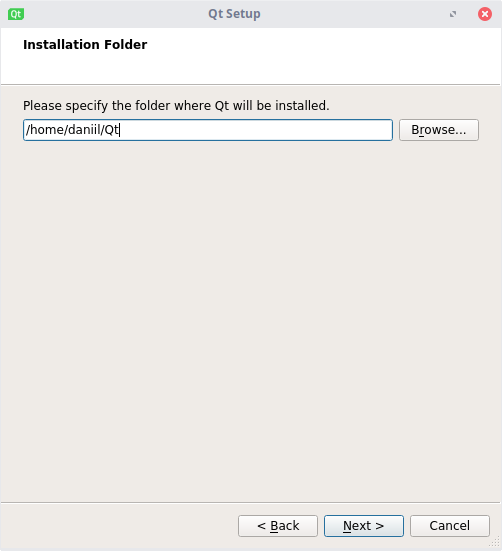
Выбираем директорию, в которой будет находиться Qt. Важно, чтобы в пути не было кириллицы и пробелов!
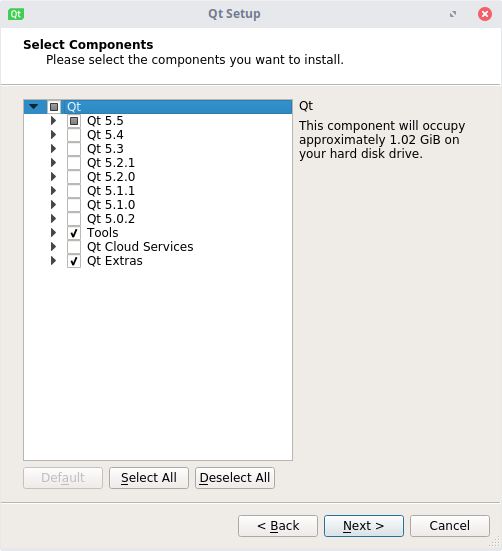
В этом меню находится выбор компонентов. К примеру, можно выбрать установку инструментов для разработки на Android, или же исходных компонентов (это нужно для статической сборки, если кому-то это нужно - напишите в комментариях, и я напишу отдельную статью). Если Вы не уверены, нужны Вам эти компоненты или нет, оставьте их пока так - даже после установки Qt будет возможным удаление и добавление элементов.
В этом окне принимаем лицензию. Жмем "Next".
Если Вы готовы, начинайте установку. У Вас запросят пароль суперпользователя (sudo), после чего начнется скачивание и извлечение файлов. Альтернативный способ - установка через терминал. Для начала необходимо обновить список пакетов.
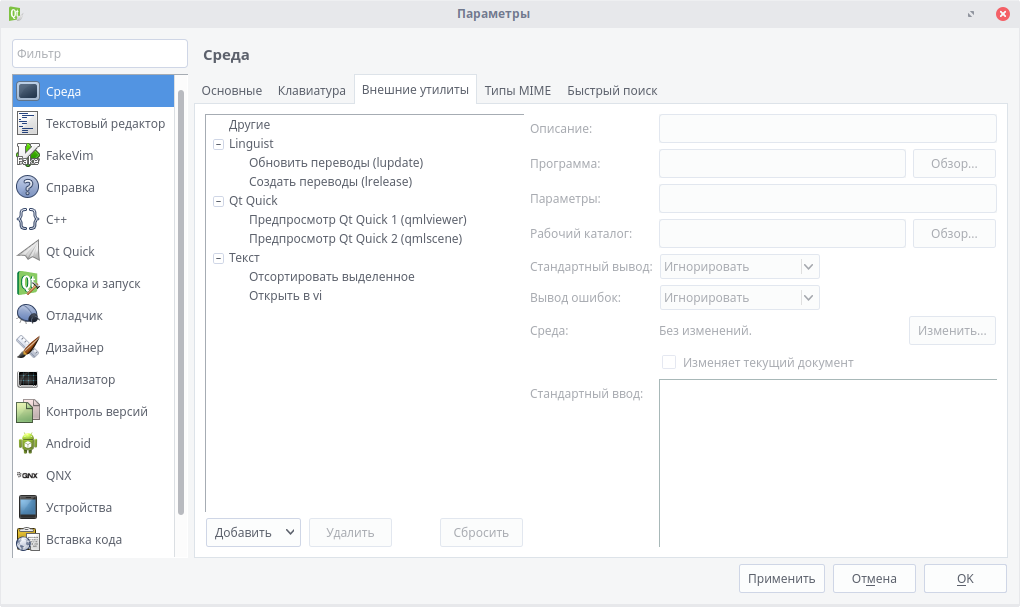
После окончания установки перезагрузите компьютер и запустите Qt Creator. Перейдите в меню "Инструменты" -> "Параметры".
Здесь следует рассмотреть несколько вкладок.
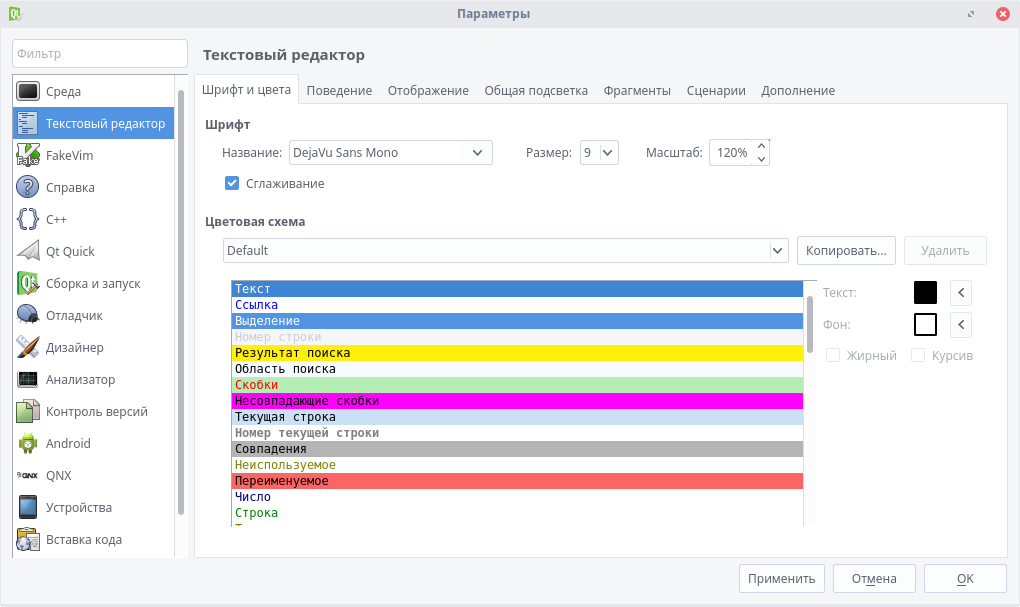
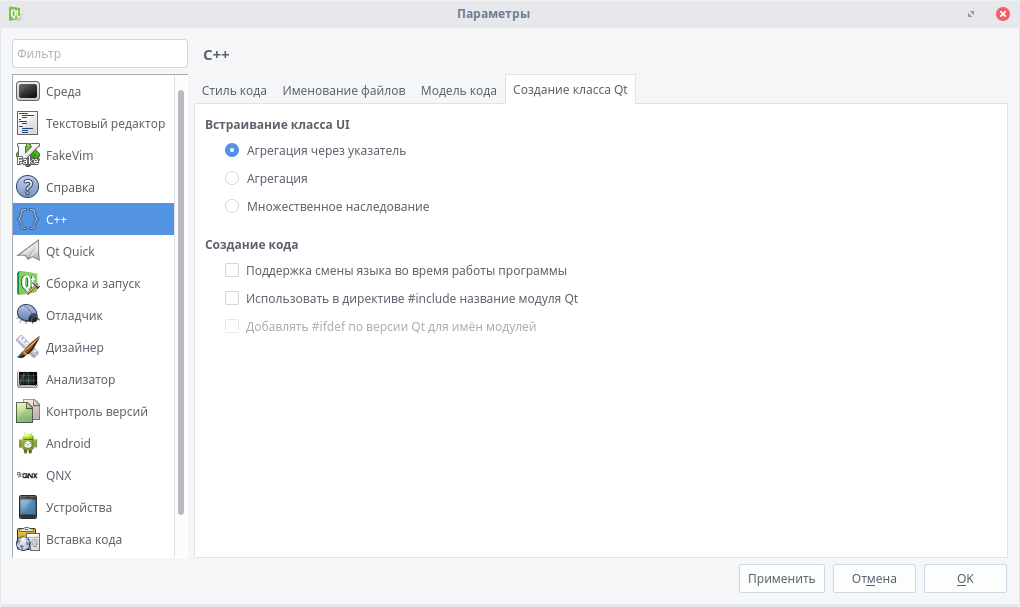
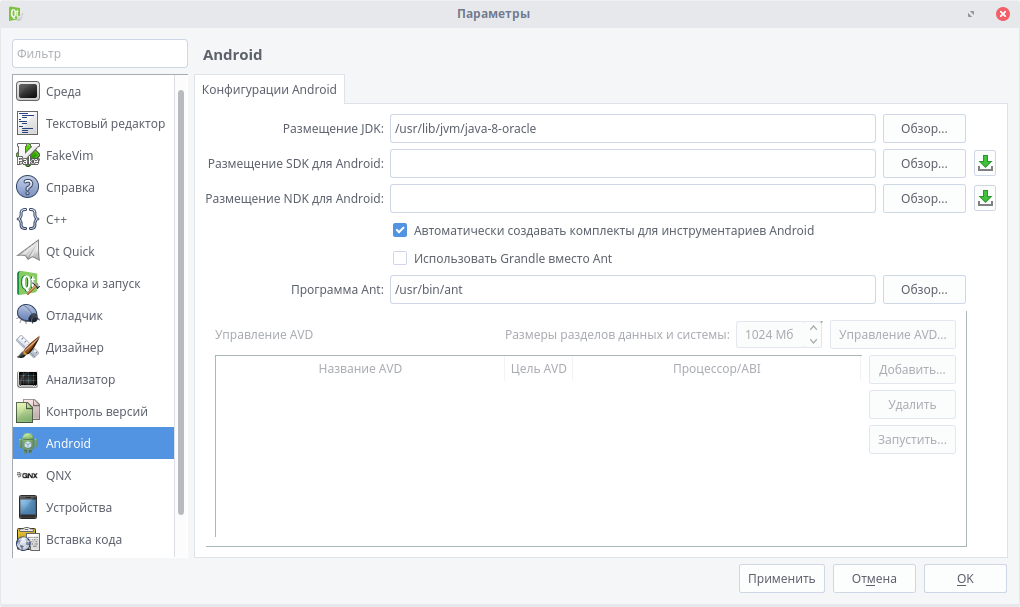
1. Среда - это настройка внешнего вида самой IDE, а также изменение сочетаний клавиш и управление внешними утилитами.
2. Текстовый редактор - здесь идет настройка внешнего вида, шрифтов и расцветки редактора.
3. C++ - подсветка синтаксиса, работа с расширениями файлов и UI (т. е. формами).
4. Android - здесь собраны пути к необходимым инструментам, а также в этом меню настраиваются подключаемые или виртуальные устройства.
Установка компонентов Qt Creator
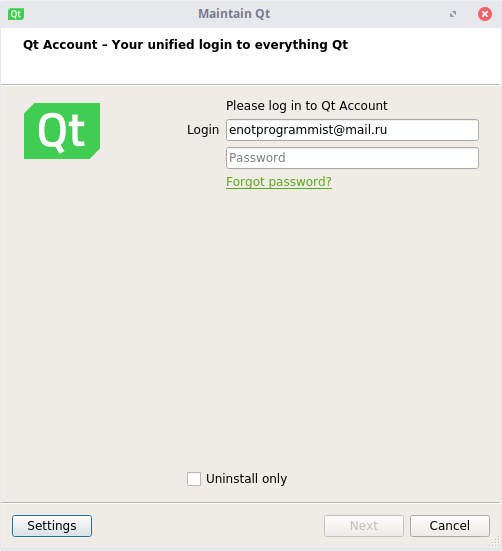
Если вдруг так случилось, что Вы забыли установить какой-то компонент, или, наоборот, хотите его удалить, то на помощь придет Qt Maintenance Tool. Это инструмент, позволяющий управлять всеми компонентами Qt Creator.
Чтобы запустить его, перейдите в меню приложений, выберите пункт "Разработка" -> "Qt Maintenance Tool".
Выберите необходимый пункт (Удалить/добавить компоненты, обновить компоненты или удалить Qt). После выполните необходимые операции и закройте окно.
Работа с Qt Creator - первый проект
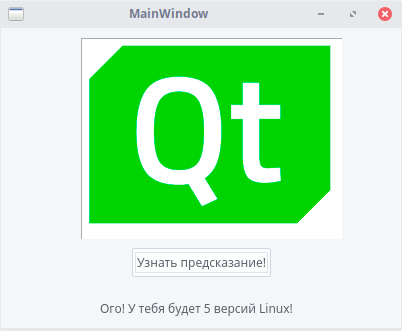
Ну что же, час пробил! Установка Qt Creator завершена. Пора сделать свое первое кроссплатформенное приложение на Linux, а затем скомпилировать его на Windows. Пусть это будет... программа, выводящая иконку Qt, кнопку и надпись, на которую по нажатию кнопки будет выводиться случайная фраза. Проект несложный, и, конечно же, кроссплатформенный!
Для начала откроем среду разработки. Нажмем "Файл" -> "Создать файл или проект...". Выберем приложение Qt Widgets - его быстро и удобно сделать. А название ему - "Cross-Platphorm". Вот как!
Комплект - по умолчанию. Главное окно тоже оставляем без изменений. Создаем проект.
Для начала необходимо настроить форму - главное окно приложения. По умолчанию оно пустое, но это не останется надолго.
Перейдем в папку "Формы" -> "mainwindow.ui". Откроется окно Qt Designer:
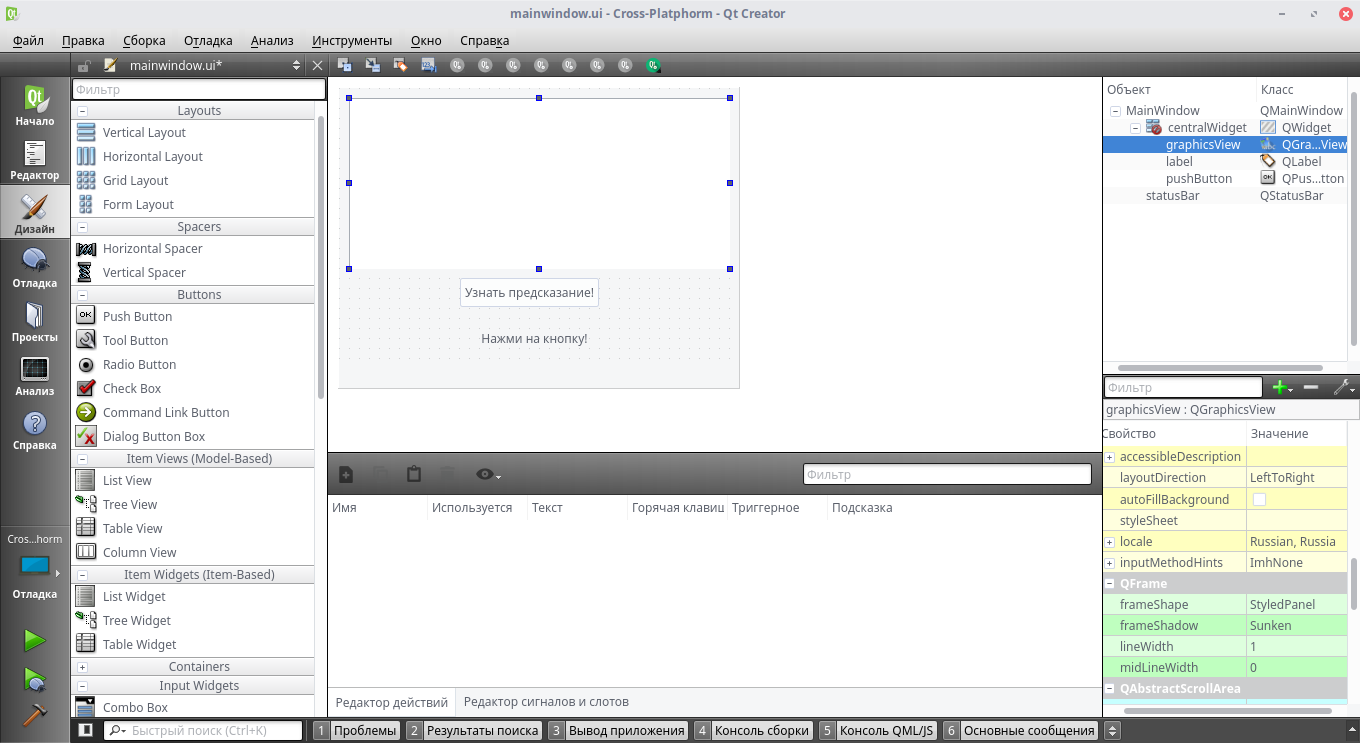
Удаляем панель меню и панель инструментов на форму, нажав правой кнопкой мыши и выбрав соответствующий пункт. Теперь перетаскиваем элементы Graphics View, Push Button и Label таким образом:
Чтобы изменить текст, дважды кликните по элементу. В свойствах Label (справа) выбираем расположение текста по вертикали и по горизонтали - вертикальное.
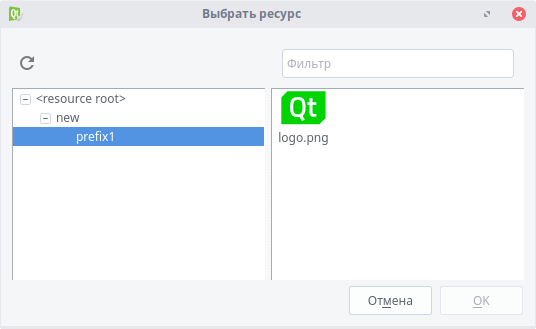
Теперь пора разобраться с выводом иконки. Перейдем в редактор, слева кликнем по любой папке правой кнопкой мыши и выберем "Добавить новый...". Теперь нажимаем "Qt" -> "Qt Resource File". Имя - res. В открывшемся окне нажимаем "Добавить" -> "Добавить префикс", а после добавления - "Добавить файлы". Выбираем файл, а в появившемся окне "Неверное размещение файла" кликаем "Копировать".
Получилось! Сохраняем все. Снова открываем форму. Кликаем правой кнопкой мыши по Graphics View, выбираем "styleSheet..." -> "Добавить ресурс" -> "background-image". В левой части появившегося окна выбираем prefix1, а в правой - нашу картинку. Нажимаем "ОК". Настраиваем длину и ширину.
Все! Теперь можно приступать к коду. Клик правой кнопкой мыши по кнопке открывает контекстное меню, теперь надо нажать "Перейти к слоту..." -> "clicked()". В окне набираем следующий код:
Или вы можете скачать полный проект на GitHub. Работа с Qt Creator завершена, нажимаем на значок зеленой стрелки слева, и ждем запуска программы (если стрелка серая, сначала нажмите на значок молотка). Запустилось! Ура!
Выводы
Установка и настройка Qt Creator завершена. Теперь вы сможете создавать свои программы под огромное число платформ, оставляя код нетронутым! Кстати, установив Qt на Windows, вы сможете скомпилировать этот проект и там. Удачи вам!
Язык программирования Go или как его еще называют Golang, это относительно новый язык от корпорации Google, который по своим возможностям стремится заменить Си и С++. Он создан одним из разработчиков Си и здесь уже были учтены все ошибки, допущенные при создании того языка. Go имеет улучшенную безопасность, мультипоточность, полностью кросплатформенен и многое другое. На Go можно даже писать приложения для Android.
В этой статье мы рассмотрим как выполняется установка Go в Ubuntu 20.04 и более поздних версиях. Рассмотрим установку компилятора с официального сайта или PPA, а также запустим небольшую программу чтобы проверить как все работает. Читать далее Установка Go в Ubuntu 20.04→